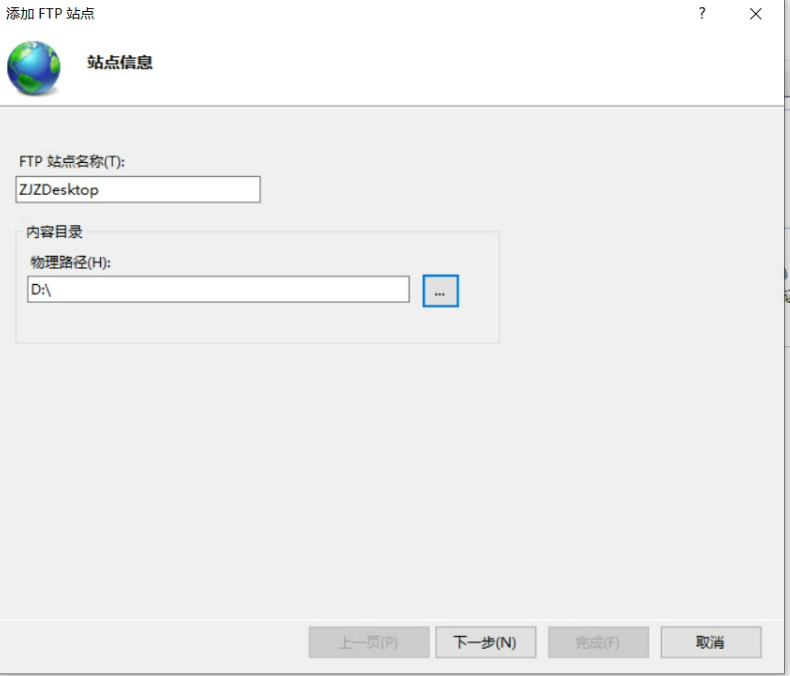
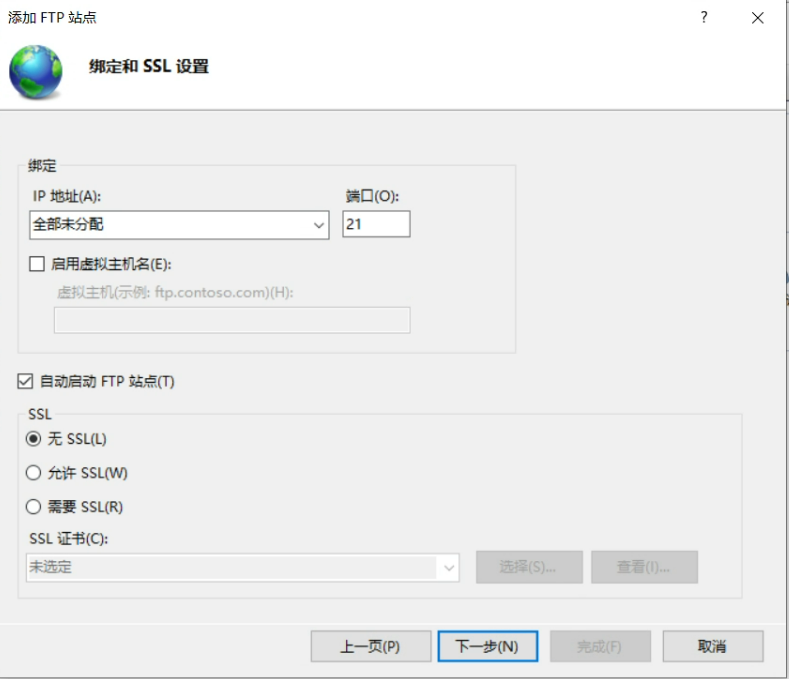
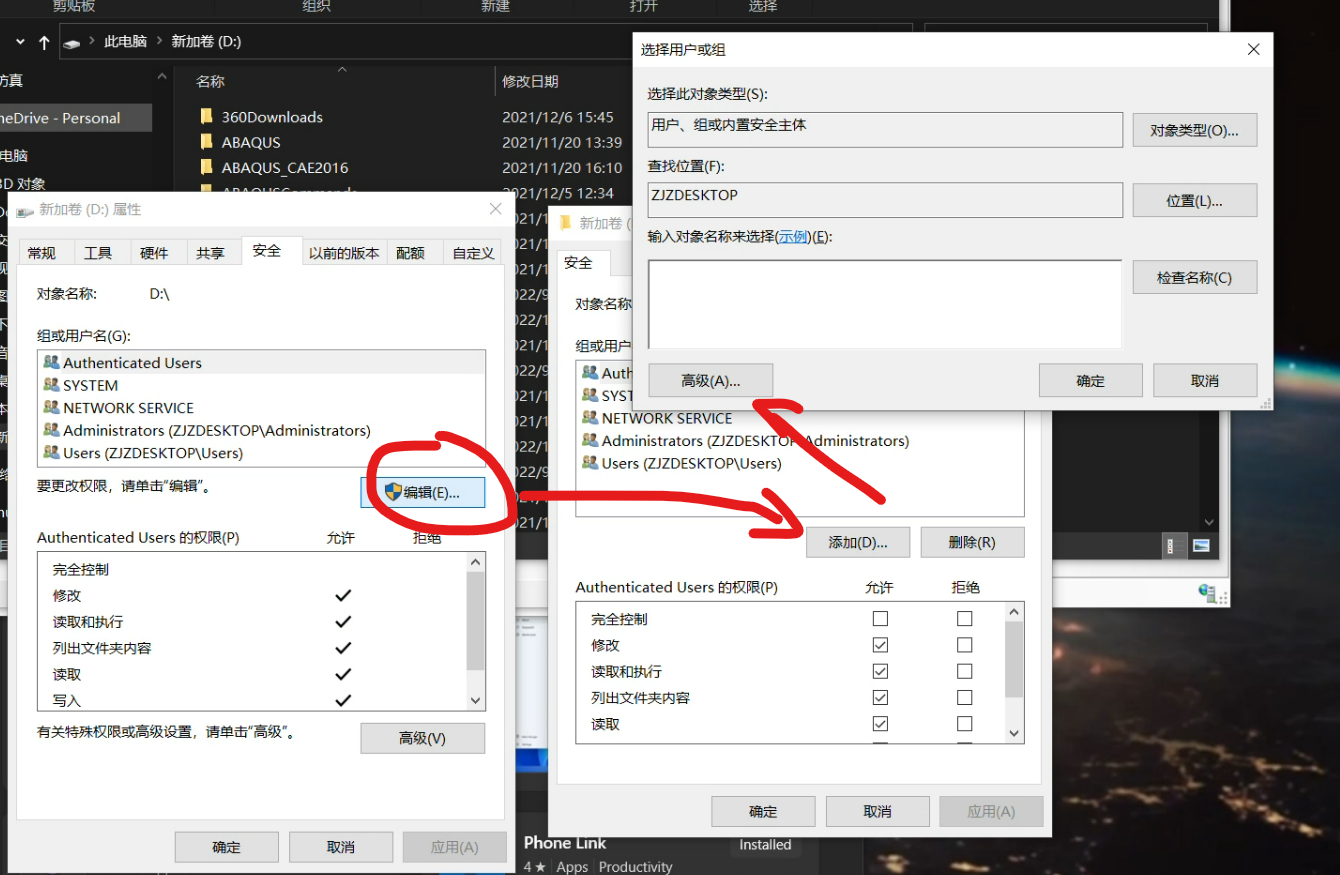
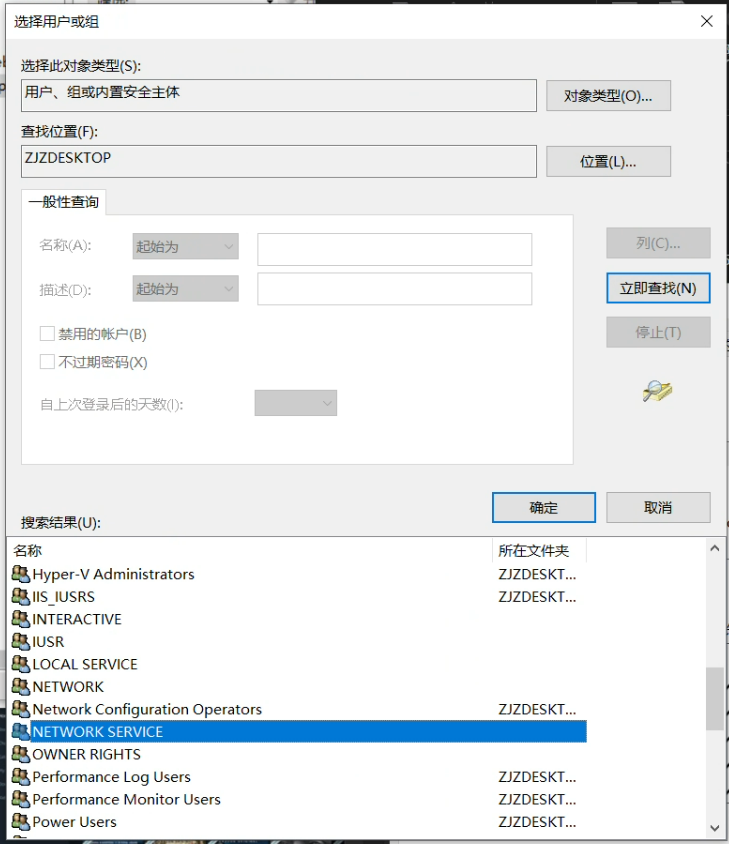
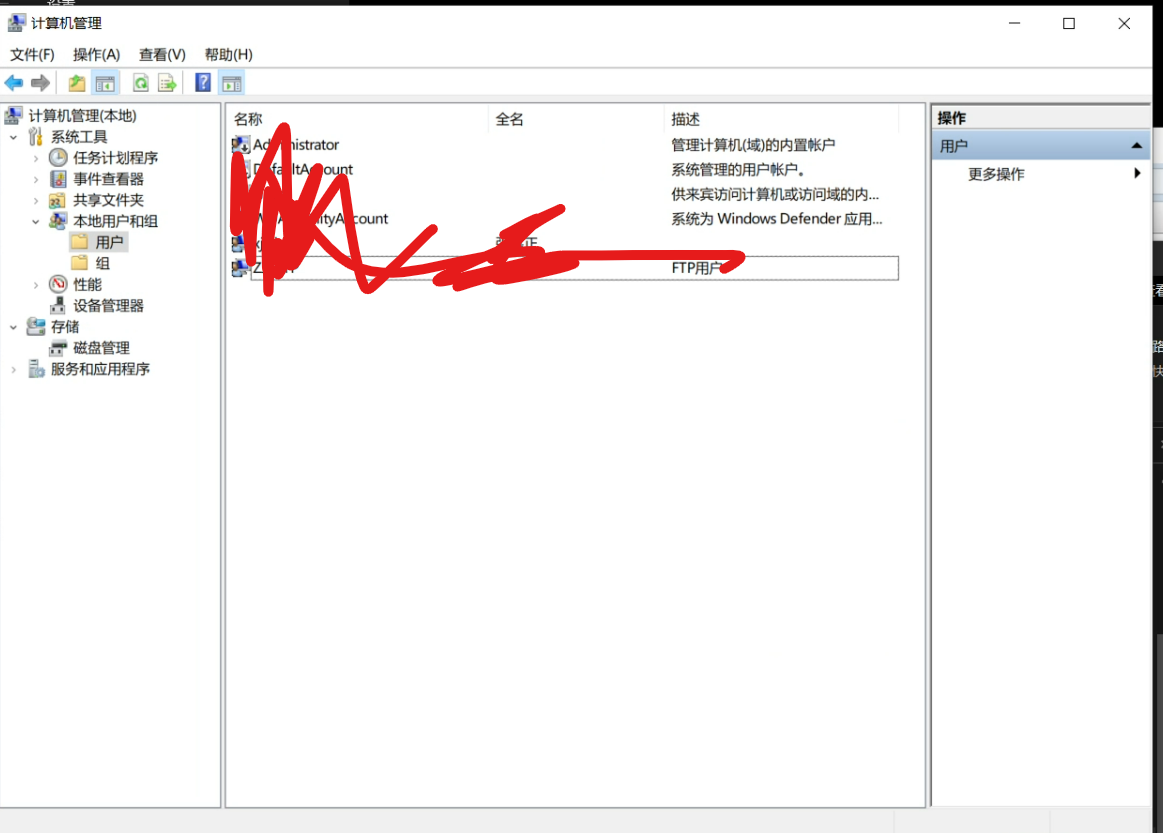
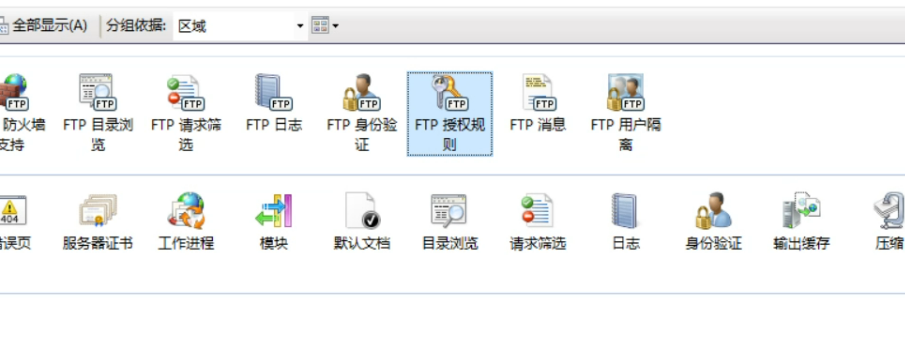
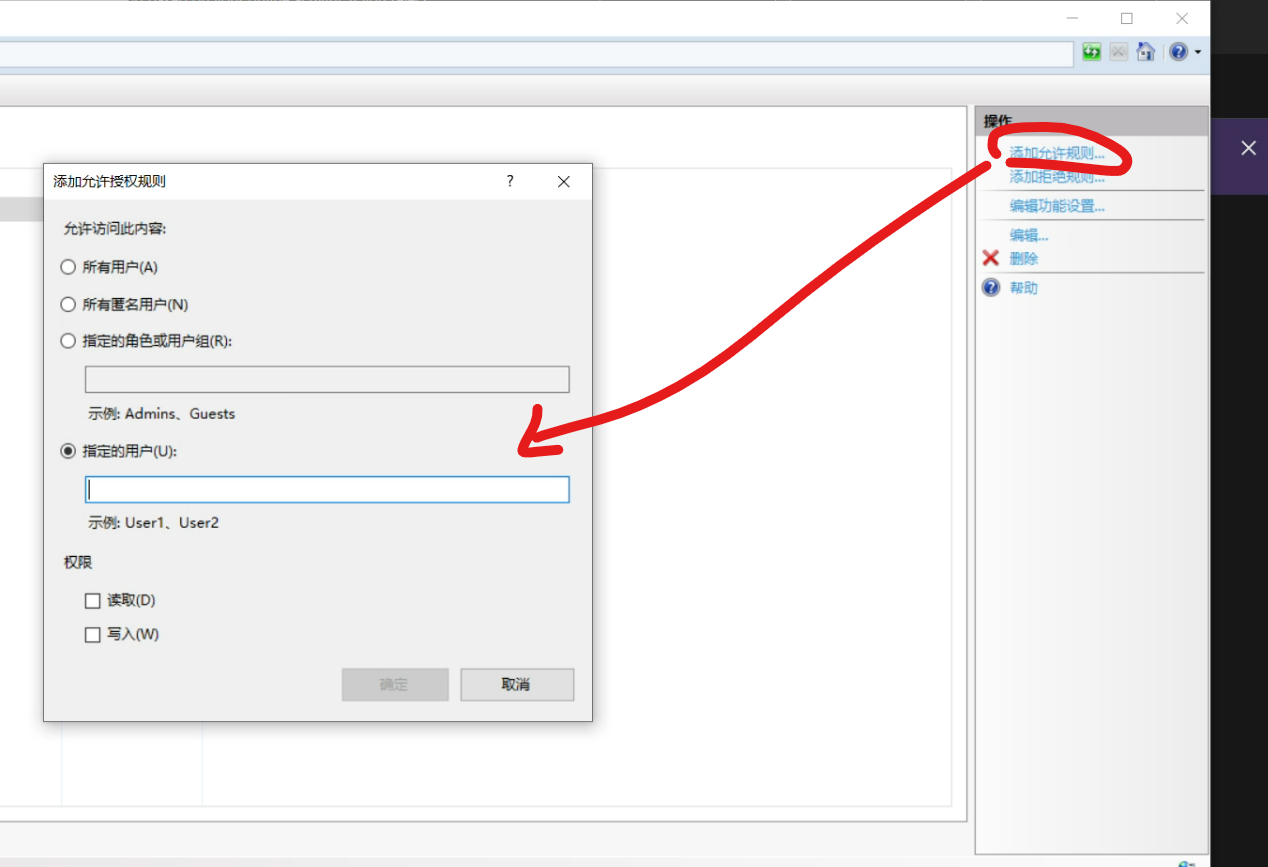
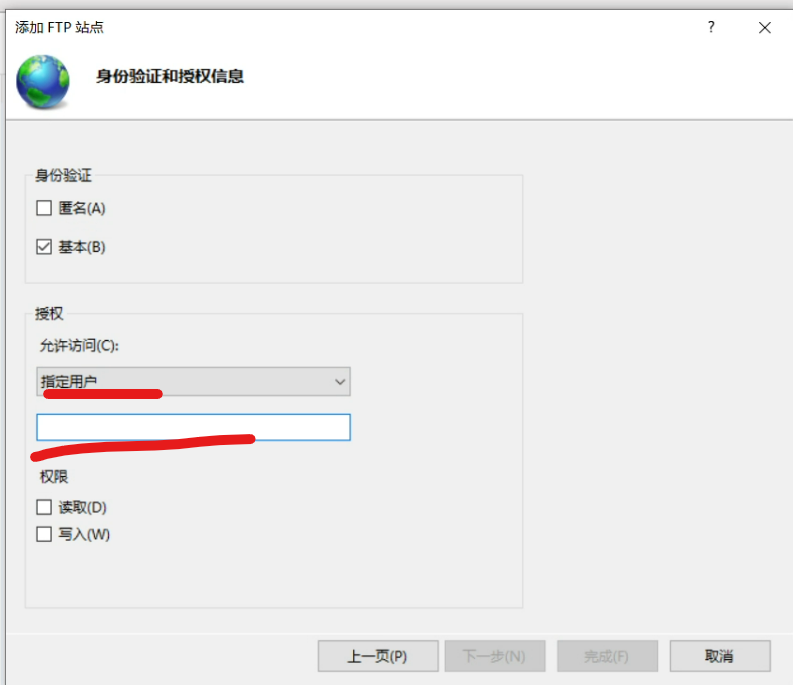
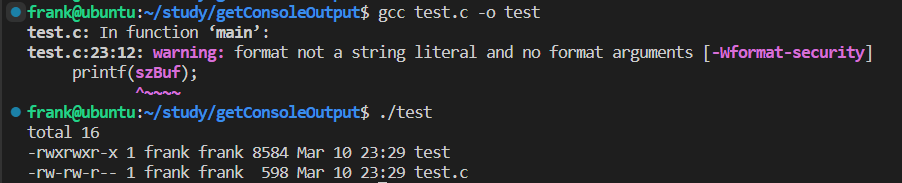
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
char *argv[] = {"ls", "-l", NULL, NULL};
int pipe_fd[2];
char buffer[256];
char routeBuf[256];
FILE* pipeWrite;
getcwd(routeBuf, 256);
argv[1] = routeBuf;
pipeWrite = fdopen(pipe_fd[1], "w");
printf(argv[1]);
printf("\n");
memset(buffer, 0, 256);
printf("pipe return: %d\n", pipe(pipe_fd));
int pid = fork();
if (pid > 0)
{
wait();
close(pipe_fd[1]);
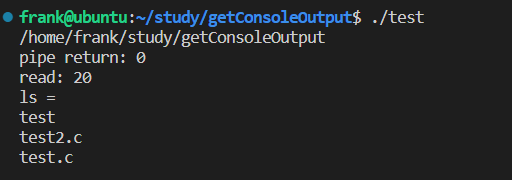
printf("read: %d\n", read(pipe_fd[0], buffer, 256));
printf("ls = \n%s\n", buffer);
}
else
{
close(pipe_fd[0]);
dup2(pipe_fd[1], STDOUT_FILENO);
execlp(argv[0], argv[0], argv[1], argv[2]);
fflush(pipeWrite);
}
}
|





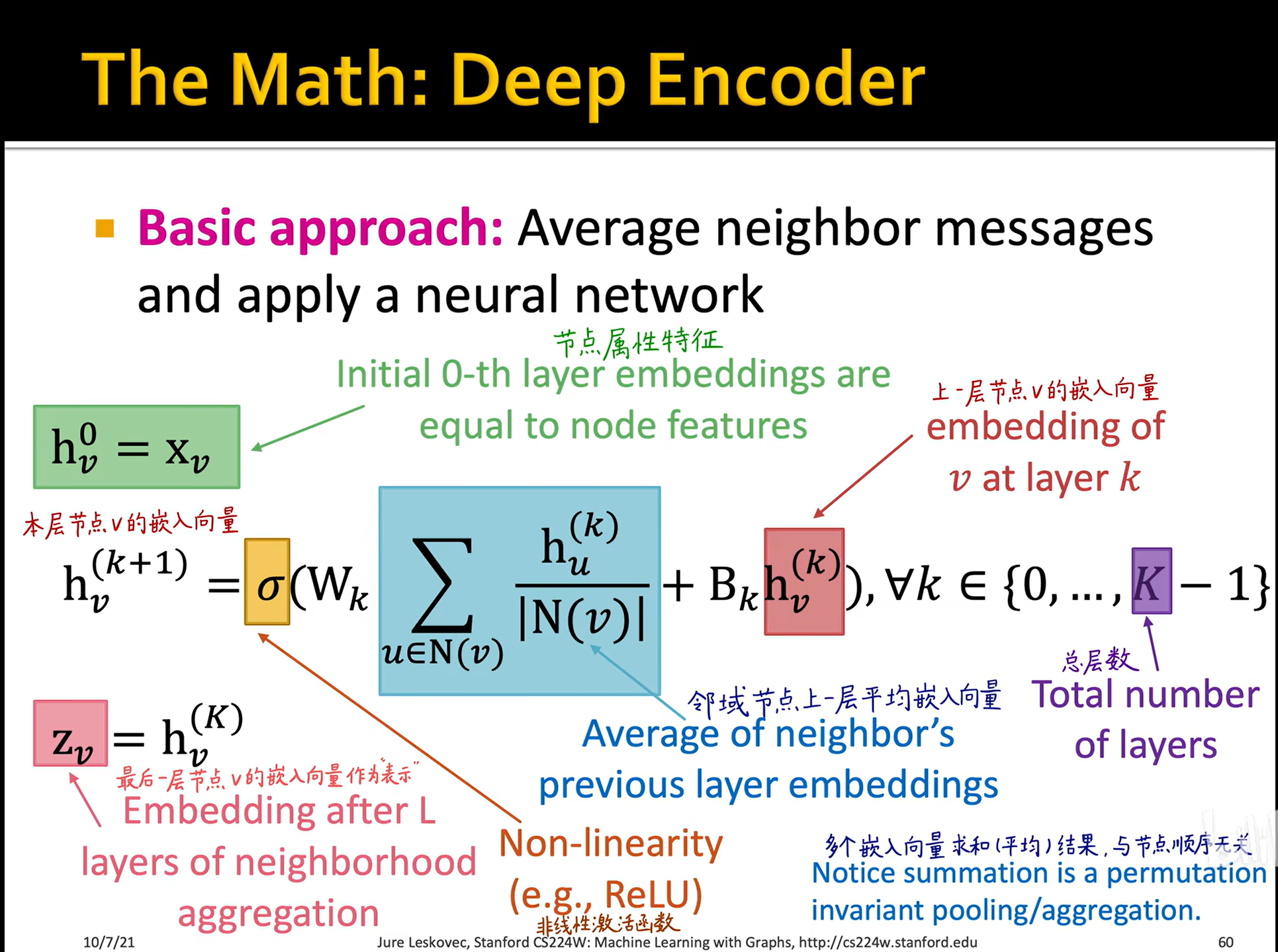


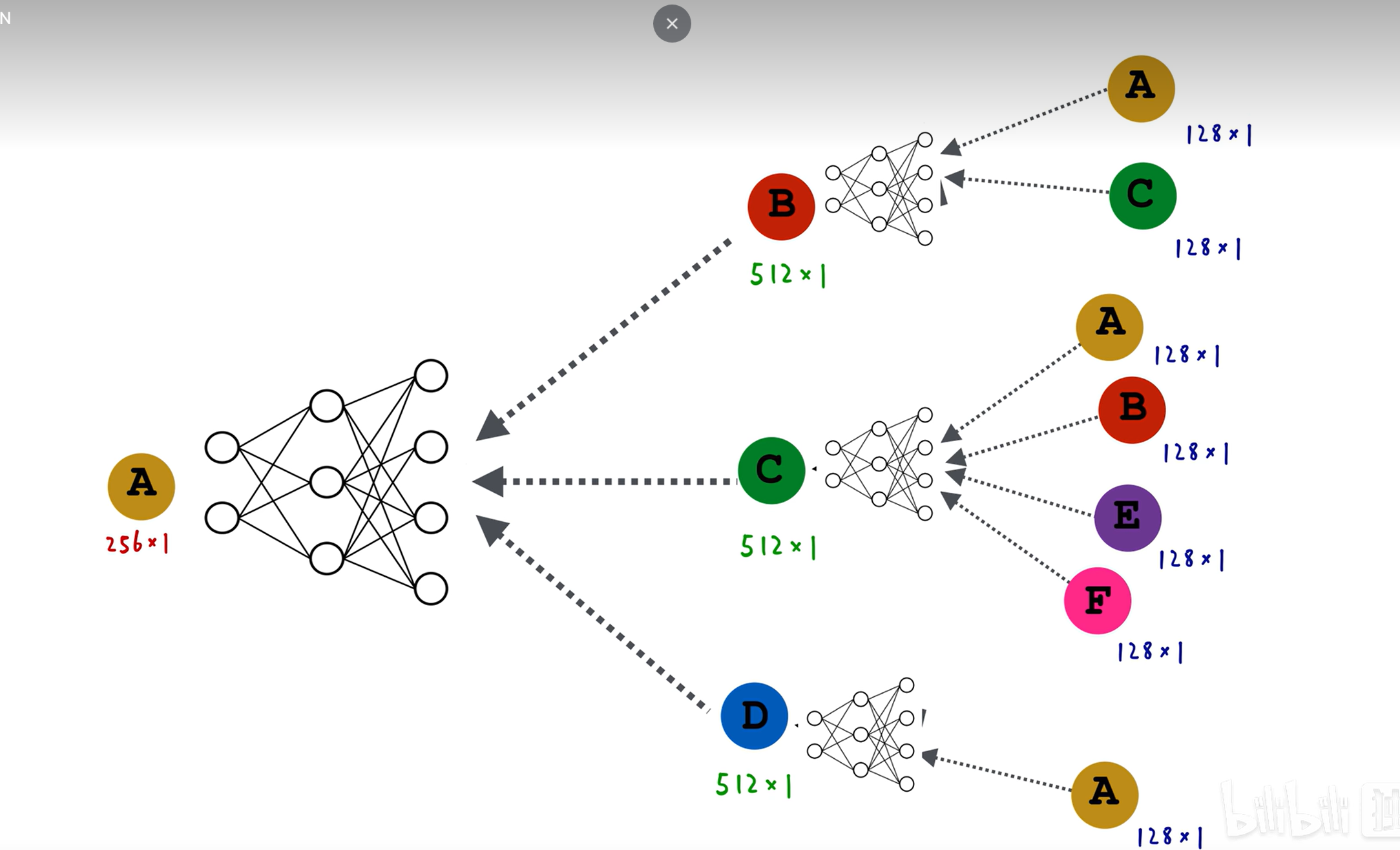
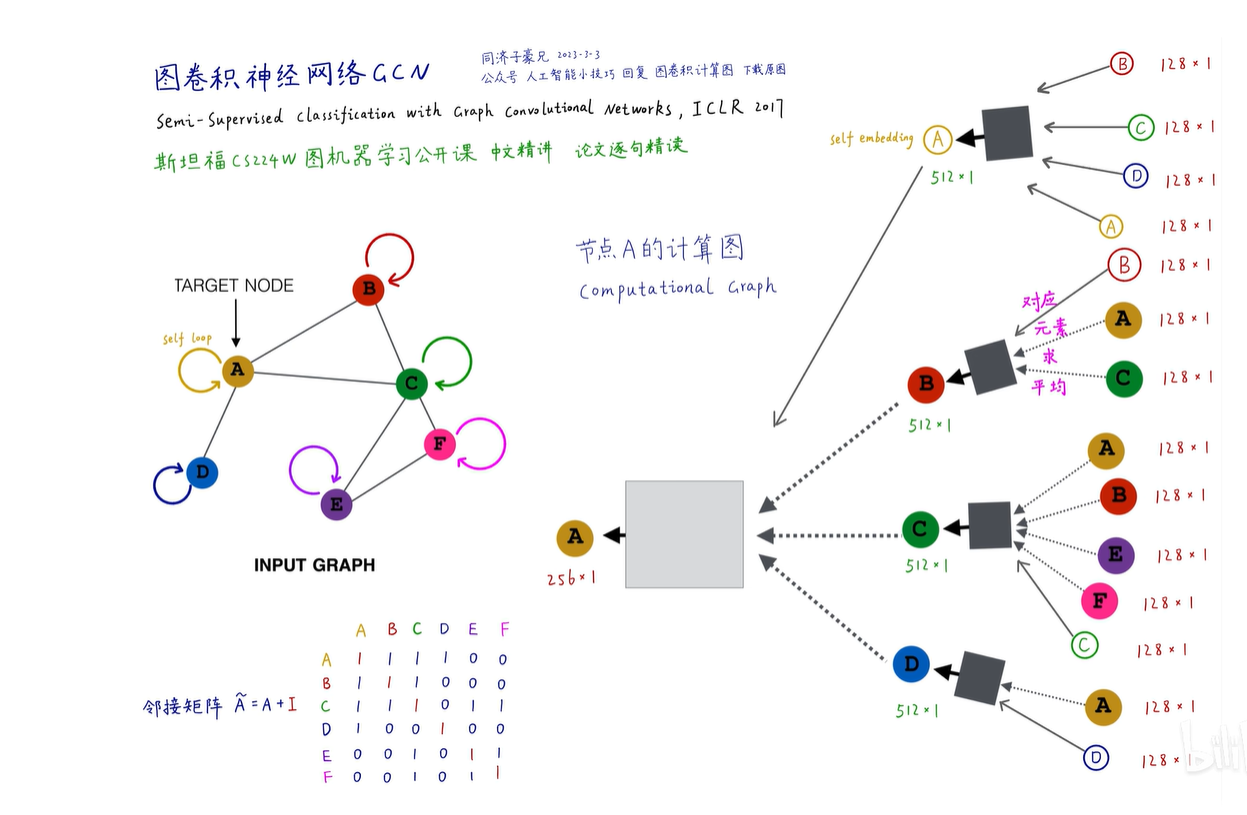
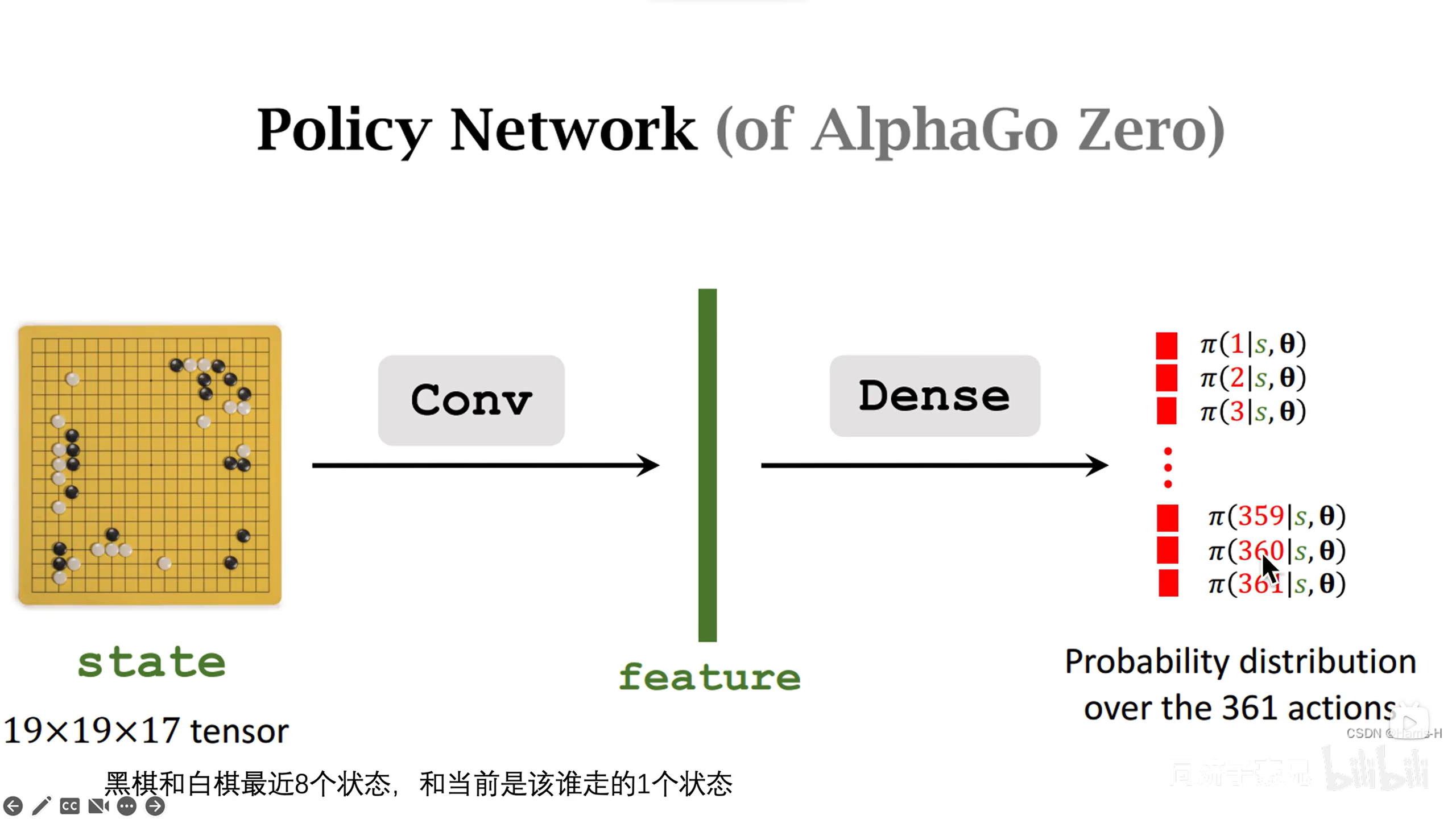
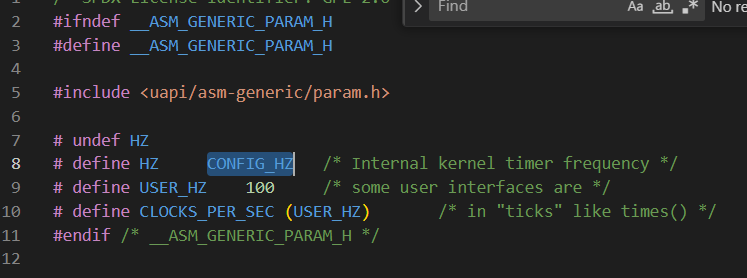
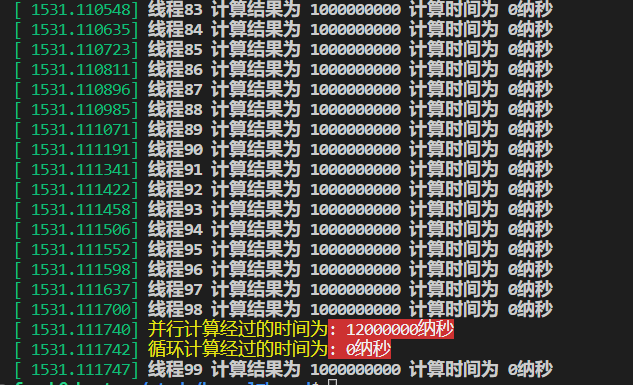
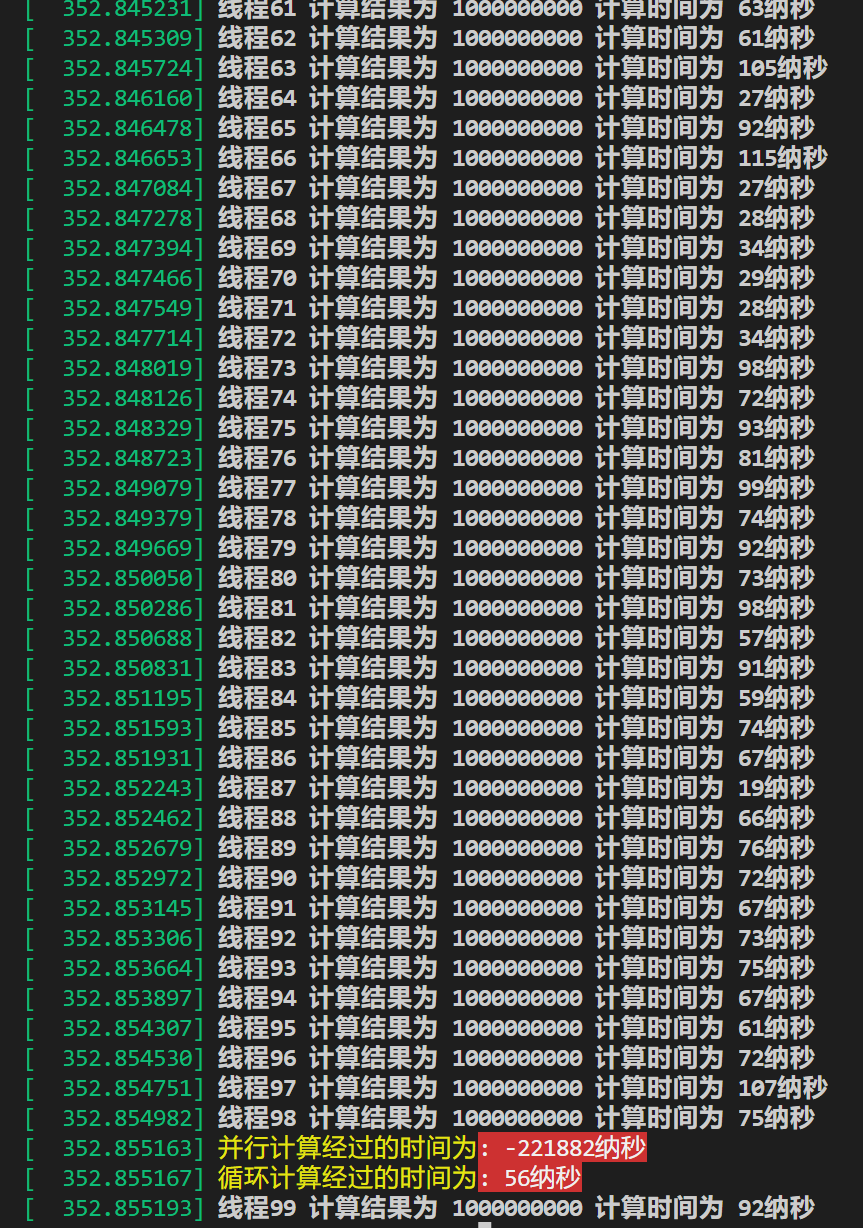
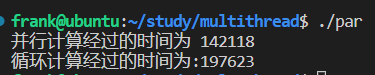
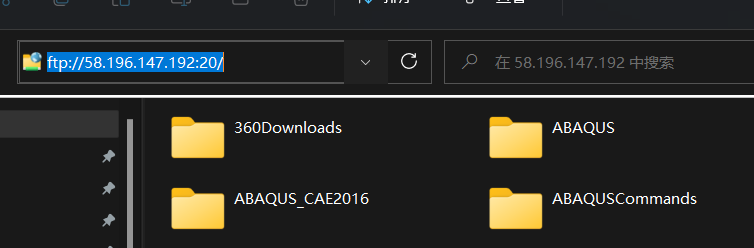
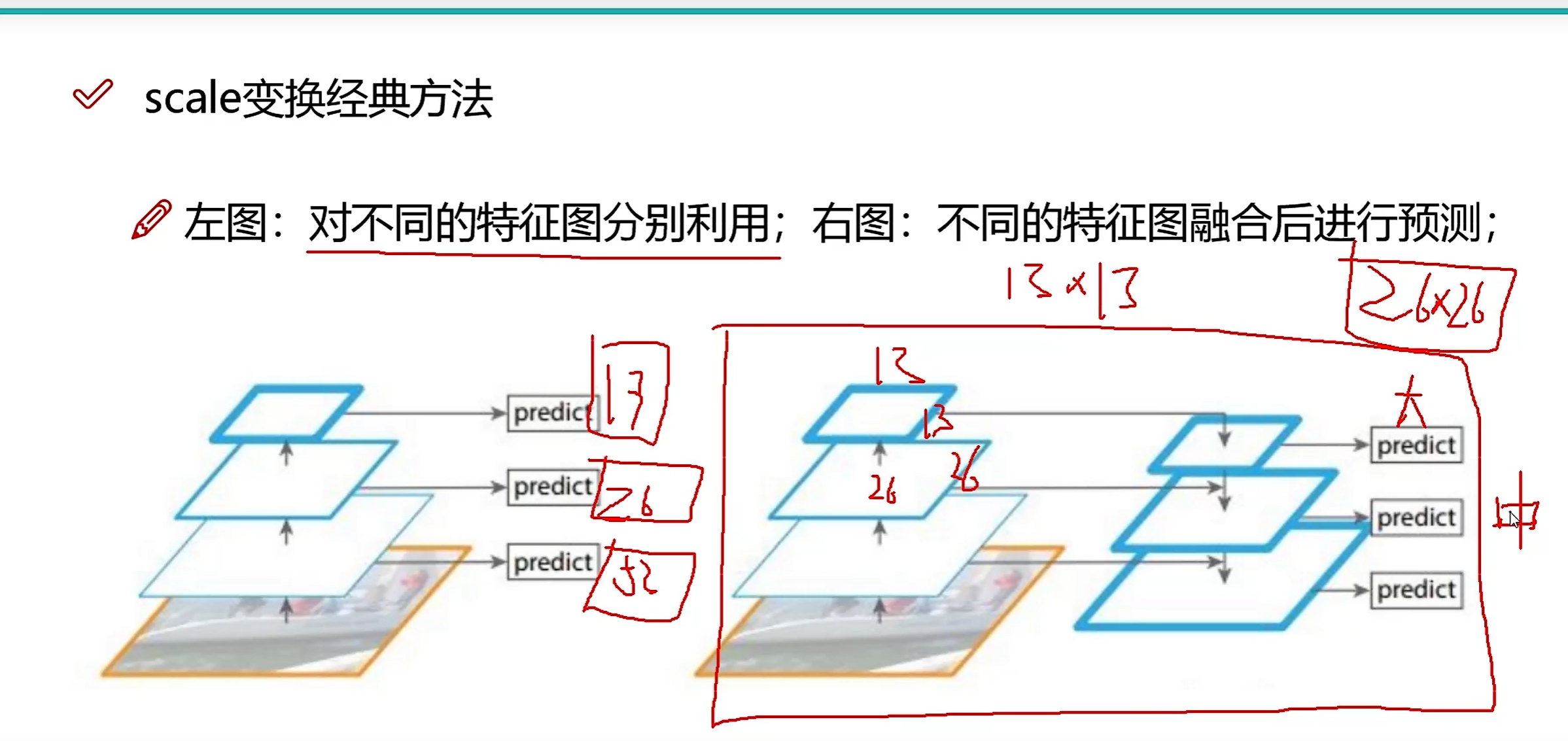
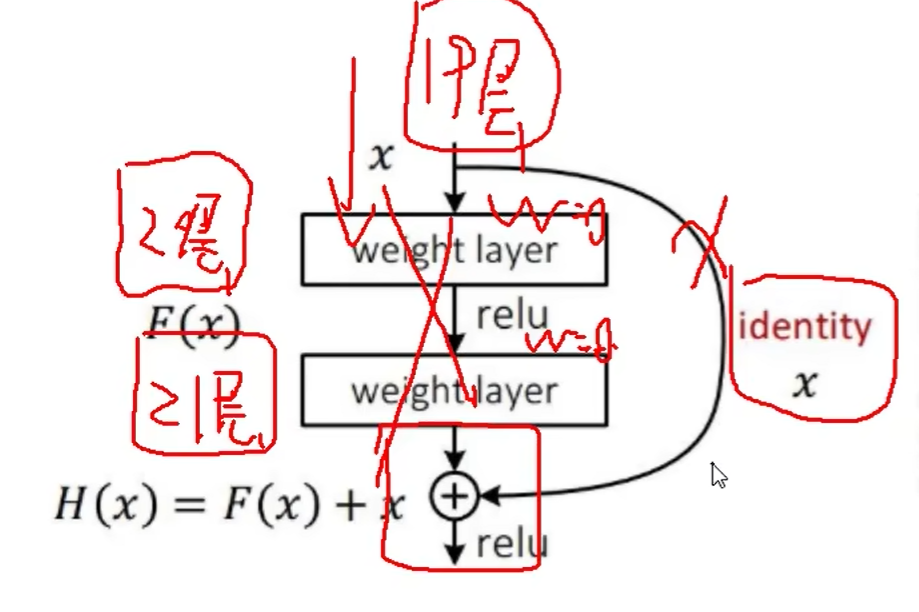
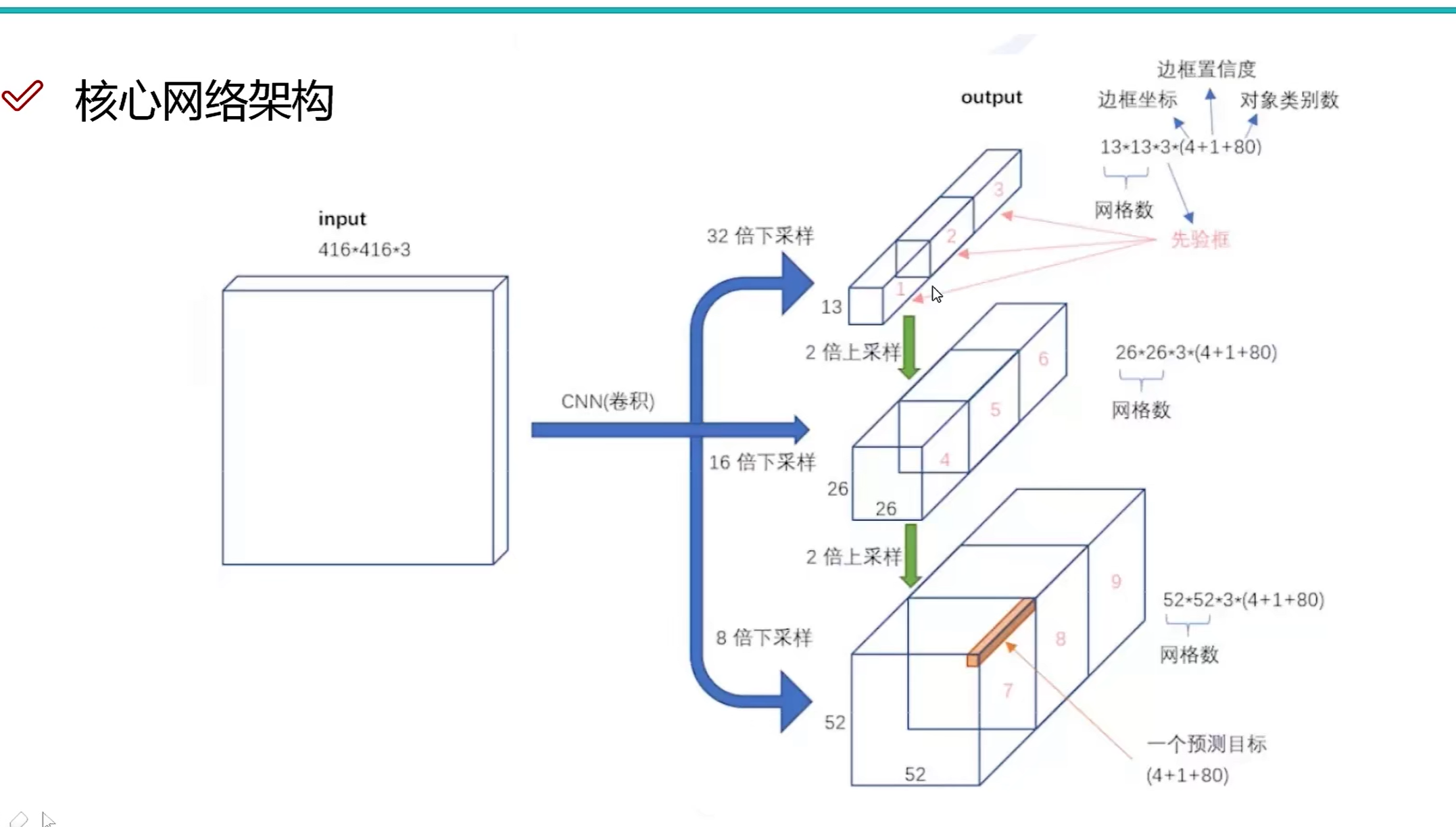
 中,值是250如图
中,值是250如图