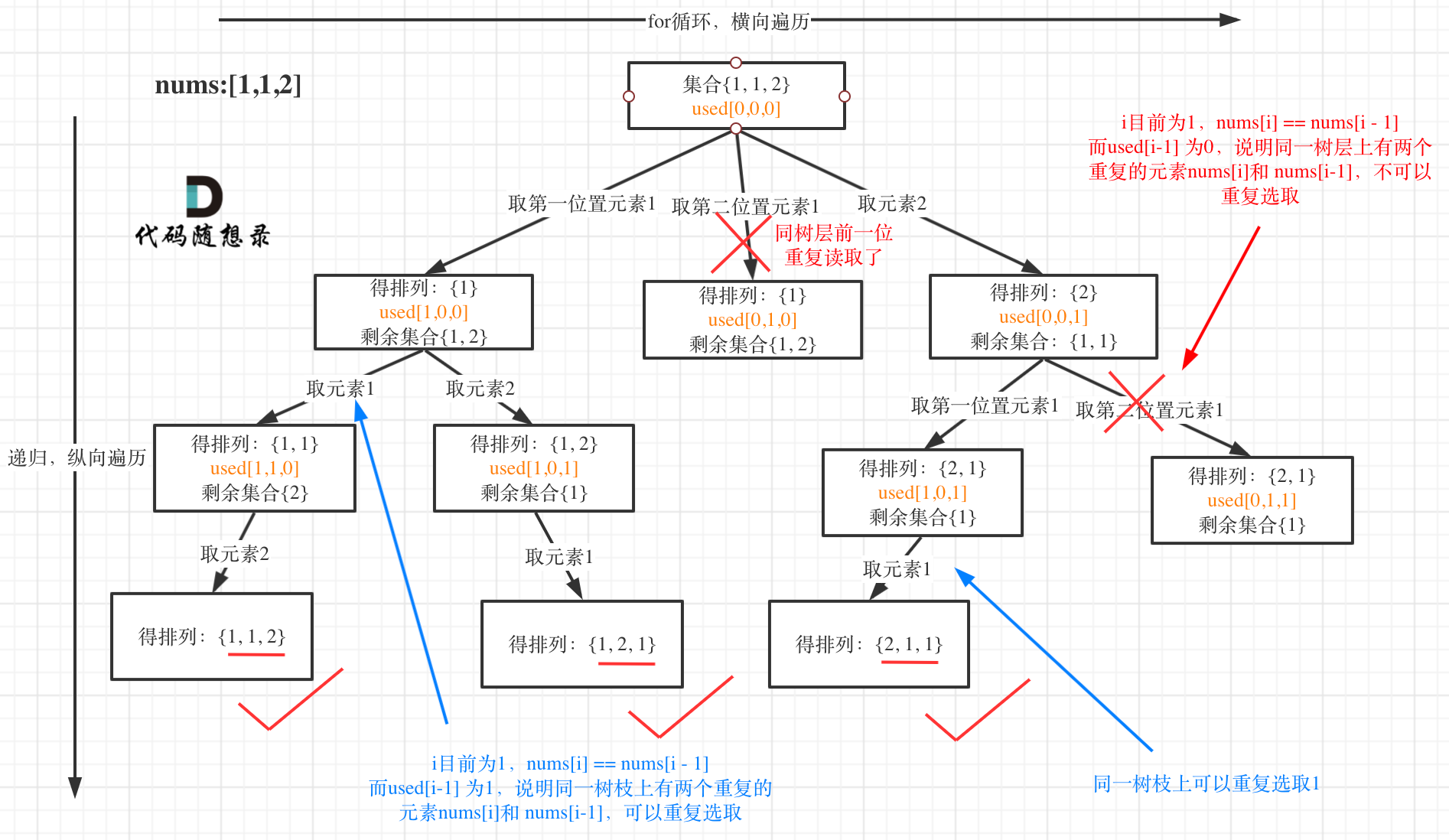
class Solution {
public:
vector<string> ret;
vector<string> restoreIpAddresses(string s) {
string ans;
traversal(s, 0, 0, 4, ans);
return ret;
}
void traversal(string& s, int start, int cnt, int remain, string ans)
{
if(start==s.size()&&cnt == 3)
{
if(remain == 0)
{
ret.push_back(ans.substr(1));
}
return;
}
if(remain<0)return;
if(start == s.size())return;
if(cnt == 0 || cnt == 3)
{
ans+=".";
ans+=s[start];
if(s[start] =='0')
{
traversal(s, start+1, 3, remain-1, ans);
}
else
{
traversal(s, start+1, 3, remain-1, ans);
traversal(s, start+1, 1, remain-1, ans);
}
return;
}
else if(cnt == 1 || cnt == 2)
{
ans+=s[start];
if(stoi(ans.substr(ans.size()-cnt-1))>255)return;
if(cnt==1)
{
traversal(s, start+1, 3, remain, ans);
}
traversal(s, start+1, cnt+1, remain, ans);
return;
}
}
};
|
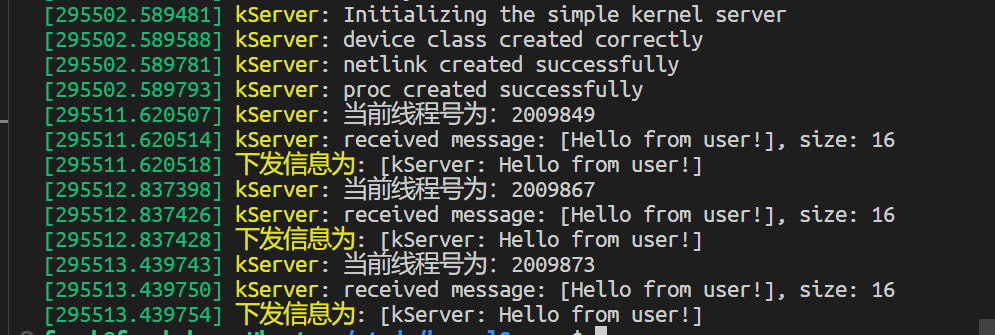
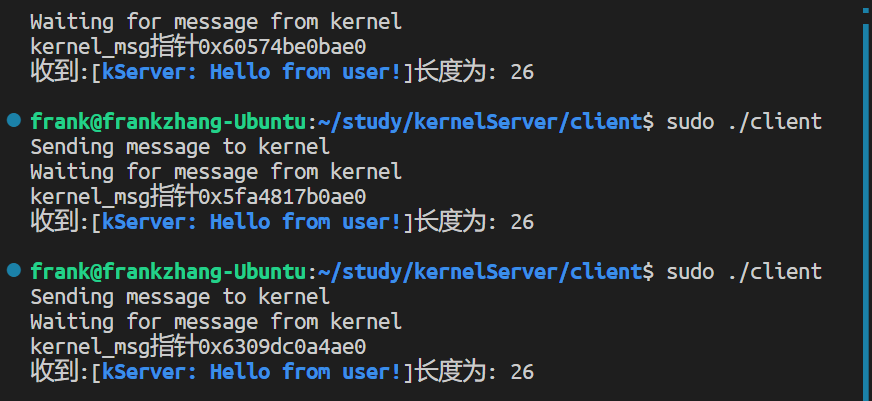
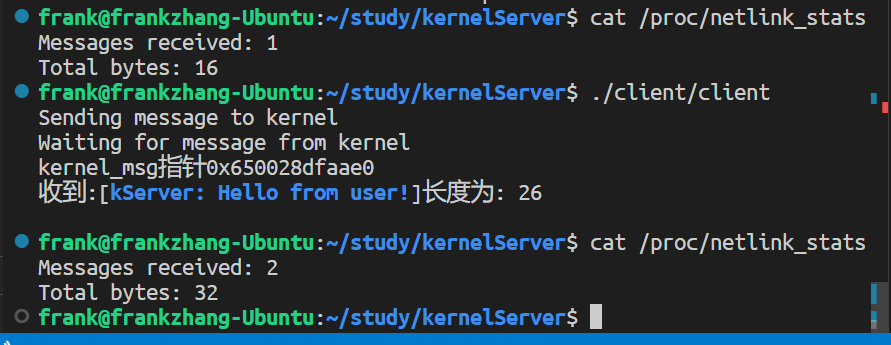
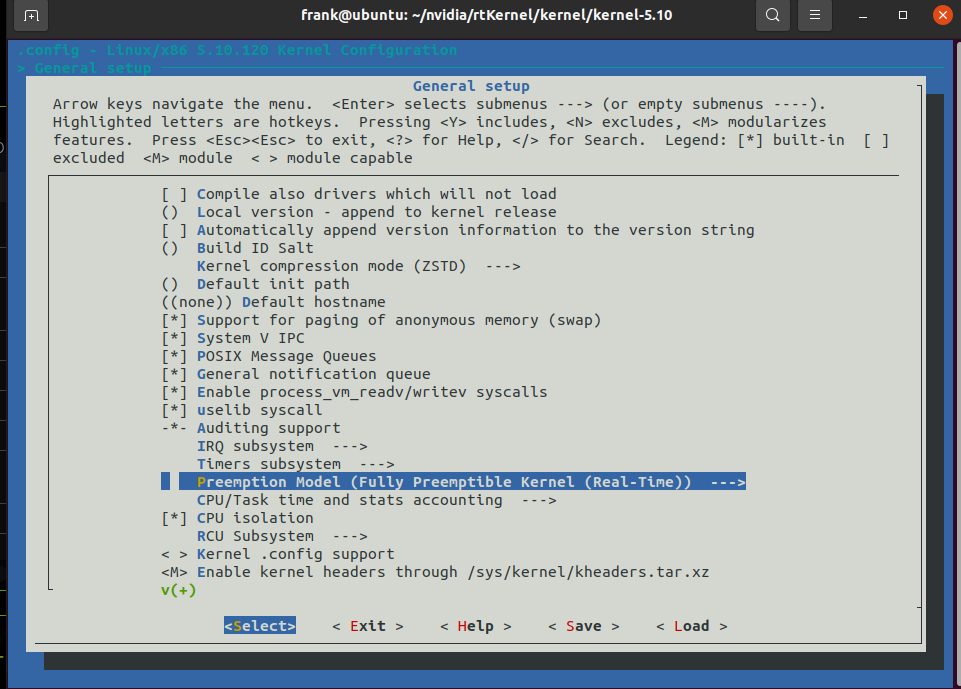
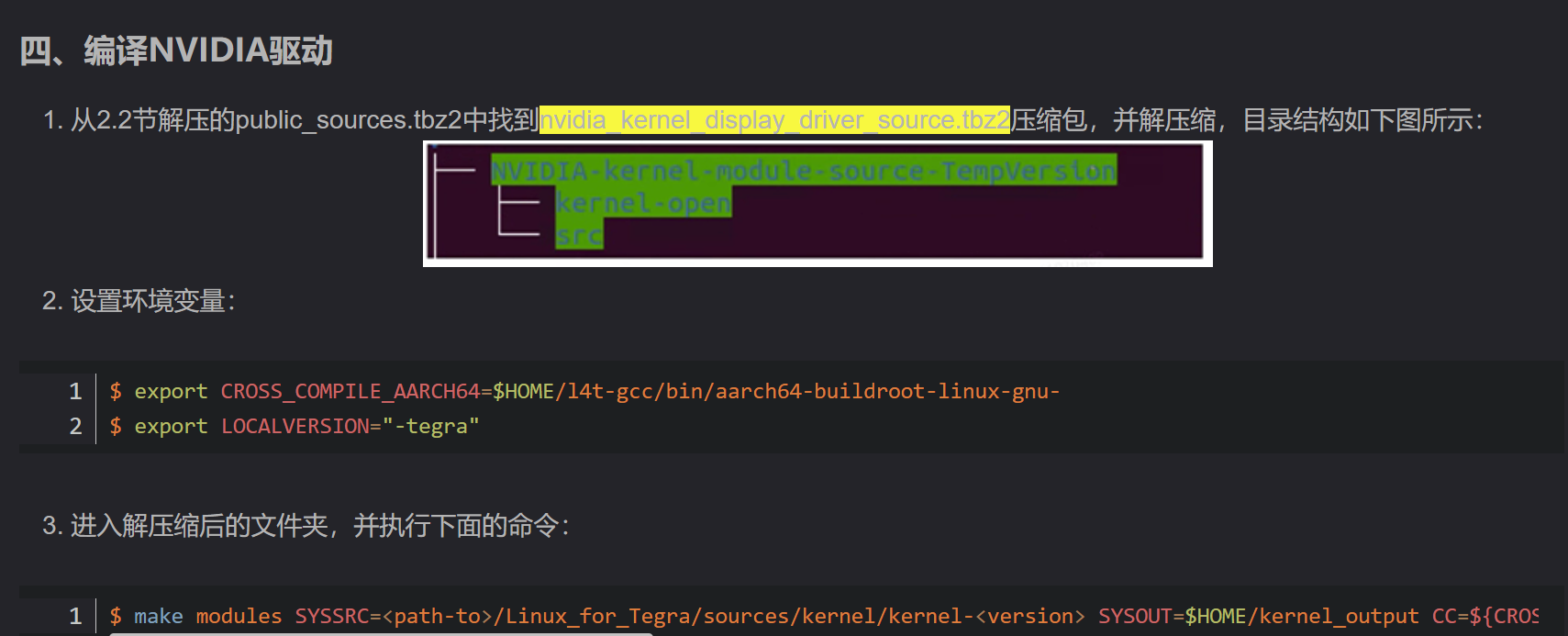
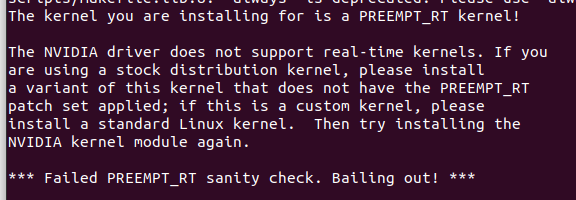
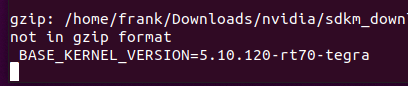
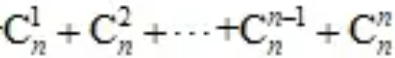 种,上述结果的求和是
种,上述结果的求和是