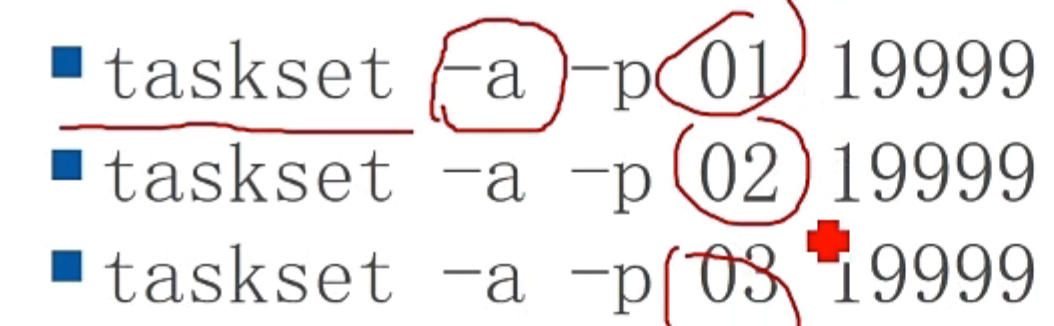使用UltraISO制作启动盘
- 链接
- 用管理员权限启动UltraISO
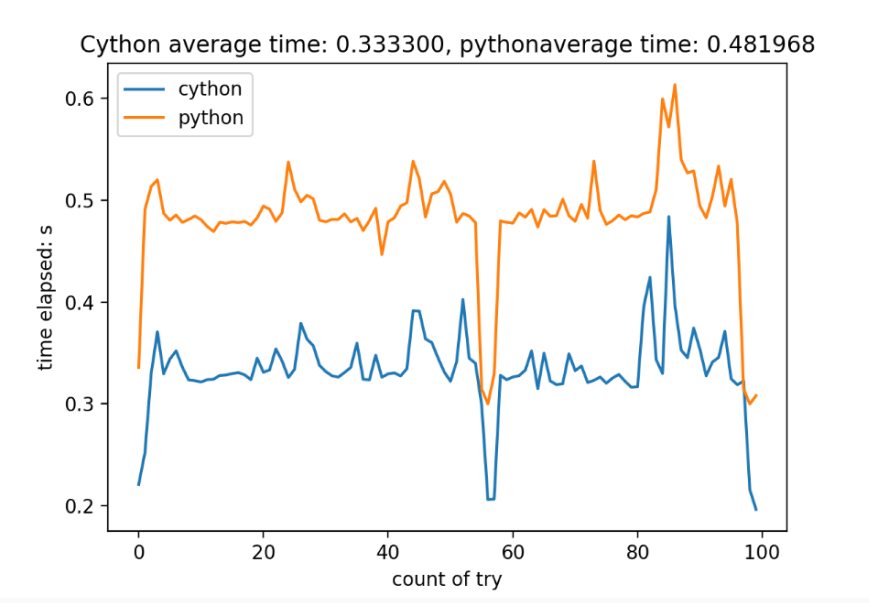
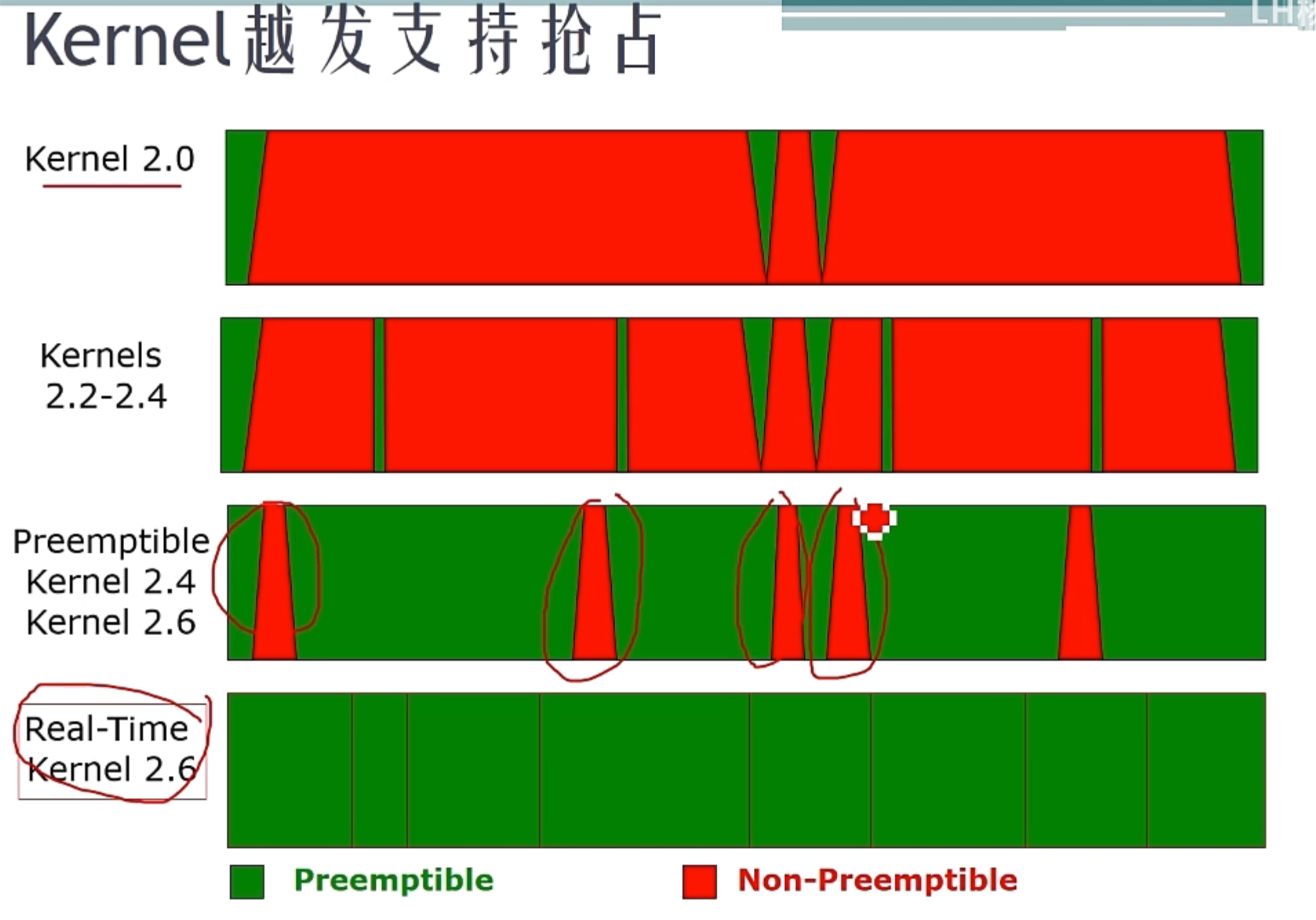
为何要安装实时补丁
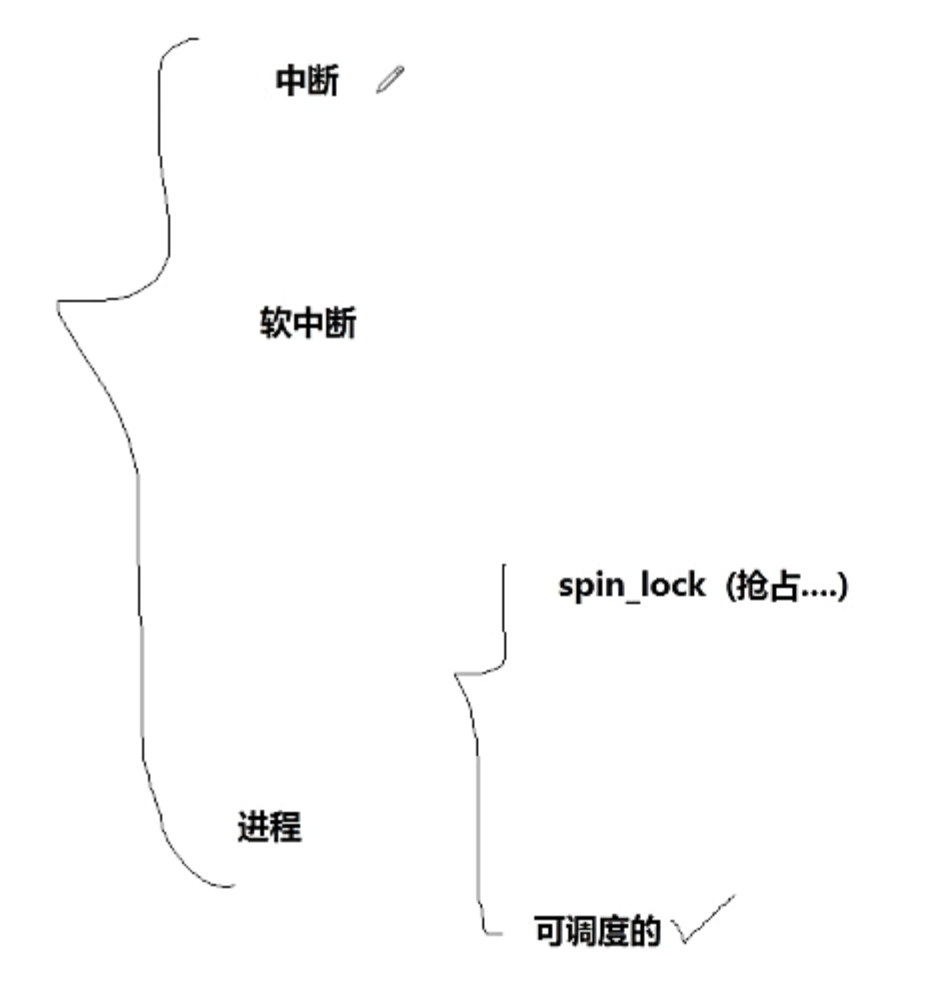
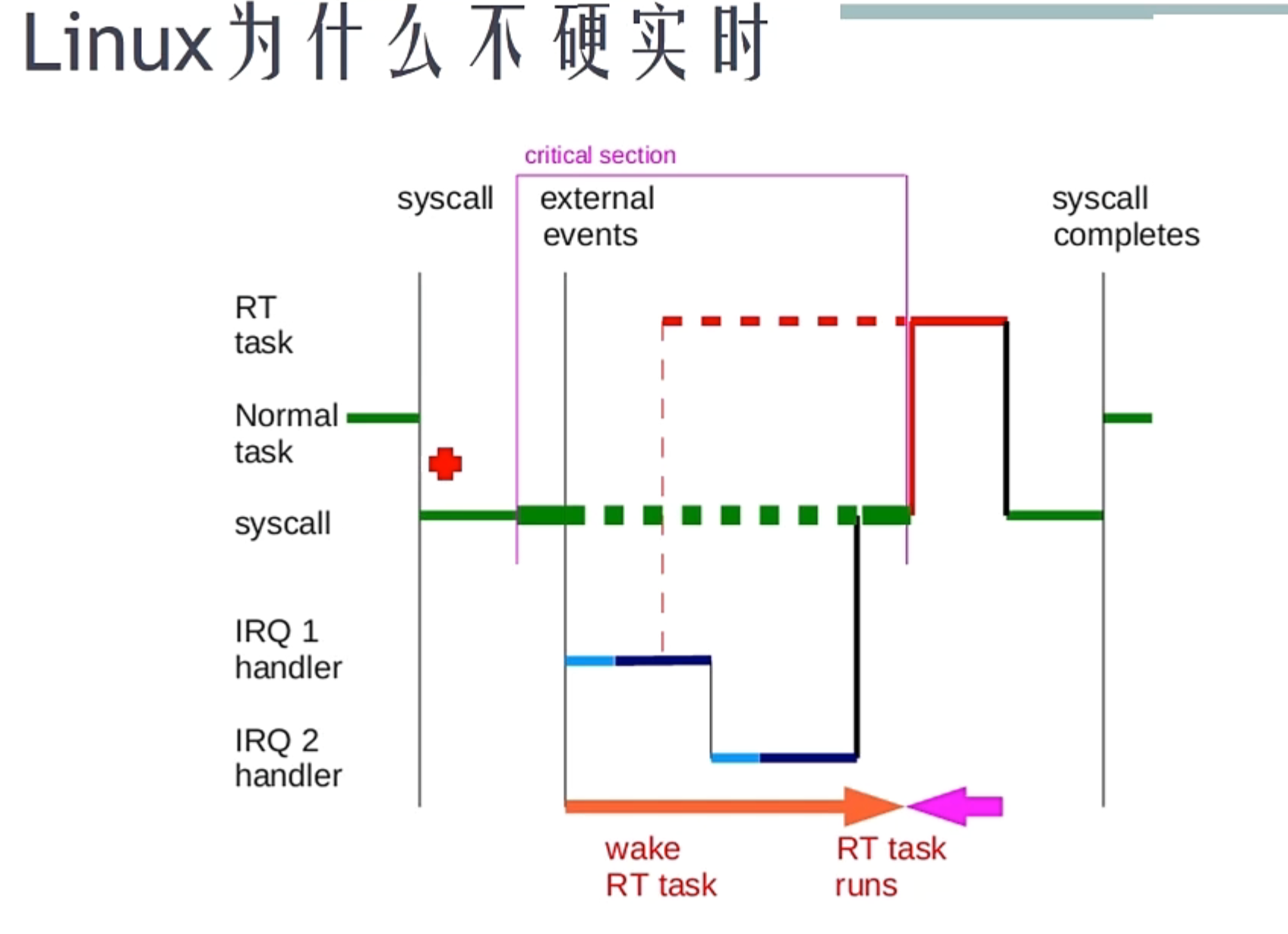
Linux系统从原理上说并不是一个实时系统,因为Linux系统有很多状态是不可被抢占的,比如持有自旋锁的状态等等,在其他博客中有所涉及,这会导致Linux系统定时不准等一系列问题,对实时控制十分不利
增加实时补丁不能完全使得Linux系统变为实时系统,但是可以使得Linux系统不可抢占的部分大为减少,增强实时性
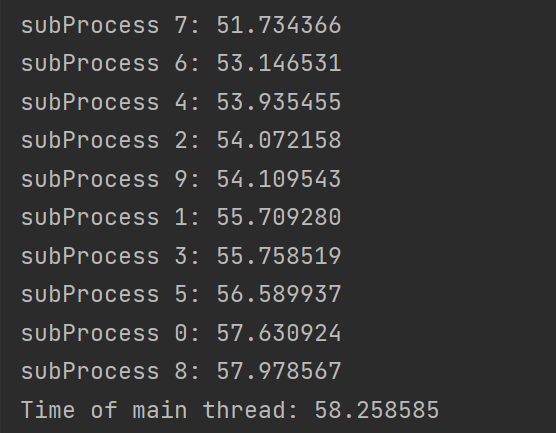
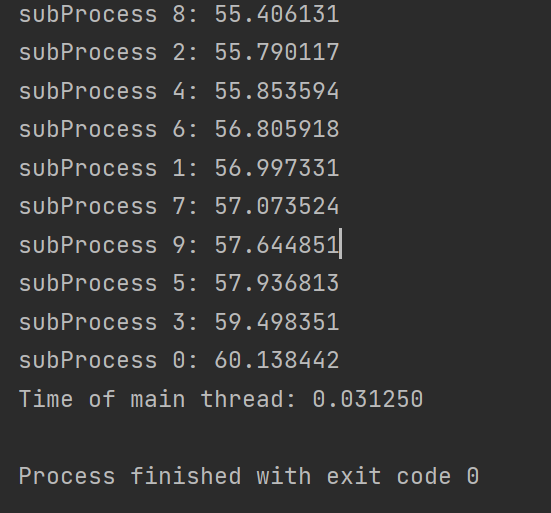
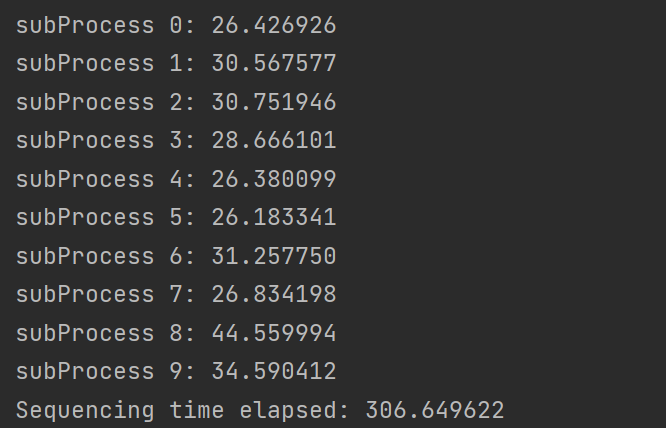
对Linux内核实时性影响比较大的情况
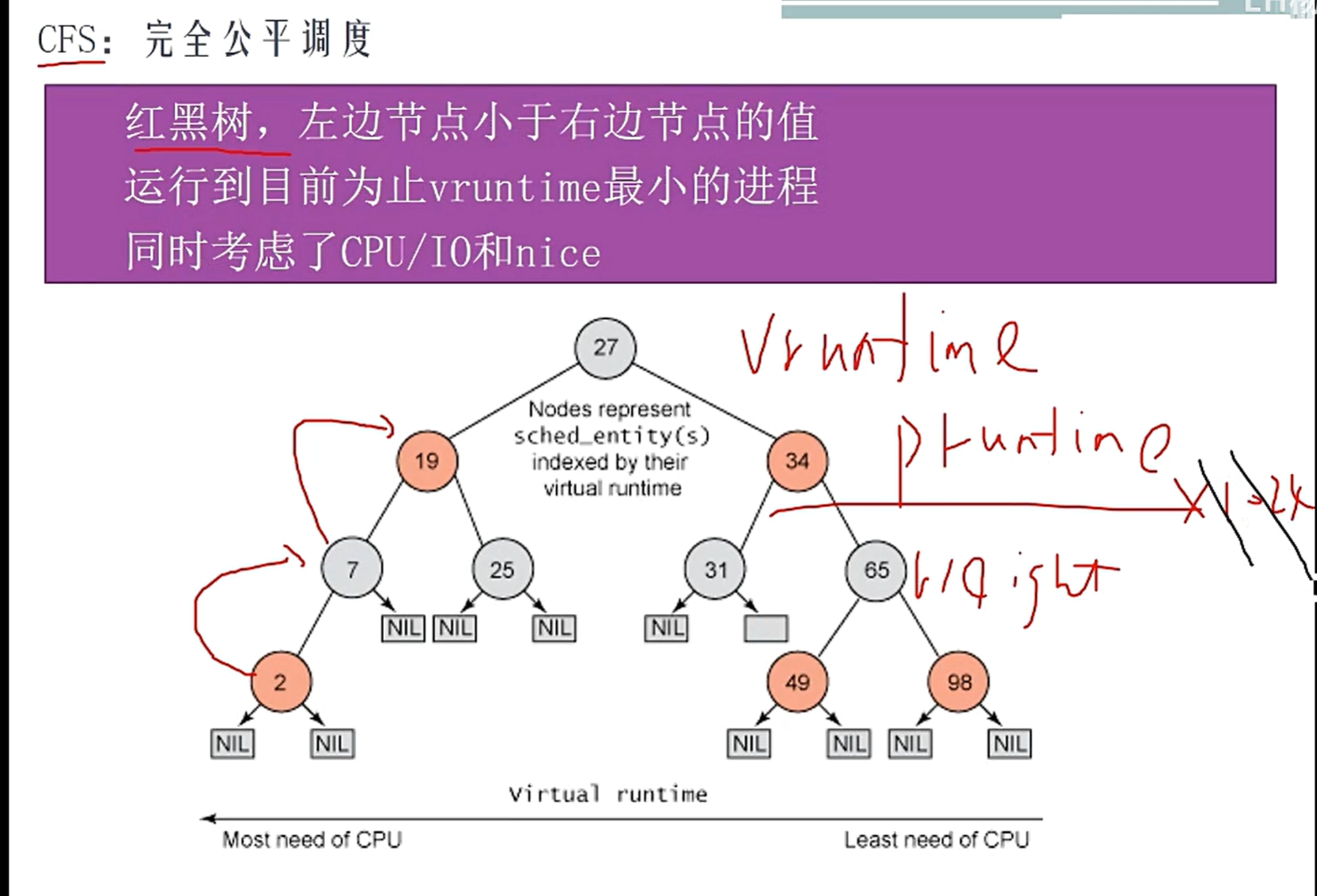
实际上是Linux内核的进程切换频率影响比较大,决定了定时的最佳分辨率
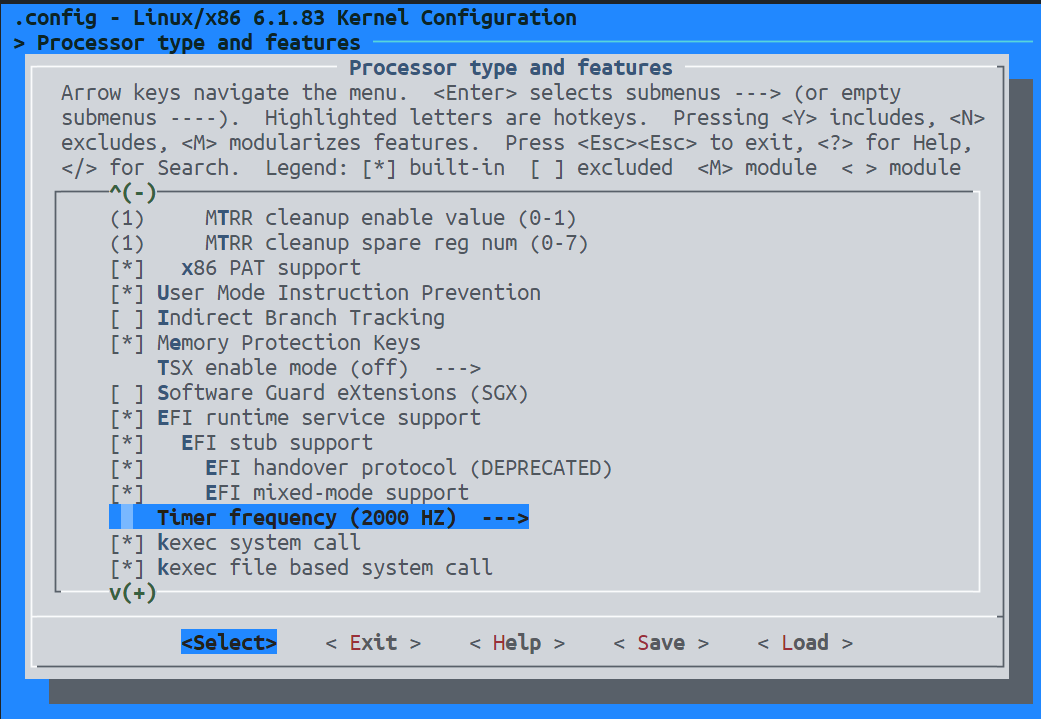
Linux内核编译的时候最多只支持1000Hz,也就是时间分辨率为1ms,但是假如要求更高的话就必须自己在
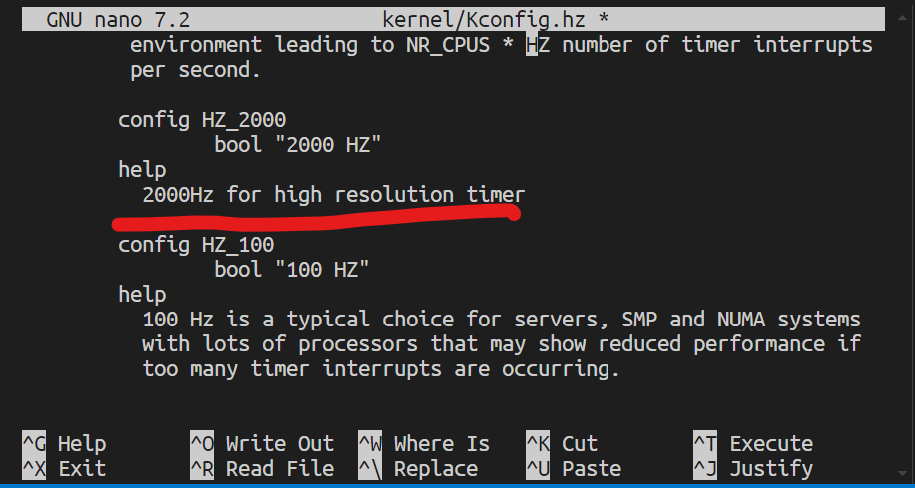
kernel/Kconfig.hz中添加设置如下图如图编译的时候就可以增加一个自定义的2000Hz选项
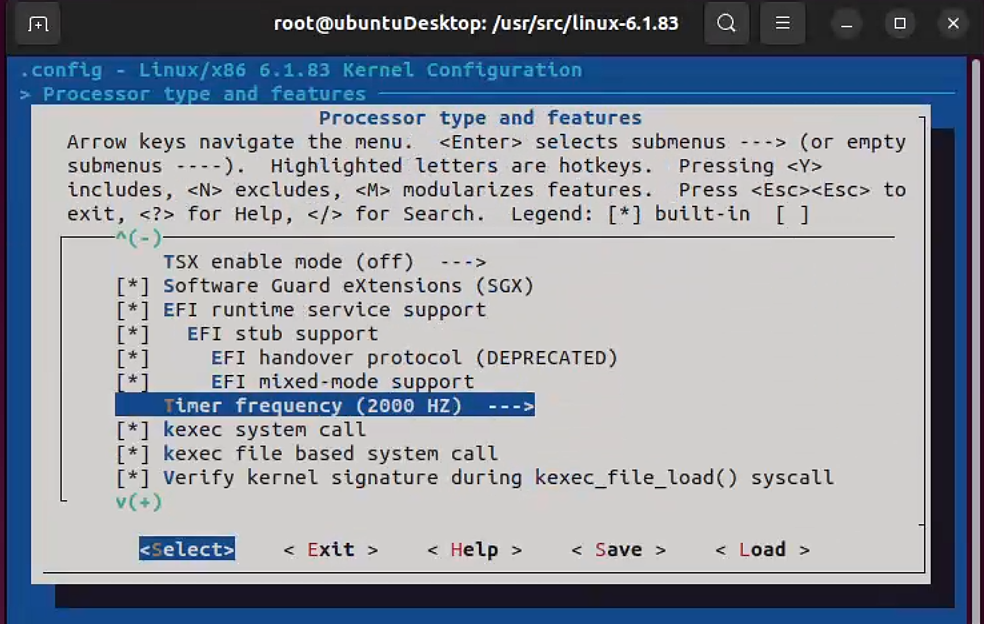
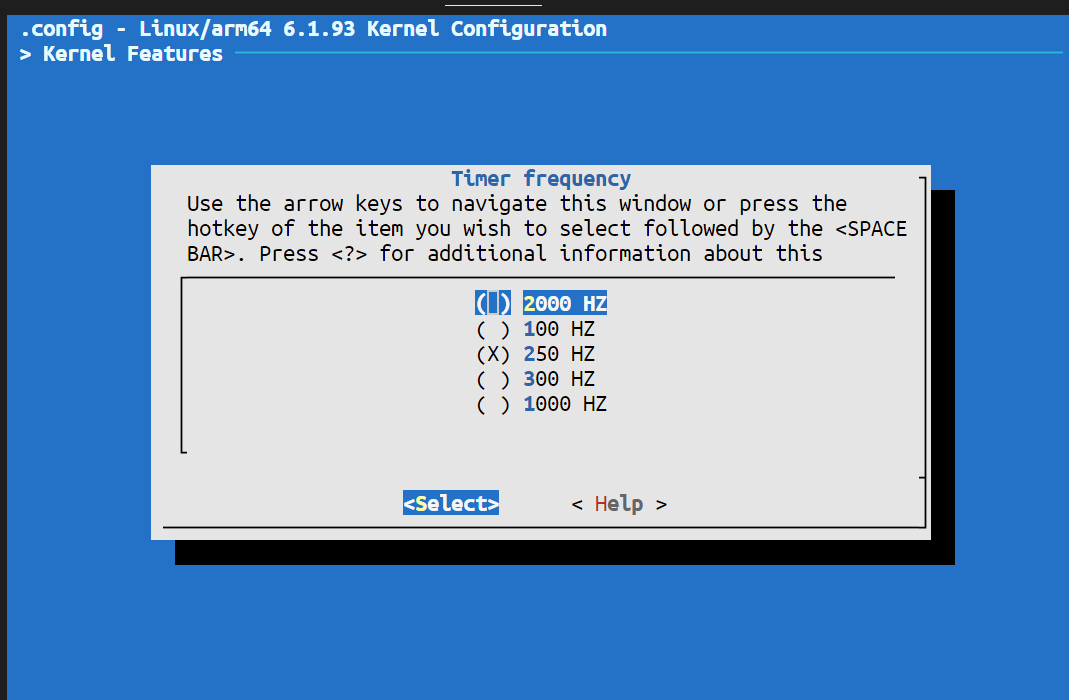
然后再选择实时内核
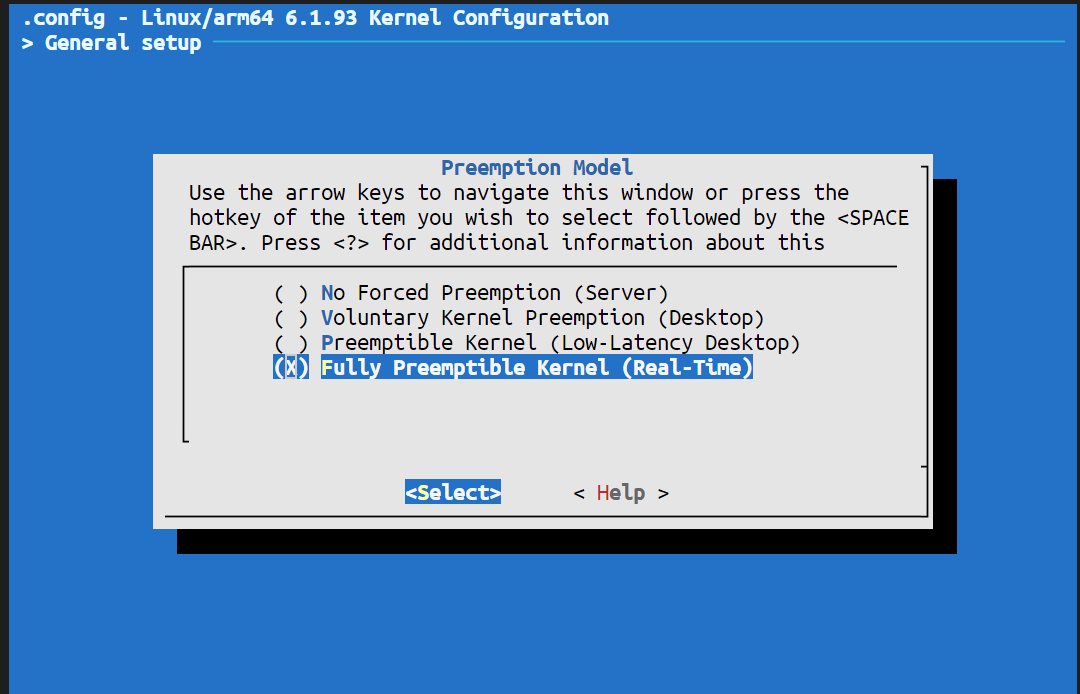
注意,对定时准确性影响比较大的是内核的
timer频率,甚至实时内核与否都只起到次要作用
(更新)安装参考
安装依赖
sudo apt-get install build-essential libncurses-dev bison flex libssl-dev libelf-dev如果下载的是形如
patches-6.1.83-rt28.tar.xz之类的先将其解压缩,然后在内核源码目录下执行
for patch in <解压缩目录>/*.patch; do
patch -p1 < "$patch"
done-
- 将内核源码解压到
/usr/src/<你的内核名称>,目录下sudo tar -xvf <>.tar.xz -C <path to kernel dir>
sudo su切换到root用户- (此处跳过打实时patch的步骤)
- 将旧的config复制到当前源码目录下的
.config文件cp /boot/config-$(uname -r) .config
- 按照上面说的修改
.config - 使用
make menuconfig修改设置
- 将内核源码解压到
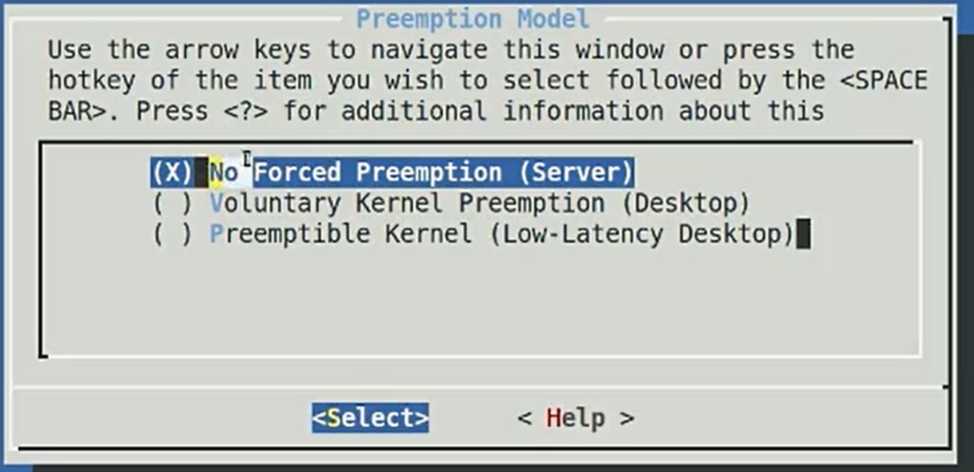
此外还要在
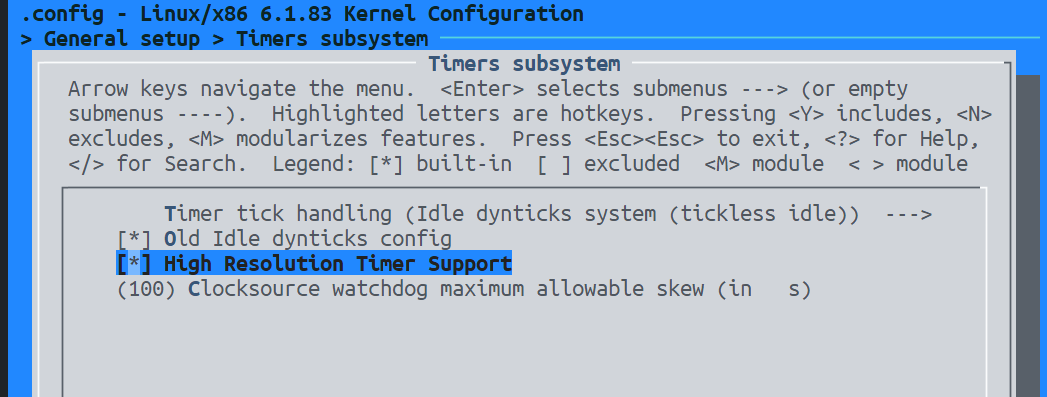
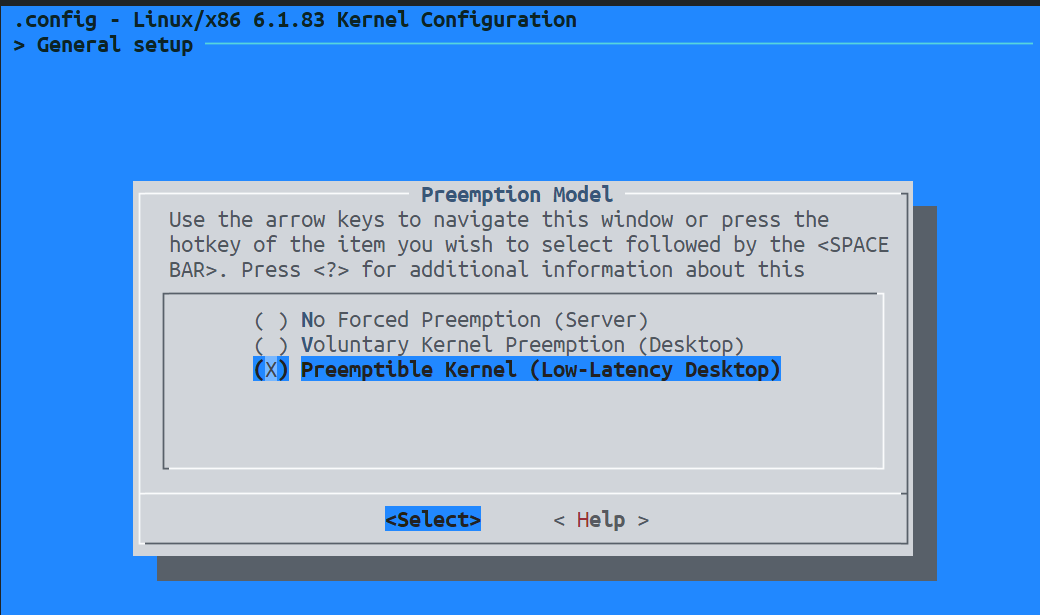
make menuconfig中配置抢占为General setup -> Preemption Model:选择 Fully Preemptible Kernel (RT)Processor type and features -> Timer frequency:设置为 1000 Hz 以获得更高的时钟分辨率
General setup -> Timers subsystem:启用 High Resolution Timer Support
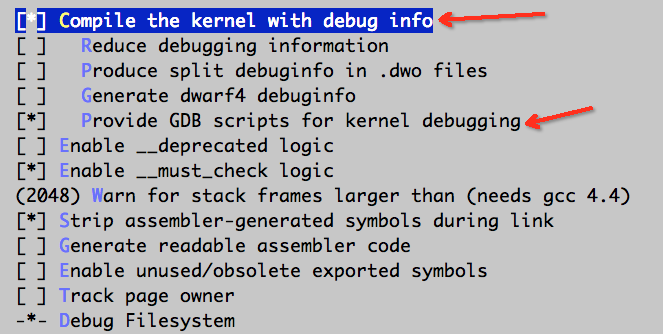
然后删除内核模块的一些校验如图
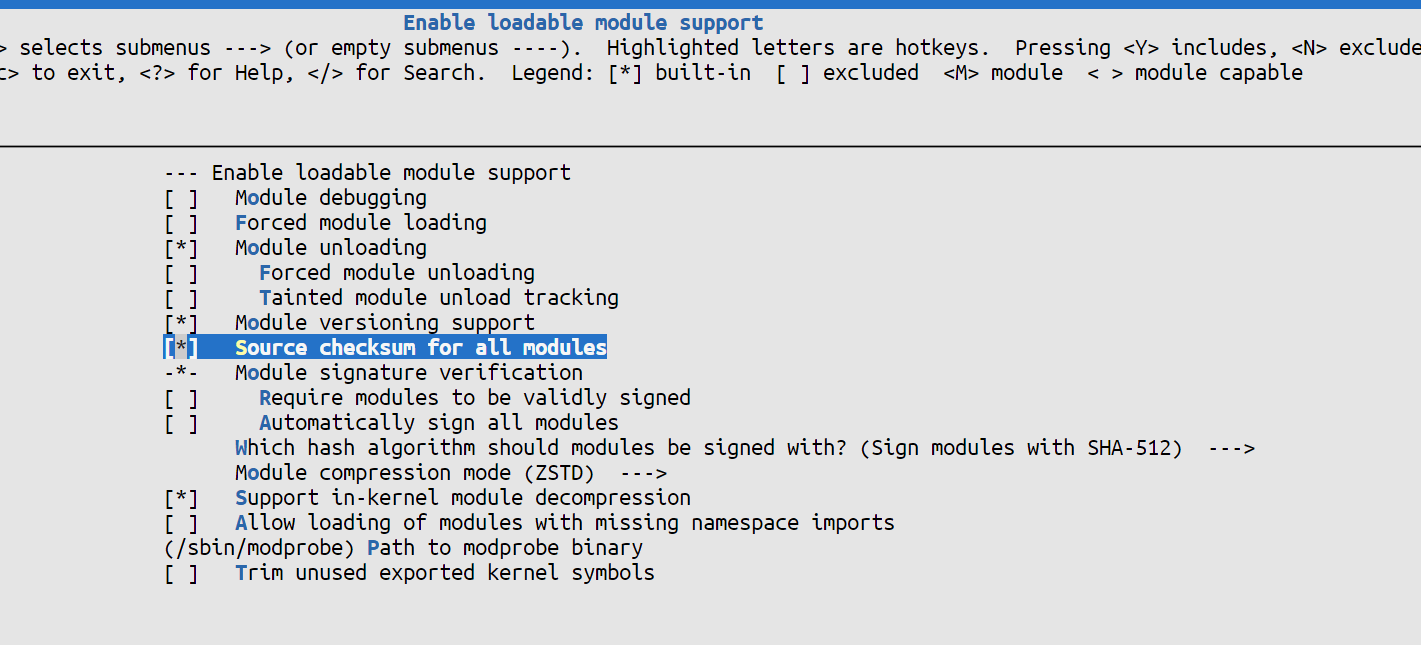
注意最后要注释设置
CONFIG_MODULE_SIG_ALL,CONFIG_MODULE_SIG_KEY,CONFIG_SYSTEM_TRUSTED_KEYS,CONFIG_SYSTEM_REVOCATION_LIST,CONFIG_SYSTEM_REVOCATION_KEYS,CONFIG_DEBUG_INFO=y- 注意,上述每个都必须注释掉,如果注释了一部分但是漏掉其余部分会导致编译内核的时候出错
修改
.config的CONFIG_LOCALVERSION选项为自己需要的内核后缀名(记得前面加-)make -j8 && make modules_install -j8make install
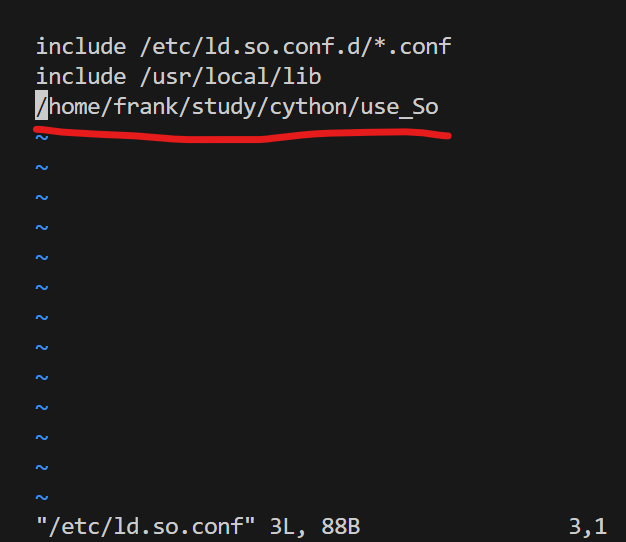
修改默认启动内核
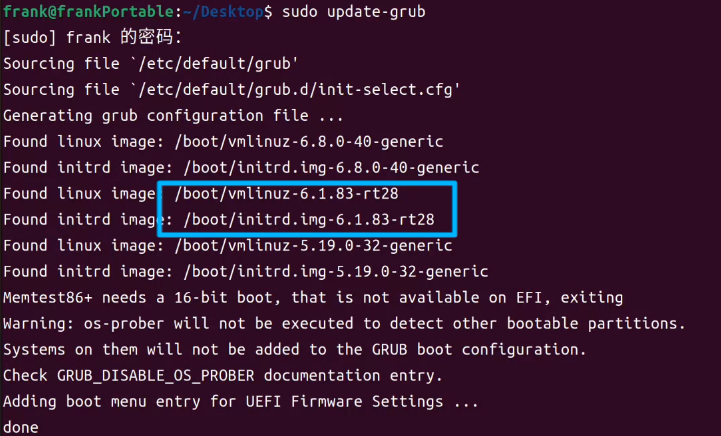
先使用
sudo update-grub观察一般情况下编译安装内核之后,系统默认的启动内核还是原来的
此时需要修改
/etc/default/grub如图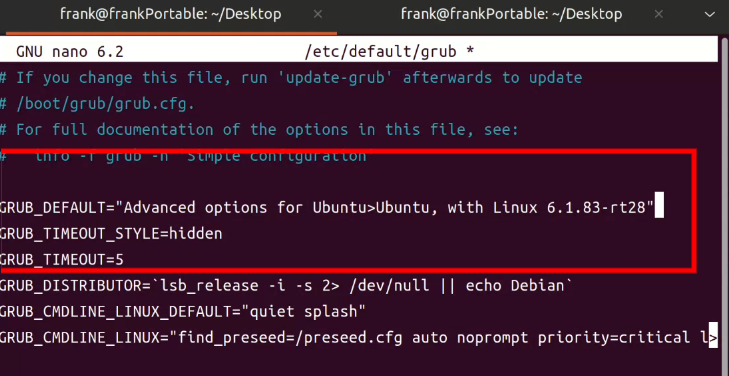
- 也就是修改为
GRUB_DEFAULT="Advanced options for Ubuntu>Ubuntu, with Linux <你的Linux内核版本名称>"
然后执行
sudo update-grub然后重启即可自动进入指定的内核
-
内核模块测试
重点是要在一开始解压内核源码的时候,就把内核源码解压到
/usr/src目录下,这样的话就可以编译自定义内核模块了
按照上述逻辑完美解决
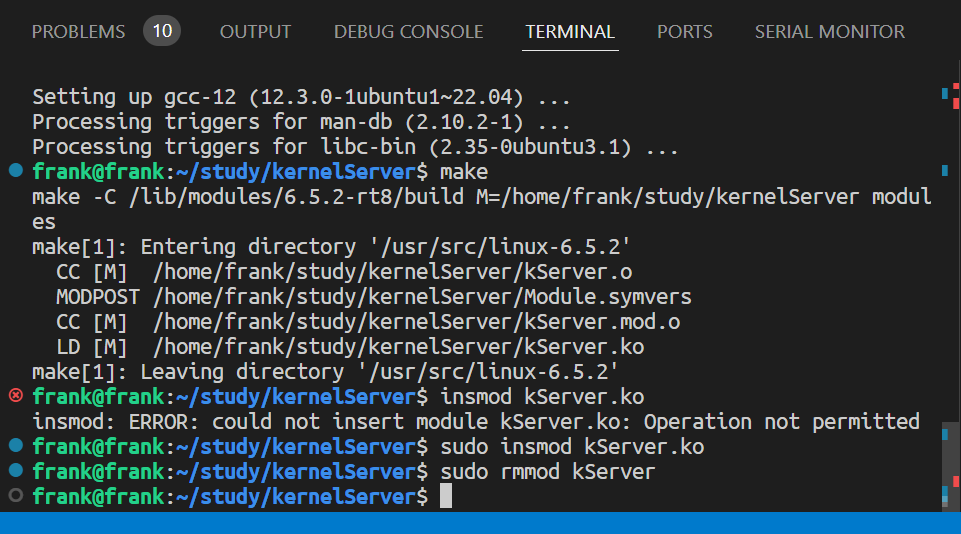

问题
启动Ubuntu的时候bad shim signature
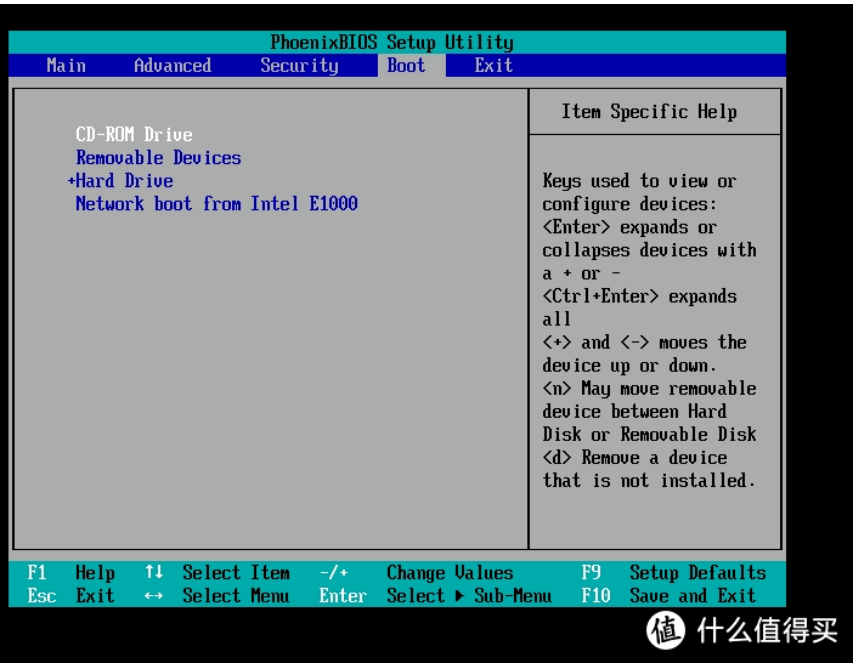
- 因为BIOS里开启了安全启动,进入BIOS关闭secure boot即可
遇到类似于memtest86+ needs a 16bit等等问题
- 在
/etc/default/grub文件中添加一行GRUB_DISABLE_OS_PROBER=false,但是未能解决问题 - 但是只要在开机的时候按下
Esc到Ubuntu高级设置,找到需要的内核启动即可更换内核之后遇到
载入Ubuntu内存盘,error: out of memory - 更换新内核之后遇到
载入Ubuntu内存盘,error: out of memory无法开机,但是用旧的内核可以启动 sudo update-initramfs -u- 之后又报错
can't find command hwmatch out of memory - 重新编译内核,暂时未解决
- 怀疑是系统分区太小导致的,重新格式化并且分配系统分区解决问题
更换内核之后因为Linux下头文件与内核版本不符导致不能安装本机编译的模块
以下方法未解决问题
insmod报错为insmod: ERROR: could not insert module ***.ko: Invalid module formatdmesg查看到报错为disagrees about version of symbol module_layout-
(不要执行这一步)编译内核的时候删去模块版本检查
module versioning support,在Enable loadable module support下然后重新安装内核,重新编译模块安装,安装失败使用
sudo dmesg查看内核log,得到version magic '6.2.0-rt3 SMP preempt mod_unload modversions ' should be '6.2.0-rt3 SMP preempt_rt mod_unload '重新安装内核之后修改内核
/usr/src下的内核源码/usr/src/linux-headers-系统内核名称/include/generated下的utsrelease.h中的选项第一个修改为需要的内核名称即可
然后修改
/usr/src/linux-headers-<内核名称>/include/config/kernel.release文件,内容修改为<需要的内核名称> // 比如 6.2.0-rt3
然后修改真正产生
version magic字符串的文件/usr/src/linux-headers-<内核名称>/include/linux/vermagic.h/* SPDX-License-Identifier: GPL-2.0 */
/* Simply sanity version stamp for modules. */
/*
#ifdef CONFIG_PREEMPT_BUILD
#define MODULE_VERMAGIC_PREEMPT "preempt "
#elif defined(CONFIG_PREEMPT_RT)
#define MODULE_VERMAGIC_PREEMPT "preempt_rt "
#else
#define MODULE_VERMAGIC_PREEMPT ""
#endif
*/
// 修改此处
// 修改下面的部分拼出自己想要的version magic找到
VERMAGIC_STRING中的对应项,自己修改为需要的值或者顺序,注释掉不需要的即可然后得到与前面要求的相同的
version magic字符串,即可insmod了找不到符号
Unknown symbol __mutex_init (err -2)
insmod报错
insmod: ERROR: could not insert module ***.ko: Unknown symbol in module未能解决
最终解决方案
在编译内核模块的时候,将内核模块目录下的
Makefile文件中的KDIR修改为自己编译当前内核源码的目录,不要用/usr/src下的源码,然后照常make即可insmod不要在
make menuconfig中关闭module versioning support选项,否则会因为version magic字符串不一致导致很多预编译好的其他模组不能安装