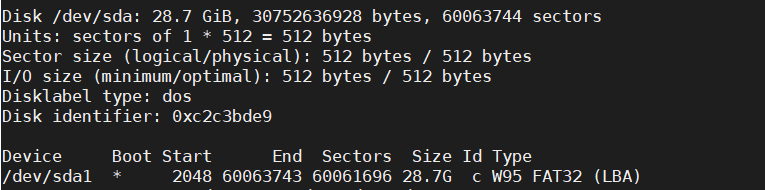
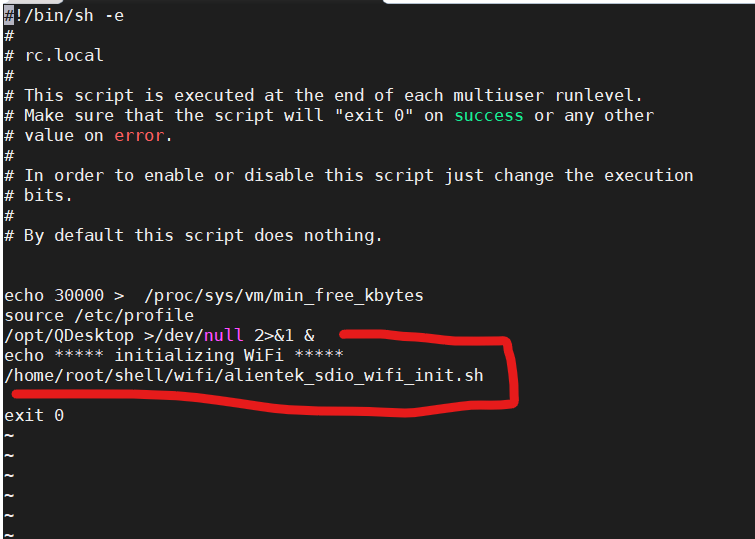
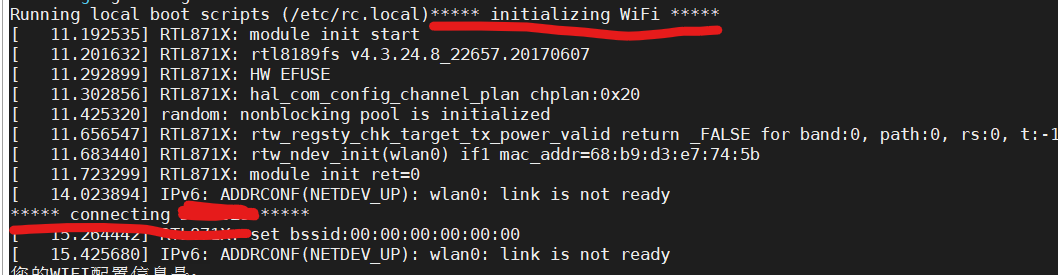
使用echo向文件写入数据
- 主要是使用echo的输出重定向功能,也就是
>和>> - 覆盖文件内容用
>,也就是echo "Raspberry" > test.txt
- 追加文件内容用
>>echo "string" >> <filename>- 就是将string追加到filename文件的末尾
namespace Ui { class MainWindow; class myThread;}假如在一个类中使用在之后定义的类的对象或者其他内容的话,先在这个类之前使用class <被使用的类名>;声明一下类
class <class name> : <访问权限修饰符> <super class> |
class <class name> : <访问权限修饰符> <super class> |
<返回类型说明符> operator <运算符符号>(<参数表>) |


#比如有一个dog类,具有一个属性是体重weight |
C++多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数
也就是说用基类的指针调用子类的对象的时候,会根据子类的具体类型进行具体的函数的选择
虚函数是 C++中用于实现多态(polymorphism)的机制。核心理念就是通过基类访 问派生类定义的函数
多态的条件
virtual ReturnType FunctionName(Parameter)virtual void funtion1()=0数据封装是一种把数据和操作数据的函数捆绑在一起的机制,数据抽象是一种仅向用户暴 露接口而把具体的实现细节隐藏起来的机制,C++ 通过创建类来支持封装和数据隐藏(public、 protected、private)。
简而言之就是不直接将变量暴露在用户的访问权限下而设置一个专门的函数处理用户对于变量的访问

然后shell基于执行权限(x)然后运行即可
chmod +x qt-opensource-linux-x64-5.12.9.run |
./qt-opensource-linux-x64-5.12.9.run |

QObject::connect(sender, SIGNAL(signal()), receiver, SLOT(slot())); |
其中,sender 是发射信号的对象的名称,signal() 是信号名称。信号可以看做是特殊的函 数,需要带括号,有参数时还需要指明参数。receiver 是接收信号的对象名称,slot() 是槽函数 的名称,需要带括号,有参数时还需要指明参数。
使用例
QObject::connect(pushButton, SIGNAL(clicked()), MainWindow, SLOT(close())); |
其中的pishButton是动作的发出者,MainWindow是信号的接收者
一个信号可以连接多个槽
多个信号也可以链接同一个槽
一个信号可以连接另外一个信号
connect(pushButton, SIGNAL(objectNameChanged(QString)),this, SIGNAL(windowTitelChanged(QString))); |
当一个信号发射时,也会发射另外一个信号,实现某些特殊的功能。
断开连接使用disconnect(),此处略
signals里面进行声明
创建槽的方法也很简单,也是直接在 mianwindow.h 里直接声明槽,在 mianwindow.cpp 里 实现槽的定义,声明槽必须写槽的定义(定义指函数体的实现),否则编译器编译时将会报错。
槽可以是任何成员函数、普通全局函数、静态函数
槽函数和信号的参数和返回值要一致
举例
|
|
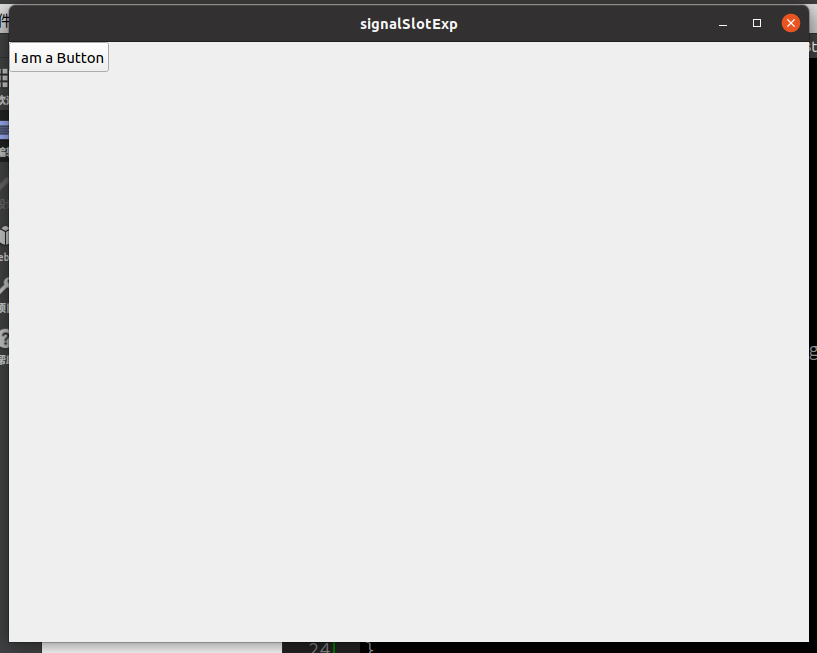
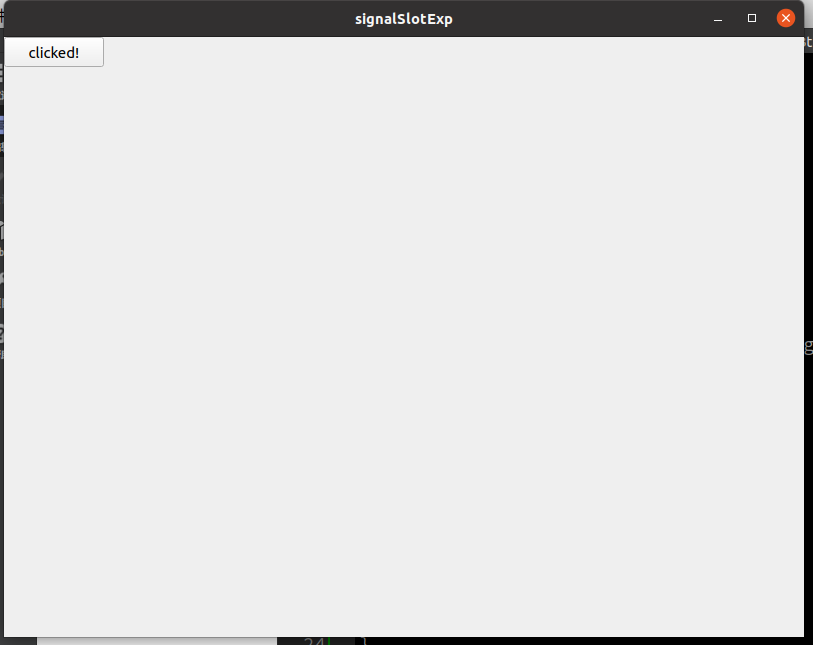
上面的代码中实现了自定义一个信号pushBtnTxtchanged(),将其通过自定义的槽函数pushBtnClicked()emit出来,然后连接到changeBtnTxt()函数上。通过将自定义的槽函数pushBtnClicked()连接到按钮自带的clicked()信号上,实现按下之后修改按键文字的功能。
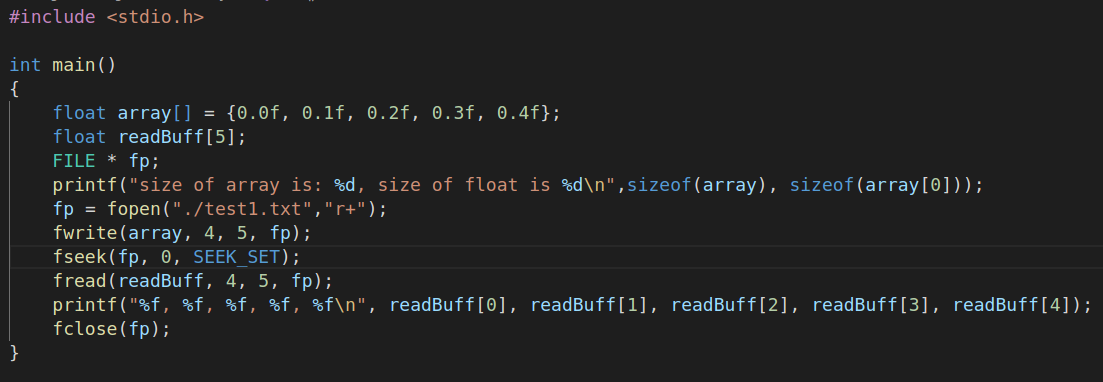
上面的函数实现了将一个每个单元大小为4个byte的浮点数存储在文件中,并且再原样读取回来的功能。
写文件和读文件的参数分别是单个单元的大小为4字节,总长度为5.下面看结果

测试可知,文件读写函数用的是同一个文件偏移量,也就是随着文件的写入而顺次增加的偏移量,假如文件读取之前不将偏移量移动回初始位置的话,会什么也读不出来
可见sizeof()函数读取数组的时候,读取的是数组的总空间大小而不是数组的元素个数。图上数组的读取结果是20,也就是5*4
同时还可以推测文件写入模式r+的默认起始位置是0
在上述函数中的fwrite后面添加一个ftell()显示偏移量,可见 fwrite函数执行完毕的时候文件的偏移量自动增加到了20字节处
fwrite函数执行完毕的时候文件的偏移量自动增加到了20字节处
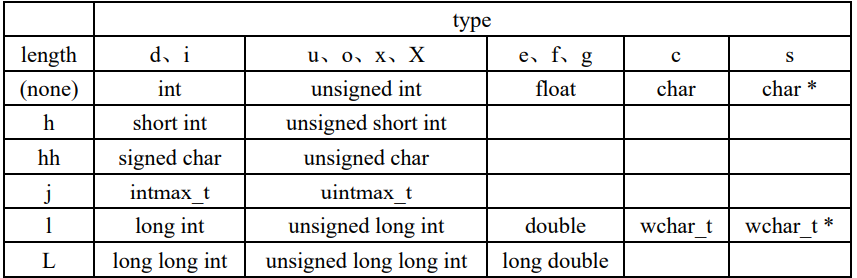
%[flags][width][.precision][length]type |
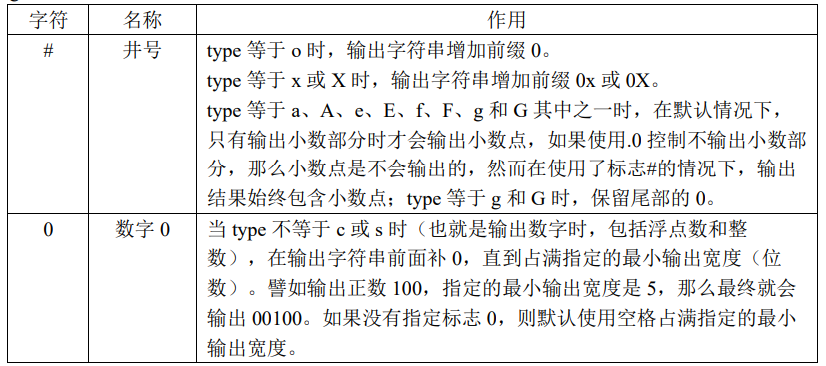
flags:标志,可包含 0 个或多个标志;
width:输出最小宽度,表示转换后输出字符串的最小宽度;
precision:精度,前面有一个点号” . “;
length:长度修饰符;
type:转换类型,指定待转换数据的类型。
type:
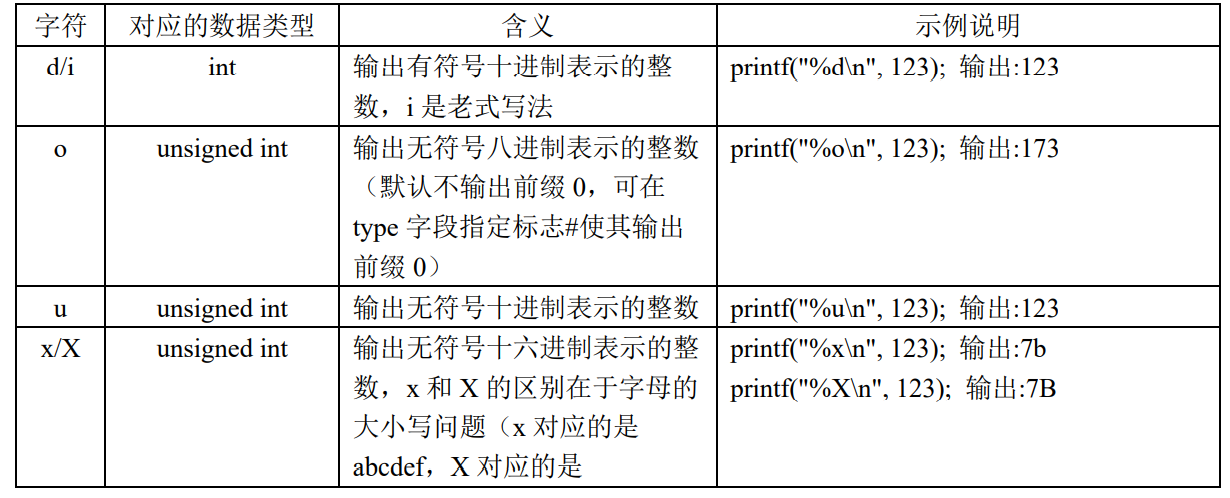
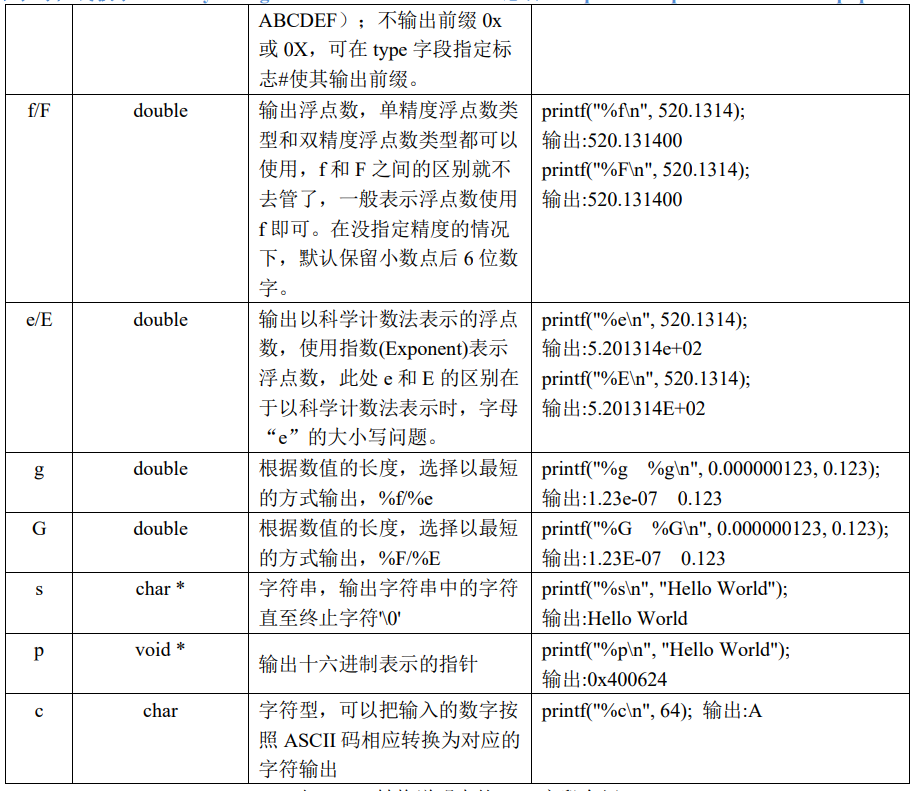
flags

width

precision 精度


length

示例
printf("%hd\n", 12345); //将数据以 short int 类型进行转换 |
|
可以看到,这 3 个格式化输入函数也是可变参函数,它们都有一个共同的参数 format,同样也称为格式 控制字符串,用于指定输入数据如何进行格式转换,与格式化输出函数中的 format 参数格式相似,但也有 所不同。
每个函数除了固定参数之外,还可携带 0 个或多个可变参数。
scanf()函数可将用户输入(标准输入)的数据进行格式化转换;fscanf()函数从 FILE 指针指定文件中读 取数据,并将数据进行格式化转换;sscanf()函数从参数 str 所指向的字符串中读取数据,并将数据进行格式 化转换。
int a, b, c; |
int a, b, c; |
char *str = "5454 hello"; |
[]部分是可选的参数)%[*][width][length]type |
*或**字母 m**,如果添加了星号*,格式化输入函数会按照转换说明的指示读取输 入,但是丢弃输入,意味着不需要对转换后的结果进行存储,所以也就不需要提供相应的指针参数。char *buf; |
width:最大字符宽度;
length:长度修饰符,与格式化输出函数的 format 参数中的 length 字段意义相同。
type:指定输入数据的类型。
type
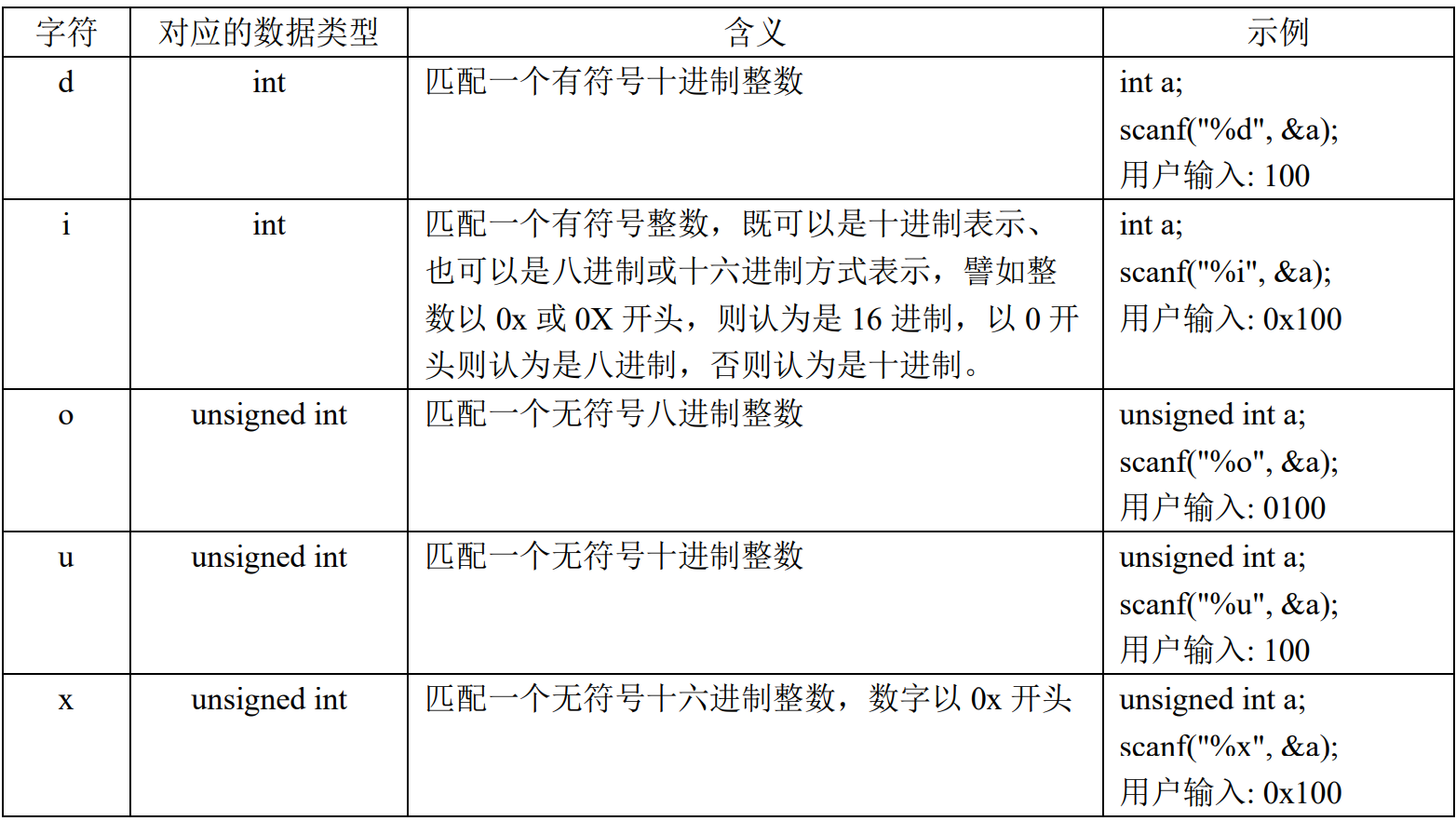
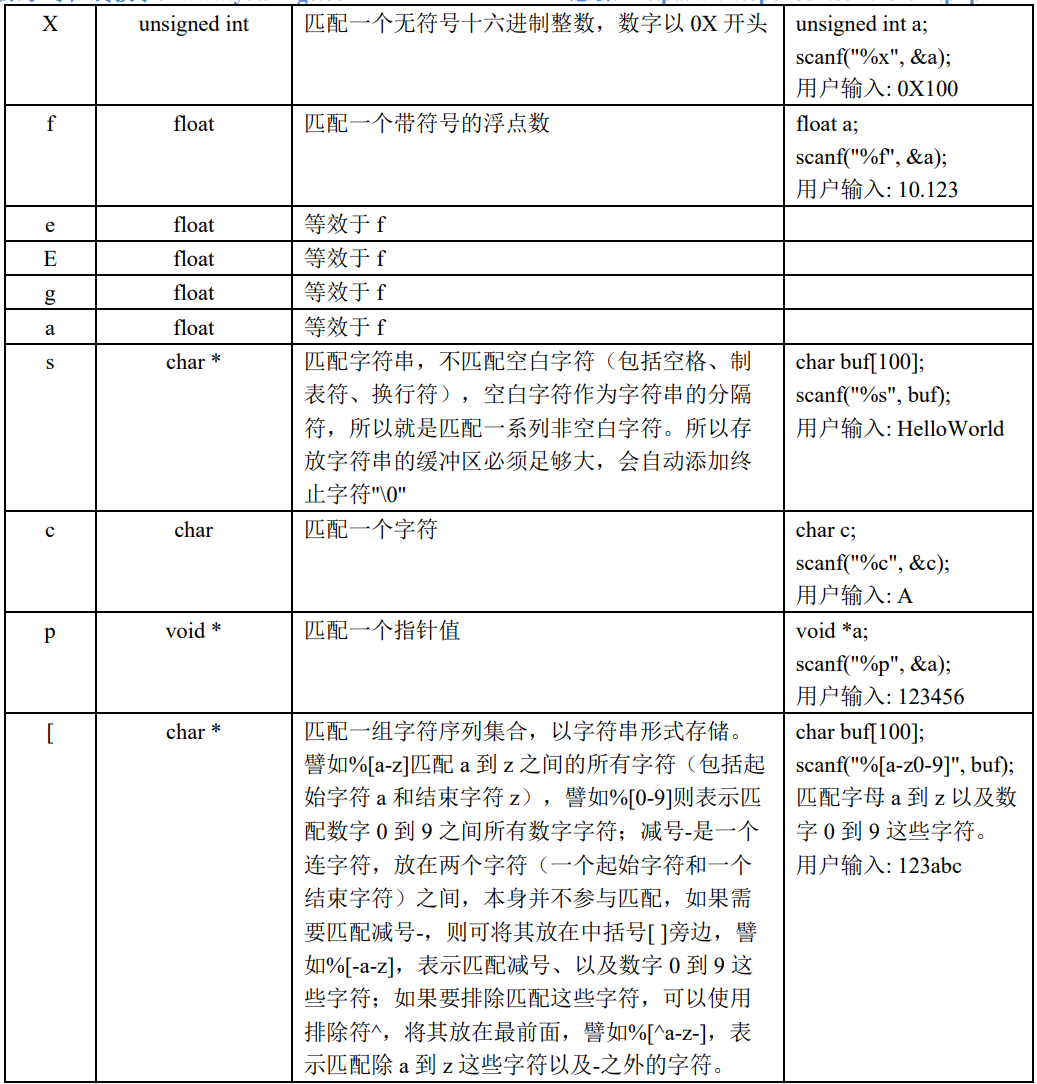
width最大字符长度限制。
scanf("%4s", buf); //匹配字符串,字符串长度不超过 4 个字符 |
scanf("%hd", var); //匹配 short int 类型数据 |
使用例:
|
[]里面的内容的写法,比如想一次性收取所有字母,使用[A-Za-z],连续写即可,数字写0-9,同
*符号)略,详见原子教程《I.MX6U嵌入式Linux C应用编程指南》
fdopen()、 fileno()来完成。
|
对于 fileno()函数来说,根据传入的 FILE 指针得到整数文件描述符,通过返回值得到文件描述符,如果 转换错误将返回-1,并且会设置 errno 来指示错误原因。得到文件描述符之后,便可以使用诸如 read()、write()、 lseek()、fcntl()等文件 I/O 方式操作文件。
fdopen()函数与 fileno()功能相反,给定一个文件描述符,得到该文件对应的 FILE 指针,之后便可以使 用诸如 fread()、fwrite()等标准 I/O 方式操作文件了。参数 mode 与 fopen()函数中的 mode 参数含义相同如下表,若该参数与文件描述符 fd 的访问模式不一致,则会导致调用 fdopen()失败。

|
当混合使用文件 I/O 和标准 I/O 时,需要特别注意缓冲的问题,文件 I/O 会直接将数据写入到内核缓冲 区进行高速缓存,而标准 I/O 则会将数据写入到 stdio 缓冲区,之后再调用 write()将 stdio 缓冲区中的数据写 入到内核缓冲区。
执行结果你会发现,先输出了”write”字符串信息,接着再输出了”print”字符串信息
|
当前目录下不存在 test_file 文件,上述代码中,第一次调用 open 函数新建并打开 test_file 文件,第二次 调用 open 函数再次打开它,新建文件时,文件大小为 0;首先通过文件描述符 fd1 写入 4 个字节数据 (0x11/0x22/0x33/0x44),从文件头开始写;然后再通过文件描述符 fd2 读取 4 个字节数据,也是从文件头 开始读取。假如,内存中只有一份动态文件,那么读取得到的数据应该就是 0x11、0x22、0x33、0x44,如 果存在多份动态文件,那么通过 fd2 读取的是与它对应的动态文件中的数据,那就不是 0x11、0x22、0x33、 0x44,而是读取出 0 个字节数据,因为它的文件大小是 0。
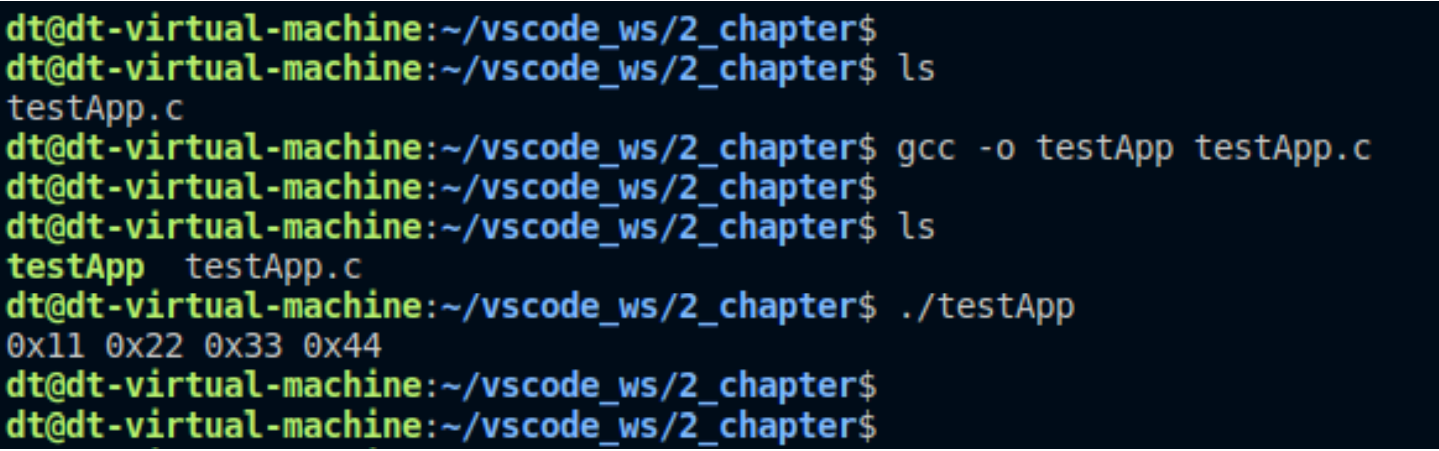
上图中打印显示读取出来的数据是 0x11/0x22/0x33/0x44,所以由此可知,即使多次打开同一个文件,内 存中也只有一份动态文件。
O_APPEND的话,程序将会以不同的文件标识符为准的偏移量分别写入数据,多个文件标识符同时写一个文件的时候,不会互相更新标识符的位置,因此有可能互相覆盖。O_APPEND标志的时候,会自动将偏移量移动到文件尾部,会互相更新,比如一个文件标识符写入的时候会更新另一个文件标识符的写入偏移量。此时多个文件标识符进行读写的时候就不会互相覆盖了
|
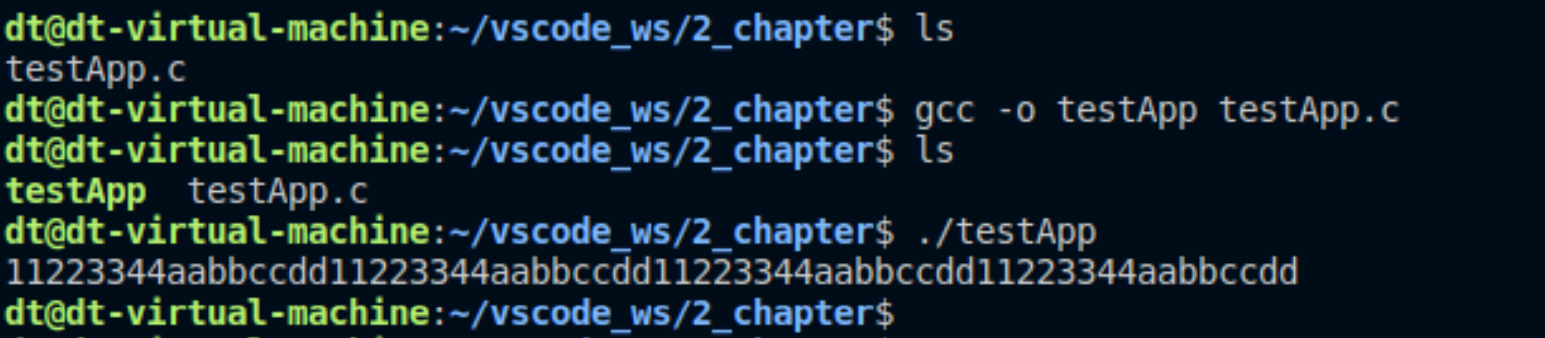
可见,每次fd1和fd2写入的内容都是交替出现的,也就是说一个标识符写入之后会自动更新另一个的偏移量
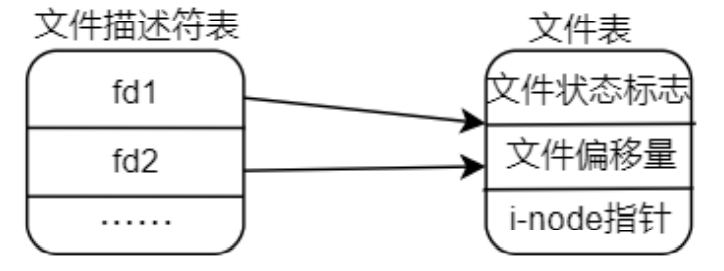
|
|
oldfd:需要被复制的文件描述符。
newfd:指定一个文件描述符(需要指定一个当前进程没有使用到的文件描述符)。
返回值:成功时将返回一个新的文件描述符,也就是手动指定的文件描述符 newfd;如果复制失败将返 回-1,并且会设置 errno 值。
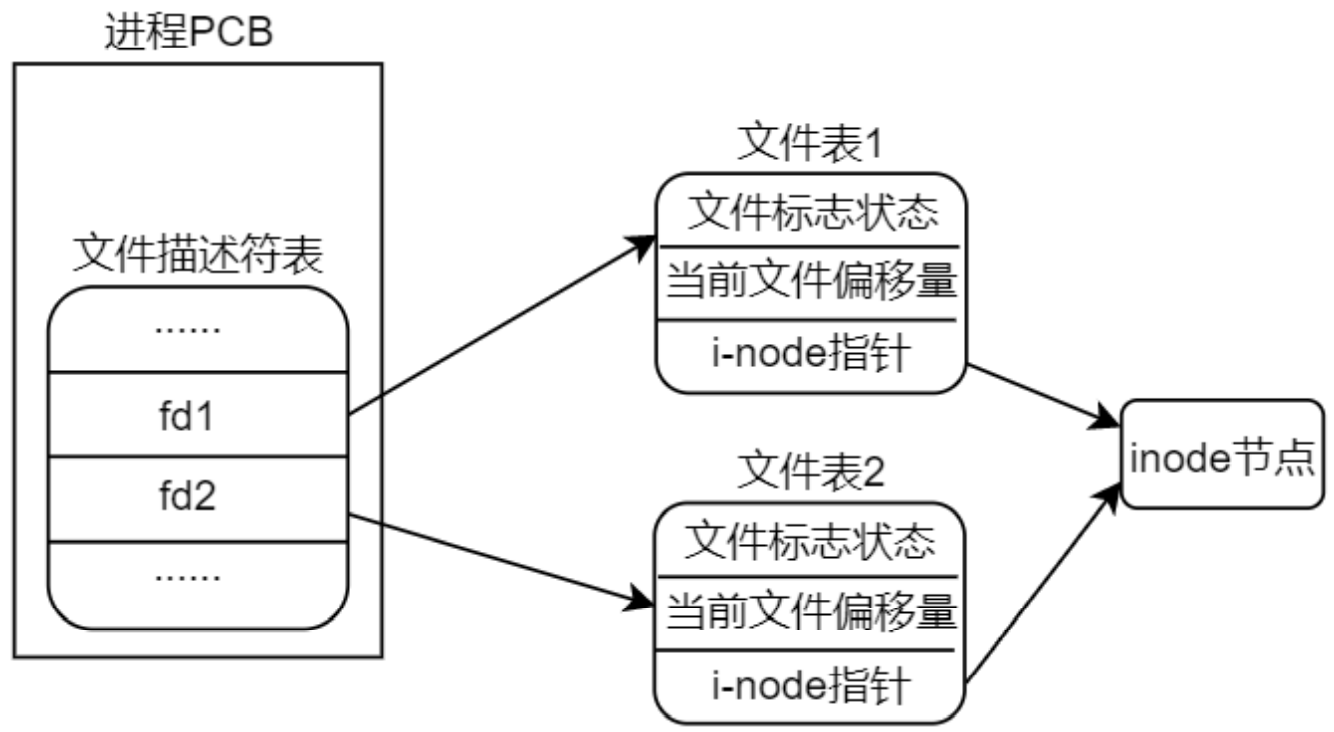
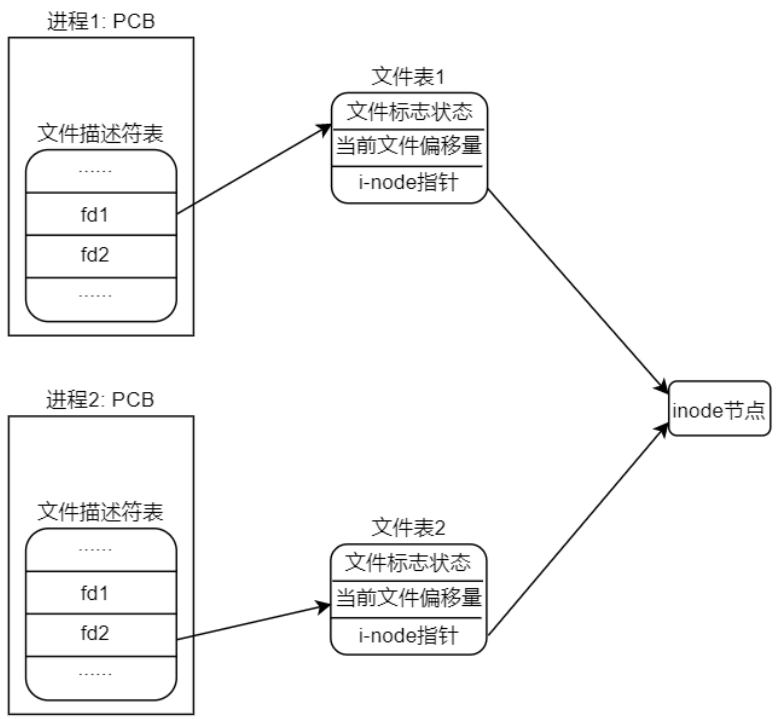
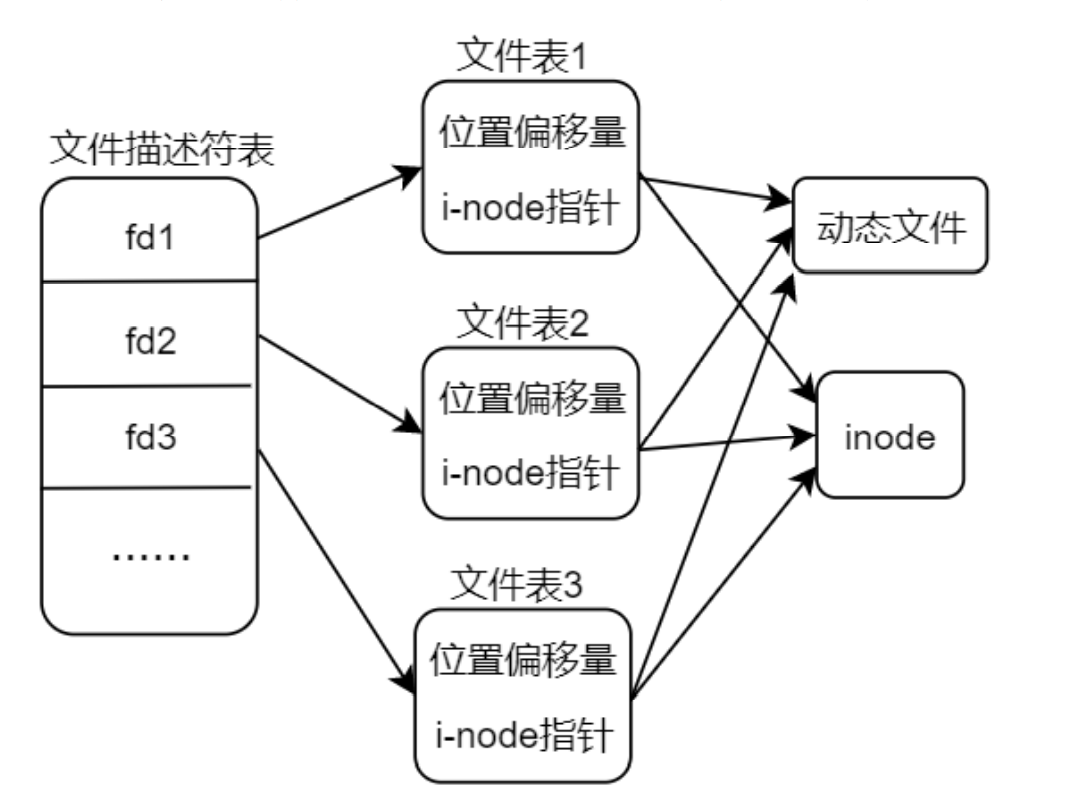
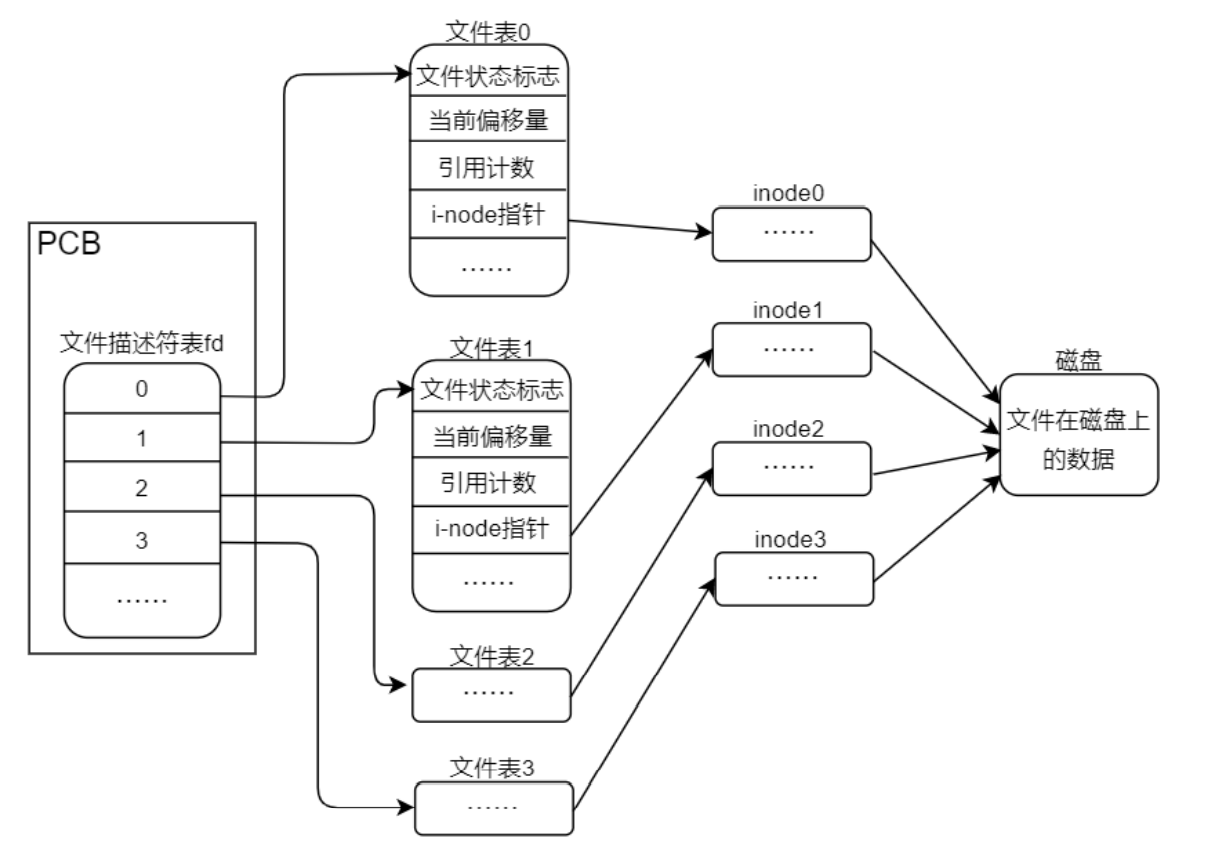
假设有两个独立的进程 A 和进程 B 都对同一个文件进行追加写操作(也就是在文件末尾写入数据), 每一个进程都调用了 open 函数打开了该文件,但未使用 O_APPEND 标志,此时,各数据结构之间的关系 如图 3.8.2 所示。每个进程都有它自己的进程控制块 PCB,有自己的文件表(意味着有自己独立的读写位置 偏移量),但是共享同一个 inode 节点(也就是对应同一个文件)。假定此时进程 A 处于运行状态,B 未处 于等待运行状态,进程 A 调用了 lseek 函数,它将进程 A 的该文件当前位置偏移量设置为 1500 字节处(假 设这里是文件末尾),刚好此时进程 A 的时间片耗尽,然后内核切换到了进程 B,进程 B 执行 lseek 函数, 也将其对该文件的当前位置偏移量设置为 1500 个字节处(文件末尾)。然后进程 B 调用 write 函数,写入 了 100 个字节数据,那么此时在进程 B 中,该文件的当前位置偏移量已经移动到了 1600 字节处。B 进程时 间片耗尽,内核又切换到了进程 A,使进程 A 恢复运行,当进程 A 调用 write 函数时,是从进程 A 的该文 件当前位置偏移量(1500 字节处)开始写入,此时文件 1500 字节处已经不再是文件末尾了,如果还从 1500 字节处写入就会覆盖进程 B 刚才写入到该文件中的数据。
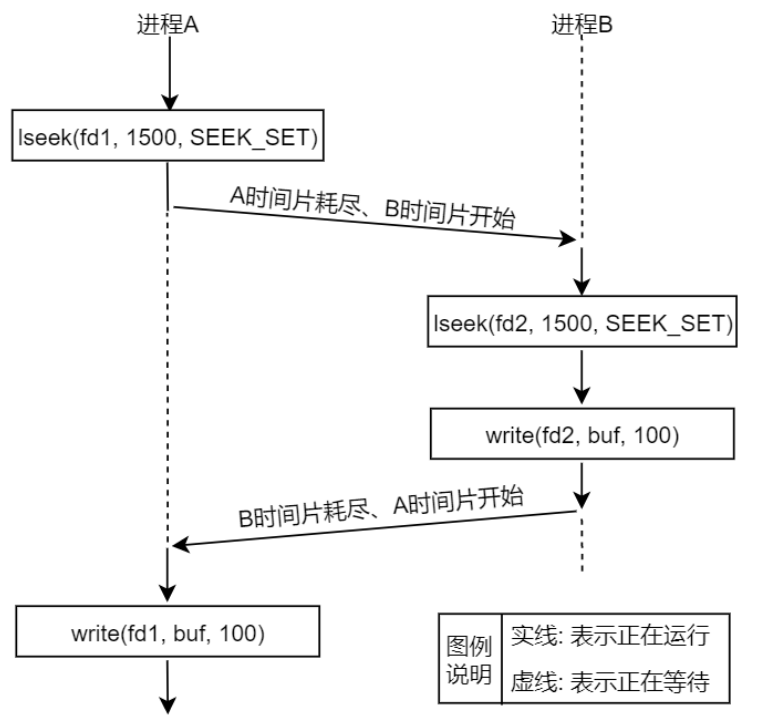
以上给大家所描述的这样一种情形就属于竞争状态(也成为竞争冒险),操作共享资源的两个进程(或 线程),其操作之后的所得到的结果往往是不可预期的,因为每个进程(或线程)去操作文件的顺序是不可 预期的,即这些进程获得 CPU 使用权的先后顺序是不可预期的,完全由操作系统调配,这就是所谓的竞争 状态。
所谓原子操作,是有多步操作组成的一个操作,原子操作要么一步也不执行,一旦执行,必须要执行完所有 步骤,不可能只执行所有步骤中的一个子集。
使用O_APPEND实现原子操作
使用pread()和pwrite()进行操作
|
fd、buf、count 参数与 read 或 write 函数意义相同。
offset:表示当前需要进行读或写的位置偏移量。
返回值:返回值与 read、write 函数返回值意义一样。
虽然 pread(或 pwrite)函数相当于 lseek 与 pread(或 pwrite)函数的集合,但还是有下列区别:
**fcntl()和ioctl()**详见原子的《I.MX6U嵌入式Linux C应用编程指南》
|
这两个函数的区别在于:ftruncate()使用文件描述符 fd 来指定目标文件,而 truncate()则直接使用文件路 径 path 来指定目标文件,其功能一样。
这两个函数都可以对文件进行截断操作,将文件截断为参数 length 指定的字节长度,什么是截断?如 果文件目前的大小大于参数 length 所指定的大小,则多余的数据将被丢失,类似于多余的部分被“砍”掉 了;如果文件目前的大小小于参数 length 所指定的大小,则将其进行扩展,对扩展部分进行读取将得到空字 节”\0”。
使用 ftruncate()函数进行文件截断操作之前,必须调用 open()函数打开该文件得到文件描述符,并且必 须要具有可写权限,也就是调用 open()打开文件时需要指定 O_WRONLY 或 O_RDWR。
调用这两个函数并不会导致文件读写位置偏移量发生改变,所以截断之后一般需要重新设置文件当前 的读写位置偏移量,以免由于之前所指向的位置已经不存在而发生错误(譬如文件长度变短了,文件当前所 指向的读写位置已不存在)。
简单的实例
|
|
pathname:字符串类型,用于标识需要打开或创建的文件,可以包含路径(绝对路径或相对路径)信 息,譬如:”./src_file”(当前目录下的 src_file 文件)、”/home/dengtao/hello.c”等;如果 pathname 是一个符号 链接,会对其进行解引用。
flags:调用 open 函数时需要提供的标志,包括文件访问模式标志以及其它文件相关标志,这些标志使 用宏定义进行描述,都是常量,open 函数提供了非常多的标志,我们传入 flags 参数时既可以单独使用某一 个标志,也可以通过位或运算(|)将多个标志进行组合。
| 标志 | 用途 | 说明 |
|---|---|---|
| O_WRONLY | 只写 | |
| O_RDONLY | 只读 | |
| O_RDWR | 可读可写 | 这三个是文件访问权限标志,传入的 flags 参数中必须要包含其中一种标 志,而且只能包含一种 |
| O_CREAT | 如果地址指向的文件不存在就创建文件 | 使用此标志时,调用 open 函数需要 传入第 3 个参数 mode,参数 mode 用 于指定新建文件的访问权限,稍后将 对此进行说明。 open 函数的第 3 个参数只有在使用 了 O_CREAT 或 O_TMPFILE 标志 时才有效。 |
| O_DIRECTORY | 如果地址指向的是目录,返回调用失败 | |
| O_EXCL | 此标志一般结合 O_CREAT 标志一起使用, 用于专门创建文件。 在 flags 参数同时使用到了 O_CREAT 和 O_EXCL 标志的情况下,如果 pathname 参数 指向的文件已经存在,则 open 函数返回错 误。 | 可以用于测试一个文件是否存在,如 果不存在则创建此文件,如果存在则 返回错误,这使得测试和创建两者成 为一个原子操作;关于原子操作,在 后面的内容当中将会对此进行说明。 |
| O_NOFOLLOW | 如果 pathname 参数指向的是一个符号链接, 将不对其进行解引用,直接返回错误。 | 不加此标志情况下,如果 pathname 参数是一个符号链接,会对其进行解引用,加了之后会对符号链接直接返回错误。 |
|标志添加大于一个,比如open("./src_file", O_RDONLY) //单独使用某一个标志 |
前面的博客中已经详细介绍过了,略
|
fd:文件描述符。关于文件描述符,前面已经给大家进行了简单地讲解,这里不再重述!我们需要将进 行写操作的文件所对应的文件描述符传递给 write 函数。
buf:指定写入数据对应的缓冲区。
count:指定写入的字节数。
返回值:如果成功将返回写入的字节数(0 表示未写入任何字节),如果此数字小于 count 参数,这不是错误,譬如磁盘空间已满,可能会发生这种情况;如果写入出错,则返回-1。
|
|
fd:文件描述符,需要关闭的文件所对应的文件描述符。
返回值:如果成功返回 0,如果失败则返回-1。
在 Linux 系统中,当一个进程终止时,内核会自动关闭它打开 的所有文件,也就是说在我们的程序中打开了文件,如果程序终止退出时没有关闭打开的文件,那么内核会 自动将程序中打开的文件关闭。很多程序都利用了这一功能而不显式地用 close 关闭打开的文件。
|
fd:文件描述符。
offset:偏移量,以字节为单位。
whence:用于定义参数 offset 偏移量对应的参考值,该参数为下列其中一种(宏定义):
成功将返回从文件头部开始算起的位置偏移量(字节为单位),也就是当前的读写位置;发生 错误将返回-1。可以用此函数获取文件此时的偏移量
磁盘空间包括两个部分,一个是真正存储文件的区域,另一个是存储文件inode的区域(inode见前面的博客)
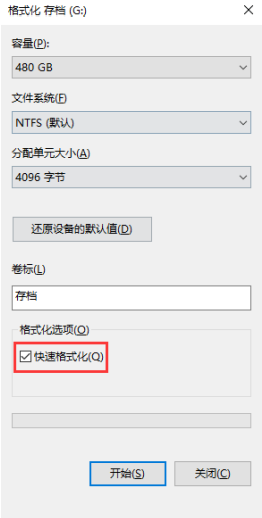
windows的快速格式化不会真正删除存储问文件内容的区域,只是删除了inode表的区域
系统找到这个文件名所对应的 inode 编号;
通过 inode 编号从 inode table 中找到对应的 inode 结构体;
根据 inode 结构体中记录的信息,确定文件数据所在的 block,并读出数据。
文件打开的时候内核会申请一段内存(一段缓冲区),并且将静态文件的数 据内容从磁盘这些存储设备中读取到内存中进行管理、缓存(也把内存中的这份文件数据叫做动态文件、内 核缓冲区)。打开文件后,以后对这个文件的读写操作,都是针对内存中这一份动态文件进行相关的操作。
因为磁盘、硬盘、U 盘等存储设备基本都是 Flash 块设备,因为块设备硬件本身有读写限制等特征,块 设备是以一块一块为单位进行读写的(一个块包含多个扇区,而一个扇区包含多个字节),一个字节的改动 也需要将该字节所在的 block 全部读取出来进行修改,修改完成之后再写入块设备中,所以导致对块设备的 读写操作非常不灵活;而内存可以按字节为单位来操作,而且可以随机操作任意地址数据,非常地很灵活, 所以对于操作系统来说,会先将磁盘中的静态文件读取到内存中进行缓存,读写操作都是针对这份动态文 件,而不是直接去操作磁盘中的静态文件,不但操作不灵活,效率也会下降很多,因为内存的读写速率远比 磁盘读写快得多。
在 Linux 系统中,内核会为每个进程(关于进程的概念,这是后面的内容,我们可以简单地理解为一个 运行的程序就是一个进程,运行了多个程序那就是存在多个进程)设置一个专门的数据结构用于管理该进 程,譬如用于记录进程的状态信息、运行特征等,我们把这个称为进程控制块(Process control block,缩写 PCB)。
略,详见原子教程pdf
进程正常退出除了可以使用 return 之外,还可以使用exit()、_exit()以及_Exit()
_exit()
调用_exit()函数会 清除其使用的内存空间,并销毁其在内核中的各种数据结构,关闭进程的所有文件描述符,并结束进程、将 控制权交给操作系统。
|
其中的status含义与上面return的相同,0代表正常,其他数值代表异常
_Exit()和_exit()等价,不再介绍
|
exit()是一个标准 C 库函数,而_exit()和_Exit()是系统调用。
|
什么是空洞文件(hole file)?在上一章内容中,笔者给大家介绍了 lseek()系统调用,使用 lseek 可以修 改文件的当前读写位置偏移量,此函数不但可以改变位置偏移量,并且还允许文件偏移量超出文件长度,这 是什么意思呢?譬如有一个 test_file,该文件的大小是 4K(也就是 4096 个字节),如果通过 lseek 系统调 用将该文件的读写偏移量移动到偏移文件头部 6000 个字节处,大家想一想会怎样?如果笔者没有提前告诉 大家,大家觉得不能这样操作,但事实上 lseek 函数确实可以这样操作。
接下来使用 write()函数对文件进行写入操作,也就是说此时将是从偏移文件头部 6000 个字节处开始写 入数据,也就意味着 4096~6000 字节之间出现了一个空洞,因为这部分空间并没有写入任何数据,所以形 成了空洞,这部分区域就被称为文件空洞,那么相应的该文件也被称为空洞文件。
文件空洞部分实际上并不会占用任何物理空间,直到在某个时刻对空洞部分进行写入数据时才会为它 分配对应的空间,但是**空洞文件形成时,逻辑上该文件的大小是包含了空洞部分的大小的**,这点需要注意。
空洞文件对多线程共同操作文件是及其有用的,有时候我们创建 一个很大的文件,如果单个线程从头开始依次构建该文件需要很长的时间,有一种思路就是将文件分为多 段,然后使用多线程来操作,每个线程负责其中一段数据的写入
|
上面的代码从文件的4k位置开始,一次写入1k,写入4次。
下面查看文件的大小
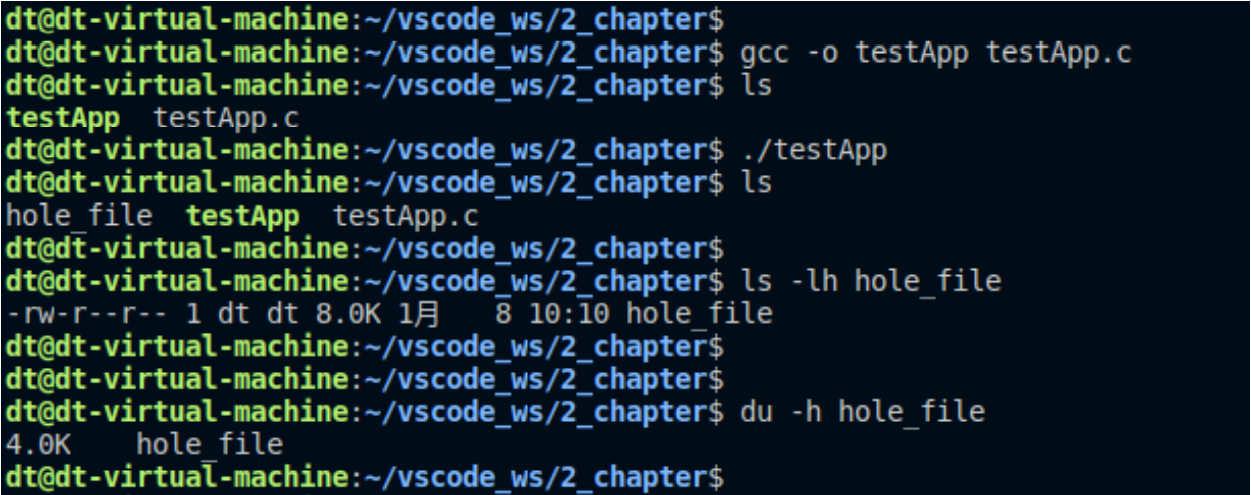
利用ls察看文件大小的时候,虽然文件只有4k有数据,但是文件大小查出来逻辑大小,也就是8k。
但是使用du查看的时候,只有文件占用的实际存储的大小,也就是4k。
在上一章给大家讲解 open 函数的时候介绍了一些 open 函数的 flags 标志,譬如 O_RDONLY、 O_WRONLY、O_CREAT、O_EXCL 等,本小节再给大家介绍两个标志,分别是 O_APPEND 和 O_TRUNC, 接下来对这两个标志分别进行介绍。
|
|
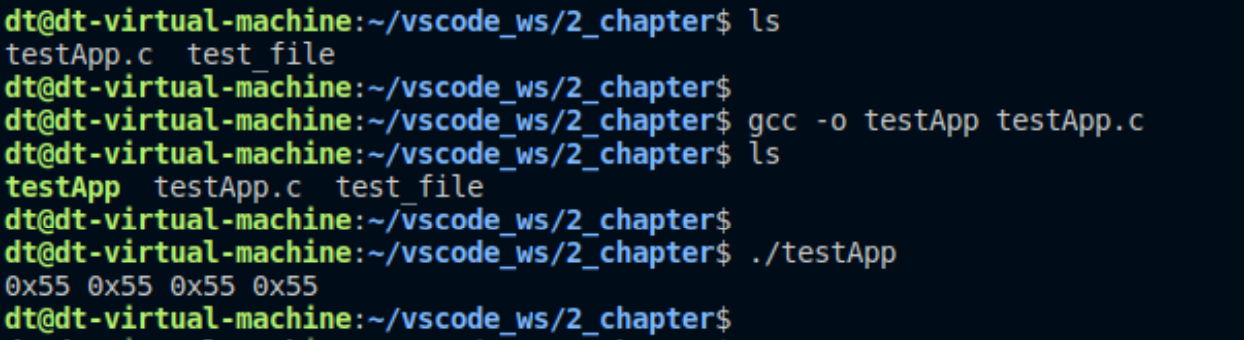
通过控制台可知,读出的内容确实是最后四个字节为0x55
O_APPEND 标志并不会影响读文件,当读取文件时,O_APPEND 标志并不会影响读位置偏移量,即使使用了 O_APPEND 标志,读文件位置偏移量默认情况下依然是文件头,关于这个问题大家可以自己进行测试,编程是一个实践 性很强的工作,有什么不能理解的问题,可以自己编写程序进行测试。
使用 lseek 函数来改变 write()时的写位置偏移量,其实这种做法并不会成功,这就是笔 者给大家提的第二个细节,使用了 O_APPEND 标志,即使是通过 lseek 函数也是无法修改写文件时对应的 位置偏移量(注意笔者这里说的是写文件,并不包括读),写入数据依然是从文件末尾开始,lseek 并不会 该变写位置偏移量
测试
|
此处函数不对文件偏移位置进修修改的前提下,在文件写入4次, 0xXX的字符,观察效果

可以看出,在文件最后多出了四个字符串,可见每次写入的时候,文件的偏移量都自动移动到了文件的最后,即使文件在这个过程中并没有被保存。
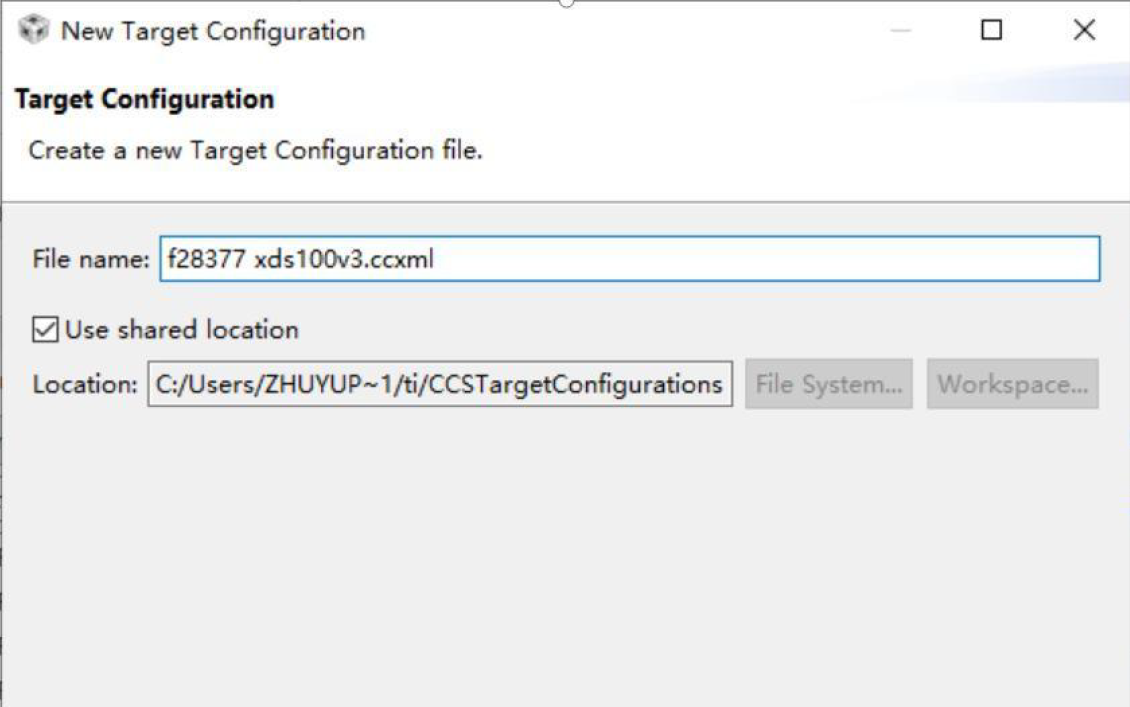
此文档仅作为官方手册的补充
打开后,选择
然后
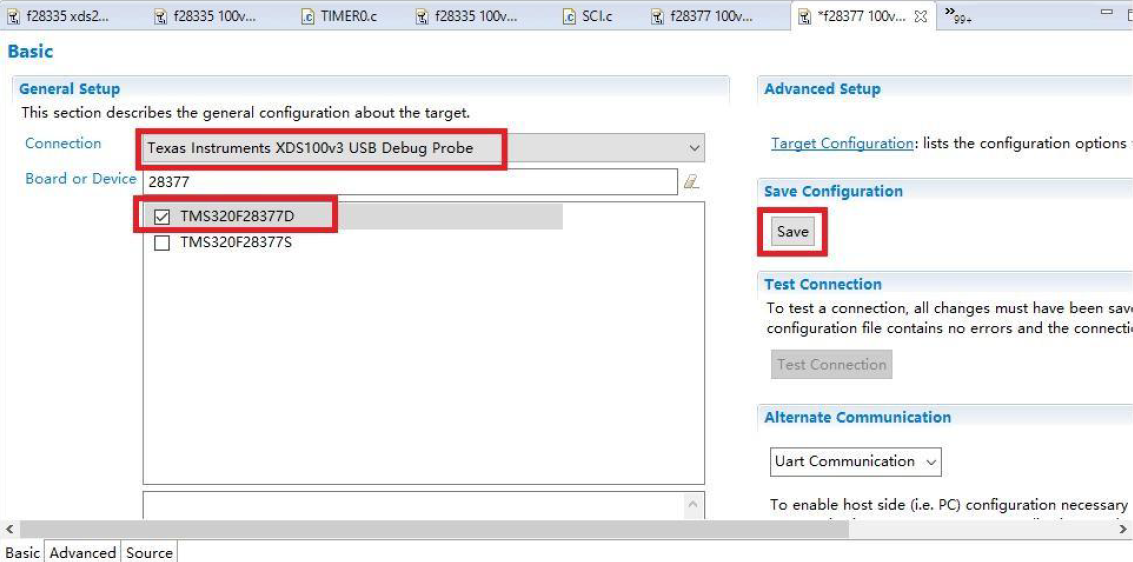
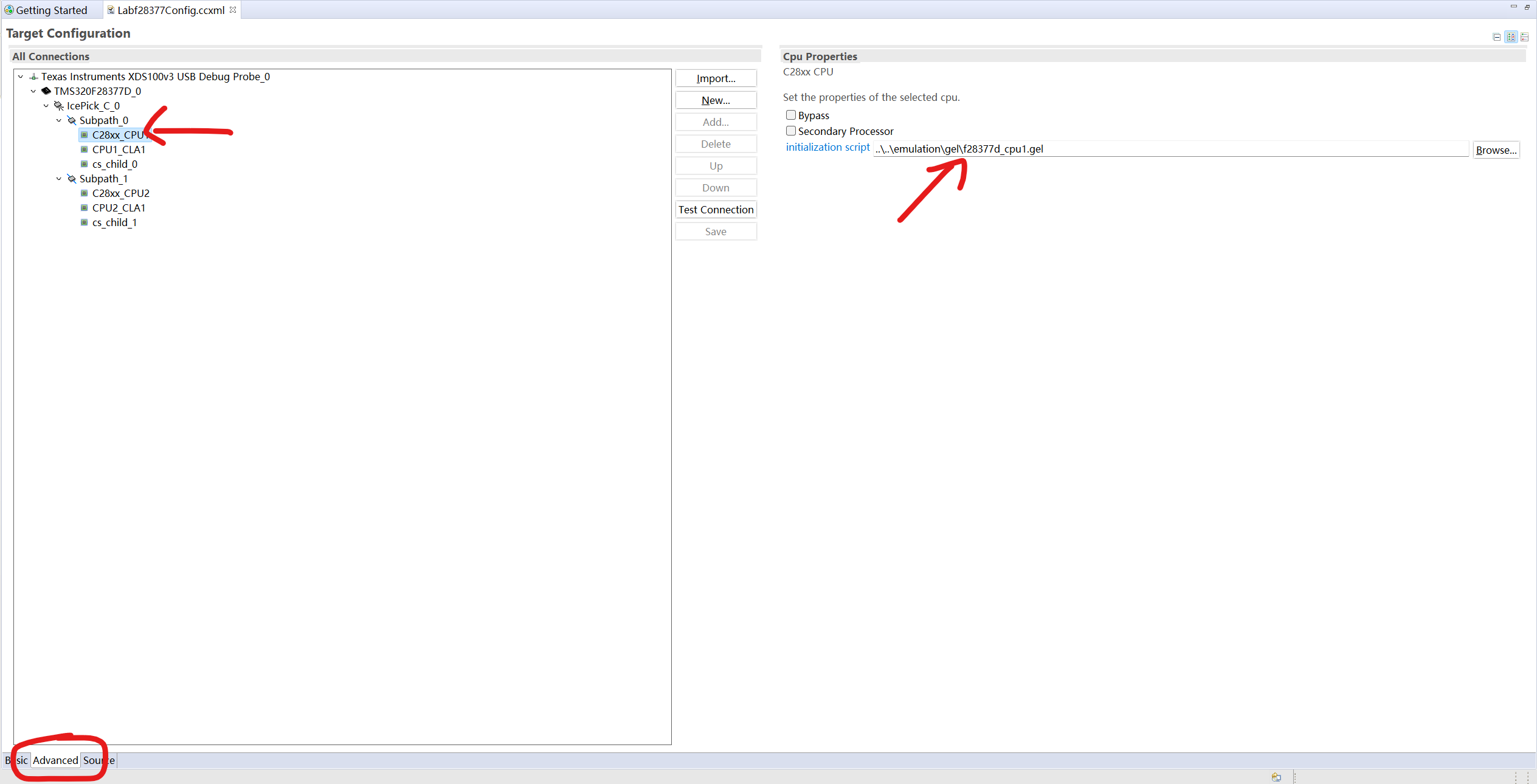
此处一般不需要修改
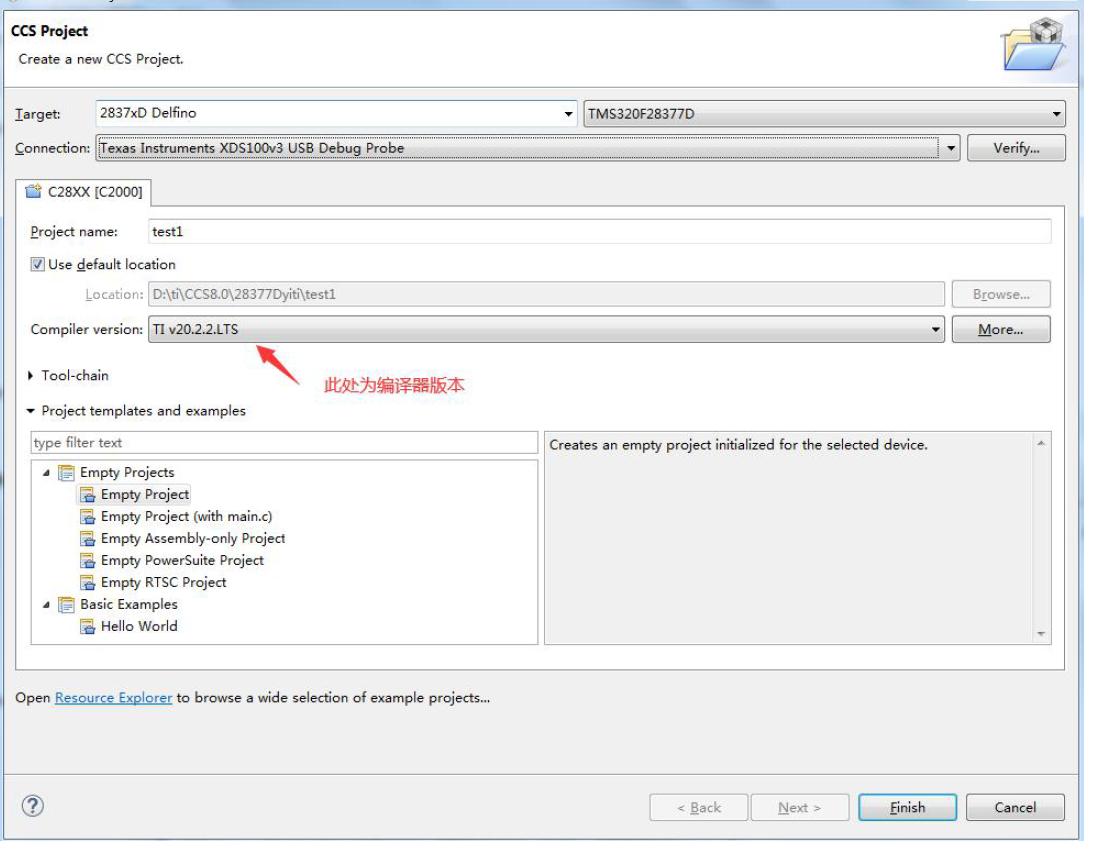
main()函数可能没法运行gcc -c 指的是只把源码编译为目标文件而不进行链接。如果GCC不带-C参数,编译一个源代码文件(test.c)。那么会自动将编译和链接一步完成,并生成可执行文件。对于多个文件,需要先编译成中间目标文件(一般是.o文件),在链接成可执行文件,一般习惯目标文件都是以.o后缀,也没有硬性规定可执行文件不能用.o文件。gcc -o指的是output_filename,确定输出文件的名称为output_filename,同时这个名称不能和源文件同名。如果不给出这个选项,gcc就给出预设的可执行文件a.out。使用 GCC 编译器在 Linux 进行 C 语言编译,通过在终端执行 gcc 命 令来完成 C 文件的编译,如果我们的工程只有一两个 C 文件还好,需要输入的命令不多,当文 件有几十、上百甚至上万个的时候用终端输入 GCC 命令的方法显然是不现实的。如果我们能够 编写一个文件,这个文件描述了编译哪些源码文件、如何编译那就好了,每次需要编译工程的 时只需要使用这个文件就行了。这种问题怎么可能难倒聪明的程序员,为此提出了一个解决大 工程编译的工具:make,描述哪些文件需要编译、哪些需要重新编译的文件就叫做 Makefile, Makefile 就跟脚本文件一样,Makefile 里面还可以执行系统命令。使用的时候只需要一个 make命令即可完成整个工程的自动编译,极大的提高了软件开发的效率。
在 Linux 下用的最多的是 GCC 编译器,这是个没有 UI 的编译器,因此 Makefile 就需要我们自己来编写了。
//main.c |
//input.c |
|
|
|
gcc main.c calcu.c input.c -o main |
上面命令的意思就是使用 gcc 编译器对 main.c、calcu.c 和 input.c 这三个文件进行编译,编 译生成的可执行文件叫做 main。

执行程序用到的命令是./main,含义是执行当前目录下的main文件
可以看出我们的代码按照我们所设想的工作了,使用命令“gcc main.c calcu.c input.c -o main” 看起来很简单是吧,只需要一行就可以完成编译,但是我们这个工程只有三个文件啊!如果几 千个文件呢?再就是如果有一个文件被修改了,使用上面的命令编译的时候所有的文件都会重新编译,如果工程有几万个文件(Linux 源码就有这么多文件!),想想这几万个文件编译一次 所需要的时间就可怕。最好的办法肯定是哪个文件被修改了,只编译这个被修改的文件即可, 其它没有修改的文件就不需要再次重新编译了,为此我们改变我们的编译方法,如果第一次编译工程,我们先将工程中的文件都编译一遍,然后后面修改了哪个文件就编译哪个文件,命令 如下:
gcc -c main.c |
-c选项的意思是将程序编译为.o文件但是不链接为最终的可执行文件,最后一句gcc main.o input.o calcu.o -o main的意思是将三个.o文件链接为一个可执行文件gcc -c calcu.c |

Makefile文件:
main: main.o input.o calcu.o |
上述代码中所有行首需要空出来的地方一定要使用TAB键!不要使用空格键!这是 Makefile 的语法要求
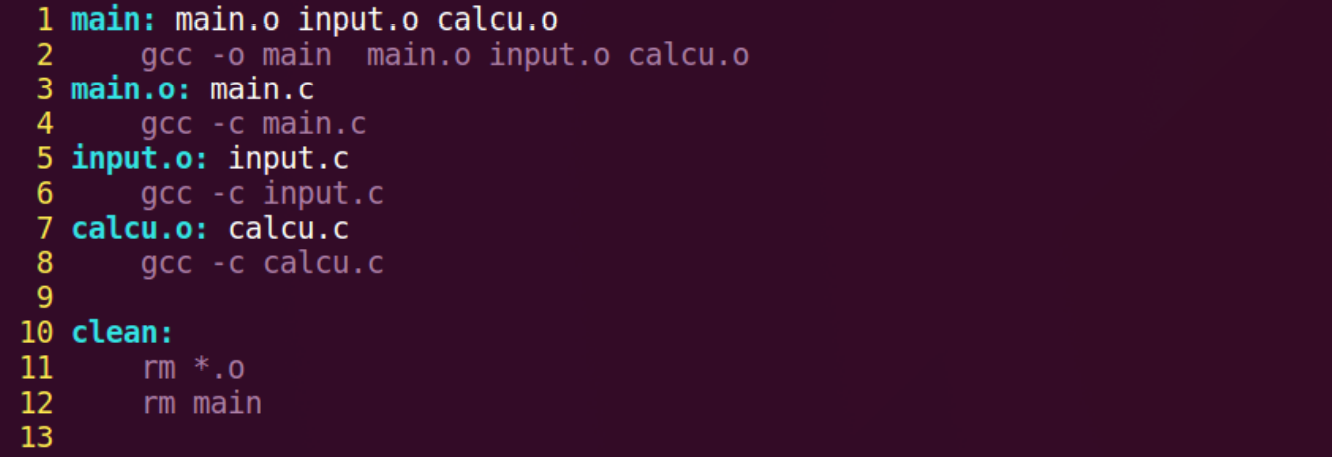
Makefile 编写好以后我们就可以使用 make 命令来编译我们的工程了,直接在命令行中输入make即可,make 命令会在当前目录下查找是否存在Makefile这个文件,如果存在的 话就会按照 Makefile 里面定义的编译方式进行编译
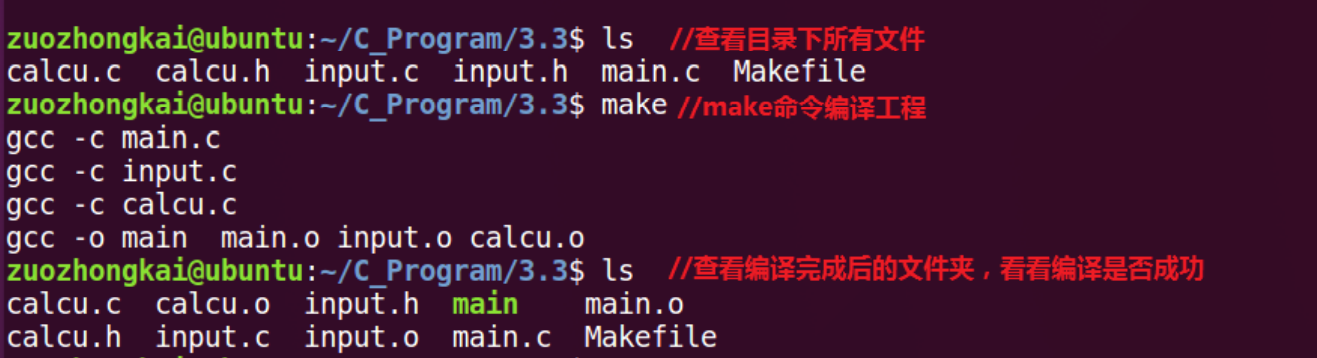
MakeFile中一般存在的错误
set noexpandtab此时修改一下input.c文件,重新编译看结果

可以看出因为我们修改了 input.c 这个文件,所以 input.c 和最后的可执行文 件 main 重新编译了,其它没有修改过的文件就没有编译。

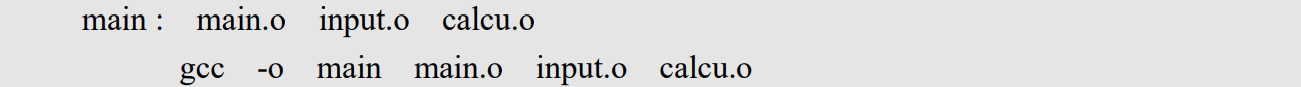
main: main.o input.o calcu.o |
make clean,执行以后就会删 除当前目录下所有的.o 文件以及 main,因此 clean 的功能就是完成工程的清理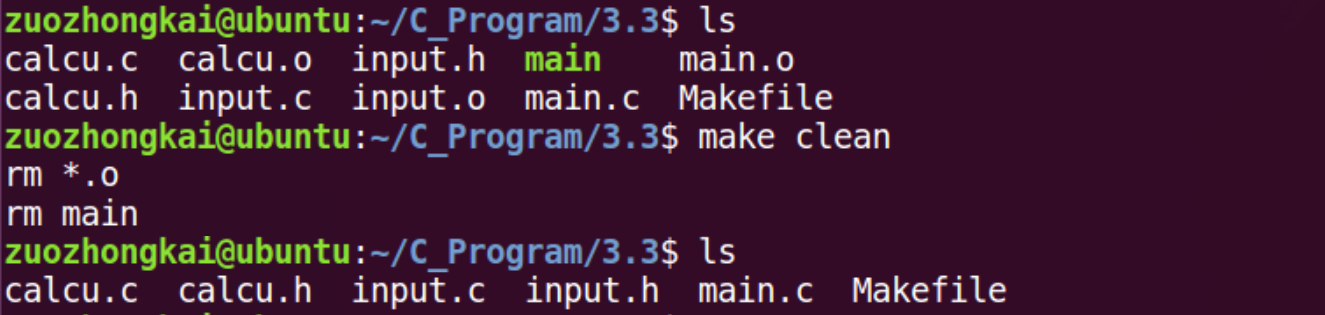
总结一下Makefile的编译过程
这就是 make 的执行过程,make 工具就是在 Makefile 中一层一层的查找依赖关系,并执行相应的命令。
Makefile 中的变量都是字符串
实例
#Makefile 变量的使用 |
Makefile 中可以写注释,注释开头要 用符号“#”
变量的引用方法是$(变量名)
不同赋值符号的区别
=name = zzk |
此时输出的是zuozhongkai,意味着变量的内容随着变量的值更新而更新
@的意思是使得make在执行的过程中输出执行过程,否则不会输出
幅值符:=
=改为:=,则可见输出还是”zzk”,因为:=在幅值的时候不会采用变量修改后的值幅值符?=
curname ?= zuozhongkai的意思是,假如curname前面没有被赋值,那么此变量就是“zuozhongkai”, 如果前面已经赋过值了,那么就使用前面赋的值。幅值符+=
Makefile 中的变量是字符串,有时候我们需要给前面已经定义好的变量添加一些字符串进 去,此时就要使用到符号“+=”,比如
objects = main.o inpiut.o和objects += calcu.o执行完之后,objects就变成了main.o input.o calcu.o
自动匹配
模式规则中,至少在规则的目标定定义中要包涵%,否则就是一般规则,目标中的% 表示对文件名的匹配,%表示长度任意的非空字符串,比如“%.c”就是所有的以.c 结尾的 文件,类似与通配符,a.%.c 就表示以 a.开头,以.c 结束的所有文件。
当“%”出现在目标中的时候,目标中“%”所代表的值决定了依赖中的“%”值,比如%.o : %.c中的%代表的是同样的内容
前面的代码可以修改如下:
objects = main.o input.o calcu.o |

objects = main.o input.o calcu.o |
上面的代码中,$<代表依赖文件(.c)的一系列集合
上述规则中并没有创建文件 clean 的命令,因此工作目录下永远都不会存在文件 clean,当 我们输入“make clean”以后,后面的“rm *.o”和“rm main”总是会执行。可是如果我们“手贱”,在工作目录下创建一个名为“clean”的文件,那就不一样了,当执行“make clean”的时 候,规则因为没有依赖文件,所以目标被认为是最新的,因此后面的 rm 命令也就不会执行,我 们预先设想的清理工程的功能也就无法完成。为了避免这个问题,我们可以将 clean 声明为伪 目标,声明方式如下:
.PHONY : clean |
objects = main.o input.o calcu.o |
语法
<条件关键字> |
和
<条件关键字> |
条件关键字的组成
ifeq和ifneq,判断的是是否相等和是否不等ifeq (<参数 1>, <参数 2>) |
ifdef和ifndefifdef <变量名> |
如果“变量名”的值非空,那么表示表达式为真,否则表达式为假。“变量名”同样可以是 一个函数的返回值。ifndef 用法类似,但是含义用户 ifdef 相反。
$(函数名 参数集合) |
${函数名 参数集合} |
$(subst <from>,<to>,<text>) |
$(subst zzk,ZZK,my name is zzk) |
$(patsubst <pattern>,<replacement>,<text>) |
%代表的字符串的内容不变$(patsubst %.c,%.o,a.c b.c c.c) |
a.c b.c c.c中的所有符合%.c的字符串,替换为%.o,替换完成以后的字 符串为“a.o b.o c.o”,注意此时a,b和c是不变的。$(dir <names…>) |
$(dir </src/a.c>) |
$(notdir <names…>) |
$(notdir </src/a.c>) |
$(foreach <var>, <list>,<text>) |
$(wildcard PATTERN…) |
比如
$(wildcard *.c) |
上面的代码是用来获取当前目录下所有的.c 文件,类似“%”。
使用例
(文件夹下有a.c, b.c和c.c三个文件)
#!/bin/bash |
输出

http://www.diskgenius.cn/download.php
然后此处按下delete即可
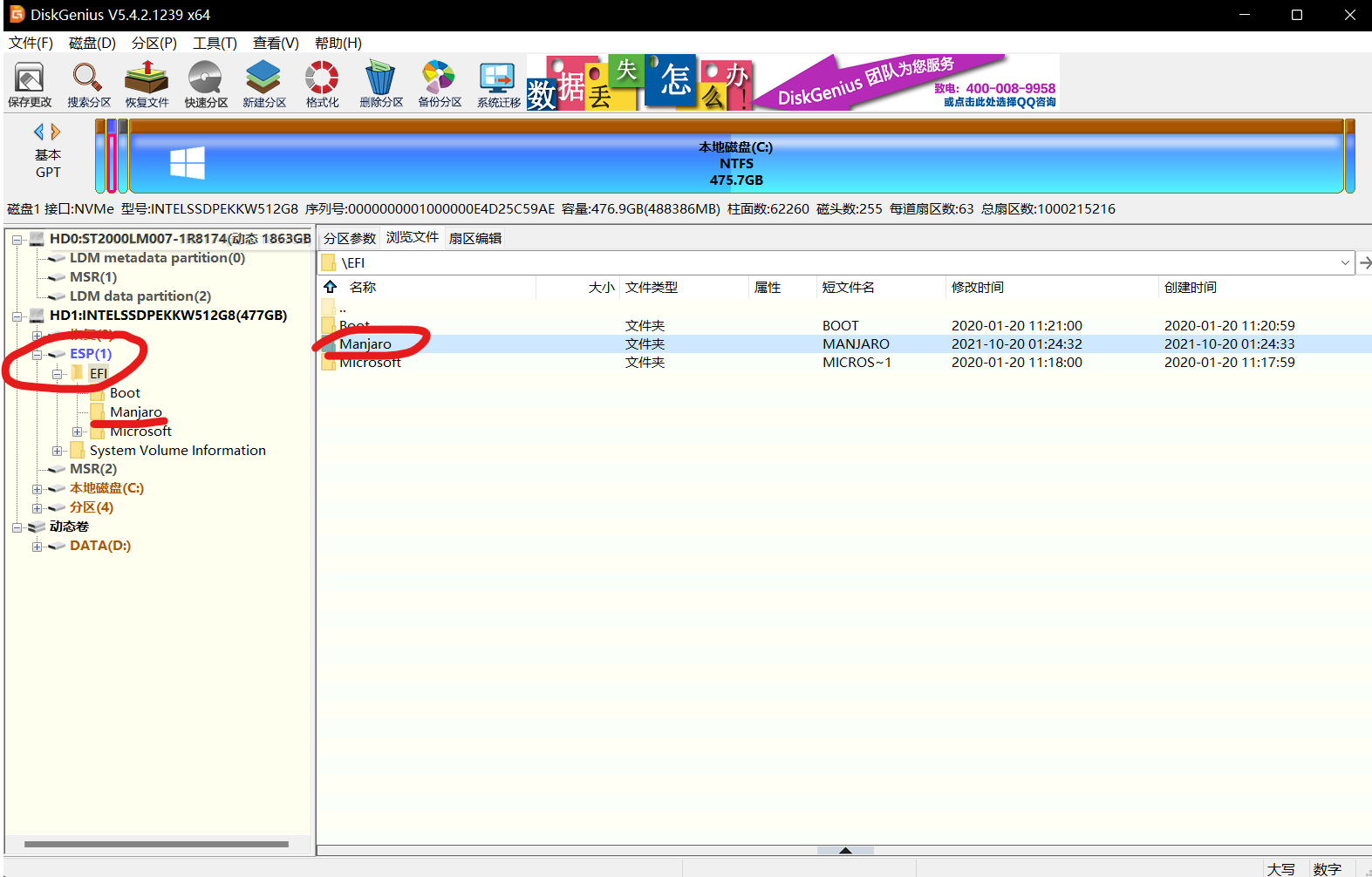
可见启动引导项中已经没有了刚才删除的Manjaro选项