Linux进程
int main(int argc, char *argv[])
|
进程
进程是一个动态过程,而非静态文件,它是程序的一次运行过程,当应用程序被加载到内存中运行之后 它就称为了一个进程,当程序运行结束后也就意味着进程终止,这就是进程的一个生命周期。
Linux 系统下的每一个进程都有一个进程号(processID,简称 PID),进程号是一个正数,用于唯一标 识系统中的某一个进程。在 Ubuntu 系统下执行 **ps -aux **命令可以查到系统中进程相关的一些信息,包括每个进程 的进程号
通过系统调用 getpid()来获取本进程的进程号
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
|
- 还可以使用 getppid()系统调用获取父进程的进程号
进程的环境变量
每一个进程都有一组与其相关的环境变量,这些环境变量以字符串形式存储在一个字符串数组列表中, 把这个数组称为环境列表。其中每个字符串都是以“名称=值(name=value)”形式定义
在 shell 终端下可以使用 env 命令查看到 shell 进程的所有环境变量
使用 export 命令还可以添加一个新的环境变量或删除一个环境变量
使用”export -n LINUX_APP”命令则可以删除 LINUX_APP 环境变量
环境变量存放在一个字符串数组中,在应用程序中,通过 environ 变量指向它,environ 是一个全局变 量,在我们的应用程序中只需申明它即可使用
如果只想要获取某个指定的环境变量,可以使用库函数 getenv()
#include <stdlib.h>
char *getenv(const char *name);
|
#include <stdlib.h>
int putenv(char *string);
|
string:参数 string 是一个字符串指针,指向 name=value 形式的字符串。
返回值:成功返回 0;失败将返回非 0 值,并设置 errno。
#include <stdlib.h>
int setenv(const char *name, const char *value, int overwrite);
|
name:需要添加或修改的环境变量名称。
value:环境变量的值。
overwrite:若参数 name 标识的环境变量已经存在,在参数 overwrite 为 0 的情况下,setenv()函数将不 改变现有环境变量的值,也就是说本次调用没有产生任何影响;如果参数 overwrite 的值为非 0,若参数 name 标识的环境变量已经存在,则覆盖,不存在则表示添加新的环境变量。
返回值:成功返回 0;失败将返回-1,并设置 errno。
setenv()函数为形如 name=value 的字符串分配一块内存缓冲区,并将参数 name 和参数 value 所指向的 字符串复制到此缓冲区中,以此来创建一个新的环境变量
- 除了上面给大家介绍的函数之外,我们还可以通过一种更简单地方式向进程环境变量表中添加环境变量
环境变量的作用
- 环境变量常见的用途之一是在 shell 中,每一个环境变量都有它所表示的含义,譬如 HOME 环境变量表 示用户的家目录,USER 环境变量表示当前用户名,SHELL 环境变量表示 shell 解析器名称,PWD 环境变 量表示当前所在目录等,在我们自己的应用程序当中,也可以使用进程的环境变量。
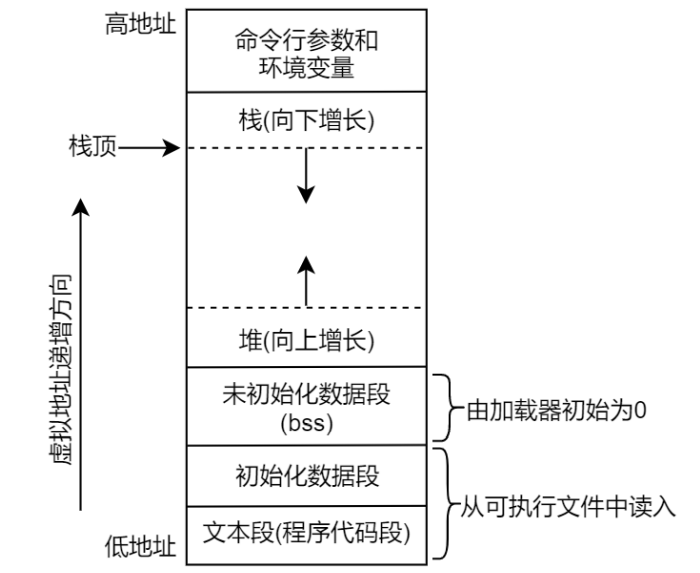
进程的内存布置
正文段。也可称为代码段,这是 CPU 执行的机器语言指令部分,文本段具有只读属性,以防止程 序由于意外而修改其指令;正文段是可以共享的,即使在多个进程间也可同时运行同一段程序。
初始化数据段。通常将此段称为数据段,包含了显式初始化的全局变量和静态变量,当程序加载到 内存中时,从可执行文件中读取这些变量的值。
未初始化数据段。包含了未进行显式初始化的全局变量和静态变量,通常将此段称为 bss 段,这一 名词来源于早期汇编程序中的一个操作符,意思是“由符号开始的块”(block started by symbol), 在程序开始执行之前,系统会将本段内所有内存初始化为 0,可执行文件并没有为 bss 段变量分配 存储空间,在可执行文件中只需记录 bss 段的位置及其所需大小,直到程序运行时,由加载器来分 配这一段内存空间。
栈。函数内的局部变量以及每次函数调用时所需保存的信息都放在此段中,每次调用函数时,函数 传递的实参以及函数返回值等也都存放在栈中。栈是一个动态增长和收缩的段,由栈帧组成,系统 会为每个当前调用的函数分配一个栈帧,栈帧中存储了函数的局部变量(所谓自动变量)、实参和 返回值。
堆。可在运行时动态进行内存分配的一块区域,譬如使用 **malloc()**分配的内存空间,就是从系统堆 内存中申请分配的。
虚拟地址
在 32 位系统中,每个进程的逻辑地址空间均为 4GB,这 4GB 的内存空间按照 3:1 的比例 进行分配,其中用户进程享有 3G 的空间,而内核独自享有剩下的 1G 空间,如下所示:
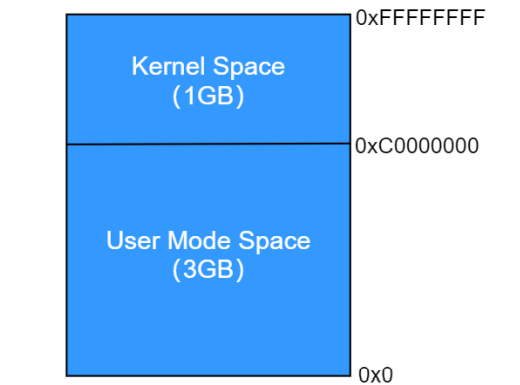
学习过驱动开发的读者对“虚拟地址”这个概念应该并不陌生,虚拟地址会通过硬件 MMU(内存管理 单元)映射到实际的物理地址空间中,建立虚拟地址到物理地址的映射关系后,对虚拟地址的读写操作实际 上就是对物理地址的读写操作,MMU 会将物理地址“翻译”为对应的物理地址
- 虚拟地址解决的问题
- 内存使用效率低。内存空间不足时,就需要将其它程序暂时拷贝到硬盘中,然后将新的程序装入内 存。然而由于大量的数据装入装出,内存的使用效率就会非常低。(实际上不会真正给程序分配所有的空间,程序用到的时候才会分配空间)
- 进程地址空间不隔离。由于程序是直接访问物理内存的,所以每一个进程都可以修改其它进程的 内存数据,甚至修改内核地址空间中的数据,所以有些恶意程序可以随意修改别的进程,就会造成 一些破坏,系统不安全、不稳定。
- 无法确定程序的链接地址。程序运行时,链接地址和运行地址必须一致,否则程序无法运行!因为 程序代码加载到内存的地址是由系统随机分配的,是无法预知的,所以程序的运行地址在编译程序 时是无法确认的。
- 在某些应用场合下,两个或者更多进程能够共享内存。因为每个进程都有自己的映射表,可以让不 同进程的虚拟地址空间映射到相同的物理地址空间中。通常,共享内存可用于实现进程间通信。
- 便于实现内存保护机制。譬如在多个进程共享内存时,允许每个进程对内存采取不同的保护措施, 例如,一个进程可能以只读方式访问内存,而另一进程则能够以可读可写的方式访问。
创建子线程
#include <unistd.h>
pid_t fork(void);
|
- fork()调用成功后,将会在父进程中返回子进程的 PID,而在子进程中返回值是 0;如果调用失败,父进 程返回值-1,不创建子进程,并设置 errno。
- fork()系统调用的关键在于,完成对其调用后将存在两个进程,一个是原进程(父进程)、另一个 则是创建出来的子进程,并且每个进程都会从 fork()函数的返回处继续执行,会导致调用 fork()返回两次值, 子进程返回一个值、父进程返回一个值。在程序代码中,可通过返回值来区分是子进程还是父进程。
- fork()调用成功后,子进程和父进程会继续执行 fork()调用之后的指令,子进程、父进程各自在自己的进 程空间中运行。事实上,子进程是父进程的一个副本,譬如子进程拷贝了父进程的数据段、堆、栈以及继承 了父进程打开的文件描述符,父进程与子进程并不共享这些存储空间,这是子进程对父进程相应部分存储 空间的完全复制,执行 fork()之后,每个进程均可修改各自的栈数据以及堆段中的变量,而并不影响另一个 进程。
- 虽然子进程是父进程的一个副本,但是对于程序代码段(文本段)来说,两个进程执行相同的代码段, 因为代码段是只读的,也就是说父子进程共享代码段,在内存中只存在一份代码段数据。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
pid = fork();
switch (pid)
{
case -1:
perror("fork error");
exit(-1);
case 0:
printf("这是子进程打印信息<pid: %d, 父进程 pid: %d>\n",
getpid(), getppid());
_exit(0);
default:
printf("这是父进程打印信息<pid: %d, 子进程 pid: %d>\n",
getpid(), pid);
exit(0);
}
}
|
进程和子进程之间的文件共享
调用 fork()函数之后,子进程会获得父进程所有文件描述符的副本,这些副本的创建方式类似于 dup(), 这也意味着父、子进程对应的文件描述符均指向相同的文件表
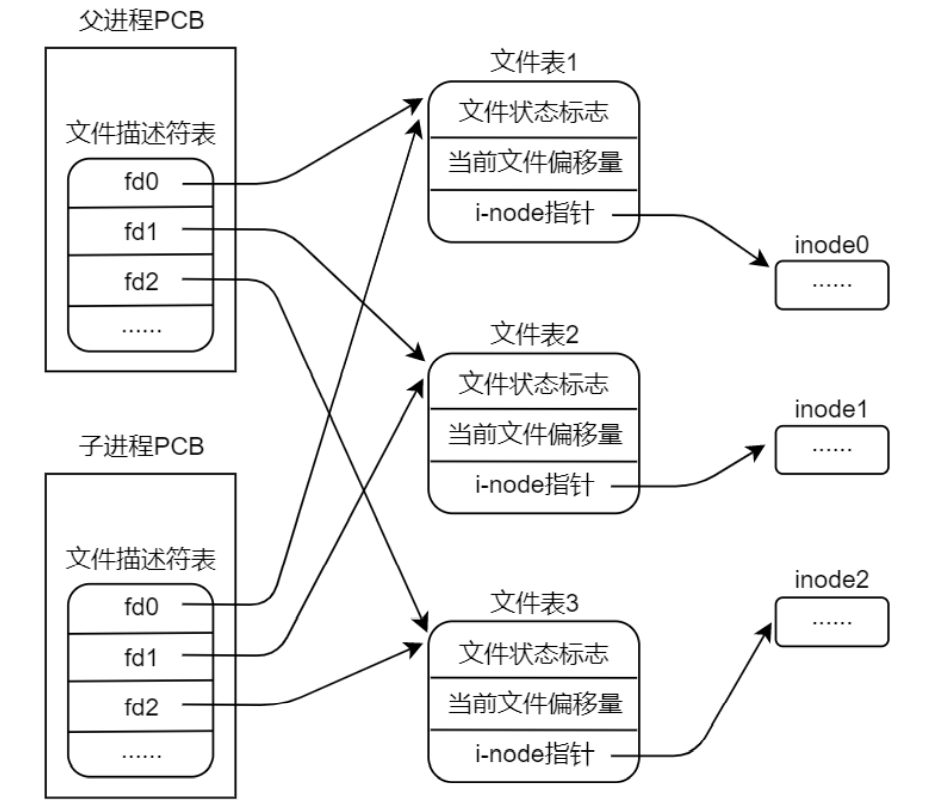
由此可知,子进程拷贝了父进程的文件描述符表,使得父、子进程中对应的文件描述符指向了相同的文 件表,也意味着父、子进程中对应的文件描述符指向了磁盘中相同的文件,因而这些文件在父、子进程间实 现了共享,譬如,如果子进程更新了文件偏移量,那么这个改变也会影响到父进程中相应文件描述符的位置 偏移量。
假如是父子进程分别打开同一个文件的话(在fork()之后),则读写文件会互相覆盖,因为偏移量没有互相影响
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
pid_t pid;
int fd;
int i;
pid = fork();
switch (pid)
{
case -1:
perror("fork error");
exit(-1);
case 0:
fd = open("./Text.txt", O_WRONLY);
if (0 > fd)
{
perror("open error");
_exit(-1);
}
for (i = 0; i < 4; i++)
write(fd, "1122", 4);
close(fd);
_exit(0);
default:
fd = open("./Text.txt", O_WRONLY);
if (0 > fd)
{
perror("open error");
exit(-1);
}
for (i = 0; i < 5; i++)
write(fd, "AABB", 4);
close(fd);
exit(0);
}
}
|
#include <sys/types.h>
#include <unistd.h>
pid_t vfork(void);
|
从前面的介绍可知,可以将 fork()认作对父进程的数据段、堆段、栈段以及其它一些数据结构创建拷贝, 由此可以看出,使用 fork()系统调用的代价是很大的,它复制了父进程中的数据段和堆栈段中的绝大部分内 容,这将会消耗比较多的时间,效率会有所降低,而且太浪费,原因有很多,其中之一在于,fork()函数之 后子进程通常会调用 exec 函数.子进程不再执行父程序中的代码 段,而是执行新程序的代码段,从新程序的 main 函数开始执行、并为新程序重新初始化其数据段、堆段、 栈段等.
出于这一原因,引入了 vfork()系统调用,虽然在一些细节上有所不同,但其效率要高于 fork()函数。类 似于 fork(),vfork()可以为调用该函数的进程创建一个新的子进程,然而,vfork()是为子进程立即执行 exec() 新的程序而专门设计的
- vfork的区别:
- vfork()与 fork()一样都创建了子进程,但 vfork()函数并不会将父进程的地址空间完全复制到子进程 中,因为子进程会立即调用 exec(或_exit),于是也就不会引用该地址空间的数据。不过在子进程 调用 exec 或_exit 之前,它在父进程的空间中运行、子进程共享父进程的内存。这种优化工作方式 的实现提高的效率;但如果子进程修改了父进程的数据(除了 vfork 返回值的变量)、进行了函数 调用、或者没有调用 exec 或_exit 就返回将可能带来未知的结果。
- 另一个区别在于,vfork()保证子进程先运行,子进程调用 exec 之后父进程才可能被调度运行。
现代的 Linux 系统内核已经采 用了写时复制技术来实现 fork(),其效率较之于早期的 fork()实现要高出许多,除非速度绝对重要的场合, 我们的程序当中应舍弃 vfork()而使用 fork()。
调用 fork()之后,子进程成为了一个独立的进程,可被系统调度运行,而父进程也继续被系统调度运行, 这里出现了一个问题,调用 fork 之后,无法确定父、子两个进程谁将率先访问 CPU
此时可以采用先让某个进程堵塞,然后另一个进程向其发送信号将其唤醒
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
static void sig_handler(int sig)
{
printf("接收到信号\n");
}
int main(void)
{
struct sigaction sig = {0};
sigset_t wait_mask;
sigemptyset(&wait_mask);
sig.sa_handler = sig_handler;
sig.sa_flags = 0;
if (-1 == sigaction(SIGUSR1, &sig, NULL))
{
perror("sigaction error");
exit(-1);
}
switch (fork())
{
case -1:
perror("fork error");
exit(-1);
case 0:
printf("子进程开始执行\n");
printf("子进程打印信息\n");
printf("~~~~~~~~~~~~~~~\n");
sleep(2);
kill(getppid(), SIGUSR1);
_exit(0);
default:
if (-1 != sigsuspend(&wait_mask))
exit(-1);
printf("父进程开始执行\n");
printf("父进程打印信息\n");
exit(0);
}
}
|
- 上面代码中的父进程先通过调用
sigsuspend(&wait_mask)堵塞,然后等待子线程发送kill(getppid(), SIGUSR1)发送信号将其唤醒
init 进程的 PID 总是为 1,它是所有子进程的父进程,一切从 1 开始、一切从 init 进程开始
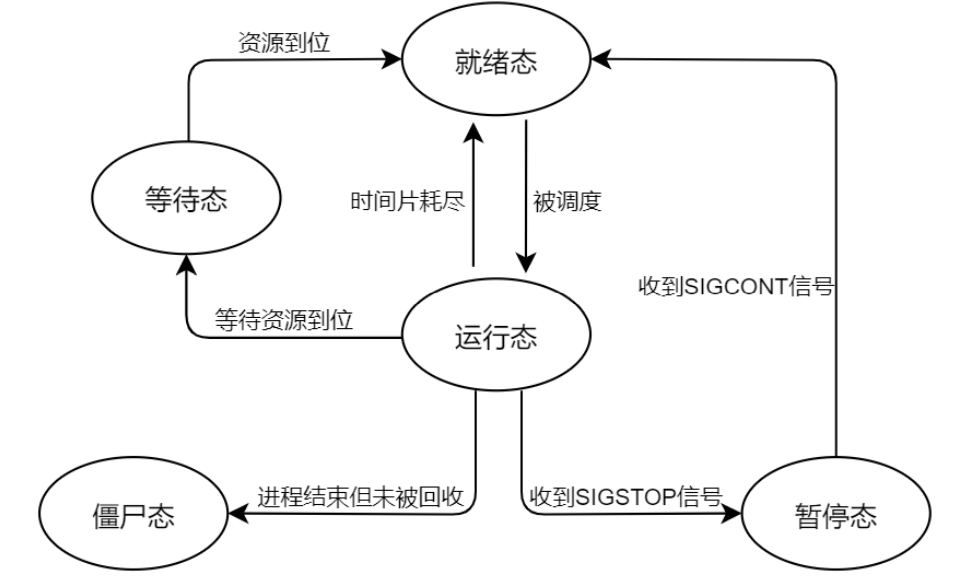
进程的退出
- 如果程序中注册了进程终止处理函数,那么会调用终止处理函数。在 9.1.2 小节给大家介绍如何注 册进程的终止处理函数;
- 刷新 stdio 流缓冲区。
- 执行_exit()系统调用
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
printf("Hello World!");
switch (fork())
{
case -1:
perror("fork error");
exit(-1);
case 0:
exit(0);
default:
exit(0);
}
}
|
这个程序会将其中的”Hello World”打印两次,但是假如上述字符串包含换行符的话就不会打印显示,原因如下
- 进程的用户空间内存中维护了 stdio 缓冲区,0 小节给大家 介绍过,因此通过 fork()创建子进程时会复制这些缓冲区。标准输出设备默认使用的是行缓冲,当检测到换 行符\n 时会立即显示函数 printf()输出的字符串,此时输出之后的缓冲区的空的
- 假如没有换行符的话,系统并不会立即输出内容,这就导致在创建子线程的时候会将缓冲去等待显示的字符串也拷贝一次。当它们调用 exit()函数时,都会刷 新各自的缓冲区、显示字符串,所以就会看到打印出了两次相同的字符串
- 防止上述问题的办法
- 在调用 fork()之前,使用函数
fflush()来刷新 stdio 缓冲区,当然,作为另一种选择,也可以使用 setvbuf()和 setbuf()来关闭 stdio 流的缓冲功能
监视子进程
- 系统调用 wait()可以等待进程的任一子进程终止,同时获取子进程 的终止状态信息
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
|
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
|
pid:参数 pid 用于表示需要等待的某个具体子进程,关于参数 pid 的取值范围如下:
- 如果 pid 大于 0,表示等待进程号为 pid 的子进程;
- 如果 pid 等于 0,则等待与调用进程(父进程)同一个进程组的所有子进程;
- 如果 pid 小于-1,则会等待进程组标识符与 pid 绝对值相等的所有子进程;
- 如果 pid 等于-1,则等待任意子进程。wait(&status)与 waitpid(-1, &status, 0)等价。
status:与 wait()函数的 status 参数意义相同。
参数 options 是一个位掩码,可以包括 0 个或多个标志(略)
僵尸进程和孤儿进程
孤儿进程
- 父进程先于子进程结束,也就是意味着,此时子进程变成了一个“孤儿”,我们把这种进程就称为孤儿 进程。
- 在 Linux 系统当中,所有的孤儿进程都自动成为 init 进程(进程号为 1)的子进程,换言之,某一子 进程的父进程结束后,该子进程调用 getppid()将返回 1
僵尸进程
- 进程结束之后,通常需要其父进程为其“收尸”,回收子进程占用的一些内存资源,父进程通过调用 wait()(或其变体 waitpid()、waitid()等)函数回收子进程资源,归还给系统。
- 如果子进程先于父进程结束,此时父进程还未来得及给子进程“收尸”,那么此时子进程就变成了一个 僵尸进程。
- 当父进程调用 wait()(或其变体,下文不再强调)为子进程“收尸”后,僵尸进程就会被内核彻底删除。 另外一种情况,如果父进程并没有调用 wait()函数然后就退出了,那么此时 **init 进程将会接管它的子进程并 自动调用 wait()**,故而从系统中移除僵尸进程。
- 如果系统中存在大量的 僵尸进程,它们势必会填满内核进程表,从而阻碍新进程的创建。需要注意的是,僵尸进程是无法通过信号 将其杀死的,即使是“一击必杀”信号 SIGKILL 也无法将其杀死,那么这种情况下,只能杀死僵尸进程的 父进程(或等待其父进程终止),这样 init 进程将会接管这些僵尸进程,从而将它们从系统中清理掉
执行新程序
execve()
#include <unistd.h>
int execve(const char *filename, char *const argv[], char *const envp[]);
|
filename:参数 filename 指向需要载入当前进程空间的新程序的路径名,既可以是绝对路径、也可以是 相对路径。
argv:参数 argv 则指定了传递给新程序的命令行参数。是一个字符串数组,**该数组对应于 main(int argc, char *argv[])函数的第二个参数 argv,且格式也与之相同,是由字符串指针所组成的数组**,以 NULL 结束。 argv[0]对应的便是新程序自身路径名。
envp:参数 envp 也是一个字符串指针数组,指定了新程序的环境变量列表,参数 envp 其实对应于新程 序的 environ 数组,同样也是以 NULL 结束,所指向的字符串格式为 name=value。
execve 调用成功将不会返回;失败将返回-1,并设置 errno。对 execve()的成功调用将永不返回,而且也无需检查它的返回值,实际上,一旦该函数返回,就表明它 发生了错误。
执行shell命令
- 使用 system()函数可以很方便地在我们的程序当中执行任意 shell 命令,本小节来学习下 system()函数的 用法,以及介绍 system()函数的实现方法。 首先来看看 system()函数原型,如下所示
#include <stdlib.h>
int system(const char *command);
|
- system()函数其内部的是通过调用 fork()、execl()以及 waitpid()这三个函数来实现它的功能,首先 system() 会调用 fork()创建一个子进程来运行 shell(可以把这个子进程成为 shell 进程),并通过 shell 执行参数 command 所指定的命令。
- 当参数 command 为 NULL,如果 shell 可用则返回一个非 0 值,若不可用则返回 0;针对一些非 UNIX 系统,该系统上可能是没有 shell 的,这样就会导致 shell 不可能;如果 command 参数不为 NULL,则返回值从以下的各种情况所决定。
- 如果无法创建子进程或无法获取子进程的终止状态,那么 system()返回-1;
- 如果子进程不能执行 shell,则 system()的返回值就好像是子进程通过调用_exit(127)终止了;
- 如果所有的系统调用都成功,system()函数会返回执行 command 的 shell 进程的终止状态。