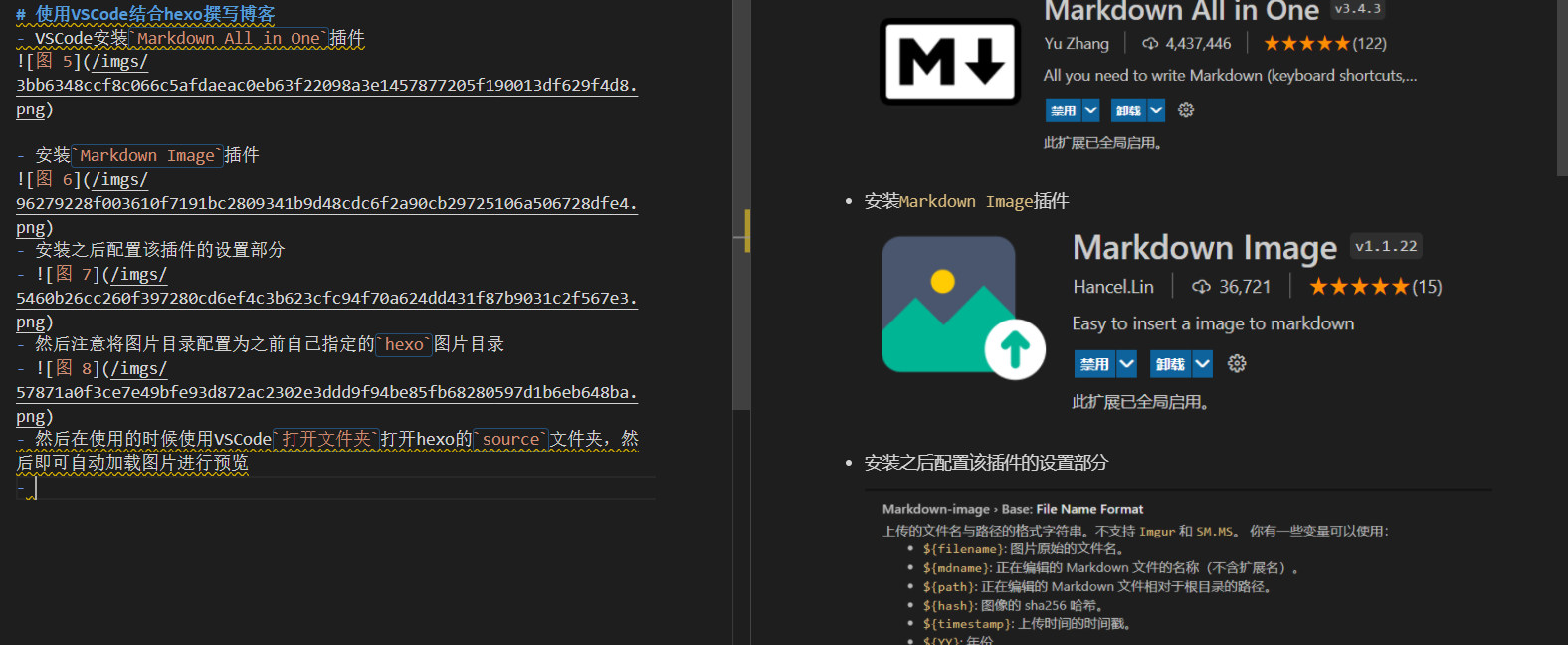
时间复杂度的计算

稳定性
- 数组中相同的元素在排序前后的相对次序有没有变化?没有就是稳定的。
- 语言为java,但是因为与C++类似,所以没有专门更改
- 交换函数
- 位运算的交换函数
a = a^b;
b = a^b;
c = a^b;
- 位运算的交换函数
- 普通交换函数
public static void swap(int[] arr, int i, int j) {
int tmp = arr[j];
arr[j] = arr[i];
arr[i] = tmp;
}选择排序
public static void selectSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int N = arr.length;
for (int i = 0; i < N; i++) {
int minValueIndex = i;
for (int j = i + 1; j < N; j++) {
minValueIndex = arr[j] < arr[minValueIndex] ? j : minValueIndex;
}
swap(arr, i, minValueIndex);
}
} - 时间复杂度O(N^2), 空间复杂度O(1),不稳定
- 思路:大循环确定每次排序的第一个位置,每次确定一个数字,确定的方法是从还未确定的范围里选出一个最小的数字,将这个数字与排序的第一个位置原来的数字交换位置,然后确定该位置的数字,将排序的起始位置前移一个
冒泡排序
public static void bubbleSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int N = arr.length;
for (int end = N - 1; end >= 0; end--) {
for (int second = 1; second <= end; second++) {
if (arr[second - 1] > arr[second]) {
swap(arr, second - 1, second);
}
}
}
} - 时间复杂度O(N^2),空间复杂度O(1),稳定
- 首先从数组的第一个到最后一个元素执行一次冒泡,冒泡的具体行为是假如数组下表前一个位置的数字比下表位置的数字大的话,交换这两个数字,然后一次冒泡结束之后将冒泡行为的后边界前移一。
希尔排序
- 希尔排序(Shell Sort)是一种基于插入排序的高效排序算法。它通过比较和交换非相邻的元素来实现部分排序,从而逐步减少间距,最终达到全局排序的目的。时间复杂度在
O(nlogn)和O(n^3/2) - 选择增量序列:选择一系列递减的增量(如 n/2, n/4, …, 1),其中 n 是数组的长度。
- 分组并排序:对于每个元素,这个元素一次往前回退增量个步长,按这个步长执行插入排序(如果当前位置-步长位置的元素大于当前元素,就交换这两个元素)
- 缩小增量:依次缩小增量,重复分组和排序的过程。
- 完成排序:当增量缩小到1时,进行最后一次插入排序,最终完成排序。
// 希尔排序函数
void shellSort(std::vector<int>& arr) {
int n = arr.size();
// 初始增量gap,通常选择n的一半
for (int gap = n / 2; gap > 0; gap /= 2) {
// 从gap开始,对每个元素进行插入排序
for (int i = gap; i < n; i++) {
int temp = arr[i];
int j;
// 对当前gap分组进行插入排序
// 以gap为间隔,向前移动元素直到前面元素不比他小
for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {
arr[j] = arr[j - gap];
}
arr[j] = temp;
}
}
}插入排序
void insertionSort(std::vector<int>& arr) {
int n = arr.size();
for (int i = 1; i < n; ++i) {
int key = arr[i];
int j = i - 1;
// 将 arr[i] 插入到已经排序的序列 arr[0..i-1] 中
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
--j;
}
arr[j + 1] = key;
}
} - 思路是从第二个元素开始,假如该元素比前一个元素小的话,就将这个元素向前移动,直到前一个元素不比这个元素小为止(类似于打扑克起牌的时候将大牌插入到前面,只不过是一次移动一个,而不是一次到位)。然后将插入元素的起始位置向后移动一个。
- 时间复杂度O(N^2),空间复杂度O(1),稳定
归并排序 2024-6-19更新
- leetcode
using namespace std;
class Solution {
public:
vector<int> sortArray(vector<int>& nums) {
return merge(nums, 0, nums.size()-1);
}
vector<int> merge(vector<int>& vec, int beg, int end)
{
if(beg == end)return {vec[beg]};
vector<int> v1 = merge(vec, beg, (beg+end)/2);
vector<int> v2 = merge(vec, (beg+end)/2+1, end);
int i1 = 0, i2 = 0;
vector<int> ret;
ret.reserve(v1.size()+v2.size());
while(i1<v1.size() && i2<v2.size())
{
if(v1[i1]<=v2[i2])
{
ret.push_back(v1[i1]);
++i1;
}
else
{
ret.push_back(v2[i2]);
++i2;
}
}
if(i1<v1.size())
{
ret.insert(ret.end(), v1.begin()+i1, v1.end());
}
else if(i2<v2.size())
{
ret.insert(ret.end(), v2.begin()+i2, v2.end());
}
return ret;
}
}; - 时间复杂度O(N*log(N))空间复杂度O(N),稳定
- 思路就是将数组分为左右两部分,然后对左边和右边分别递归执行,执行之后回溯到这一层的时候,左右两个数组已经是各自有序的了,然后将两个数组进行合并(merge),合并操作就是将两个数组的下表设置为各自最前,然后将两个下标位置对应的数字中较小的一个放入总的数组中,该数组的下标前进一位。假如执行到最后有一个数组的下标到达了最后,就将这个数组整个衔接在总的数组末尾(需要用到额外空间)。
链表归并排序 2023-10-30
- leetcode
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
map<int, ListNode*> m;
class Solution {
public:
ListNode* sortList(ListNode* head) {
if (head == NULL)
{
return head;
}
ListNode* tail = head;
while(tail->next!=NULL)
{
tail = tail->next;
}
return split(head, tail);
}
ListNode* split(ListNode* h, ListNode* tail)
{
if(h == NULL)
{
return NULL;
}
else if(h->next == NULL)
{
return h;
}
else if(h->next == tail)
{
h->next = NULL;
return merge(h, tail);
}
ListNode* slow = h, *fast = h;
while(fast!=tail)
{
slow = slow->next;
fast = fast->next;
if(fast!=tail)
{
fast = fast->next;
}
}
ListNode* h2 = slow->next;
slow->next = NULL;
return merge(split(h, slow), split(h2, tail));
}
ListNode* merge(ListNode* h1, ListNode* h2)
{
if(h1 == NULL || h2 == NULL)
{
return h1?h1:h2;
}
ListNode* vHead = new ListNode();
ListNode* ret = vHead;
while(h1!=NULL&&h2!=NULL)
{
if(h1->val<h2->val)
{
vHead -> next = h1;
h1 = h1->next;
}
else
{
vHead -> next = h2;
h2 = h2->next;
}
vHead = vHead->next;
}
if(h1!=NULL)
{
vHead->next = h1;
}
else if(h2!=NULL)
{
vHead->next = h2;
}
return ret->next;
}
};链表归并排序的内存生命周期问题
- 链表排序的时候假如不食用一个外部的头节点的话,会可能遇到报错

- 提示一个指针指向NULL,不可被操作了
- 在整个过程中最好手动创建一个节点的next指向头节点,使得系统指向链表的指针不丢失,防止空间被回收
- 比如如下多个链表合并的问题
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
auto cmp = [](ListNode*& a, ListNode*& b){return a->val>b->val;};
priority_queue<ListNode*, vector<ListNode*>, decltype(cmp)> pq(cmp);
for(auto it = lists.begin(); it!=lists.end(); it++)
{
ListNode* cur = *it;
while(cur!=NULL)
{
pq.push(cur);
// cout<<cur->val<<' ';
cur = cur->next;
}
}
ListNode* head = pq.top();
// cout<<head->val;
ListNode* ret = head;
pq.pop();
while(pq.size()>0)
{
head->next = pq.top();
// cout<<head->next->val;
pq.pop();
head = head->next;
}
head->next = NULL;
// cout<<'!'<<endl;
ListNode* tmp = ret;
while(tmp!=NULL)
{
cout<<tmp->val<<endl;
tmp = tmp->next;
}
return ret;
}
};
- 但是实际上归并多个有序数组的时候只需要在一开始遍历每个数组的第一个元素,将其添加到优先级队列中,等到合并的时候从优先级队列中弹出某个元素的时候,再将其后继的数字添加到队列中即可,不需要在一开始就把所有的节点都加入优先级队列
快速排序 2023-10-30更新
- 递归版本(leetcode)
class Solution {
public:
vector<int> sortArray(vector<int>& nums) {
fastSort(nums, 0, nums.size()-1);
return nums;
}
void fastSort(vector<int>& arr, int beg ,int end)
{
if(end<=beg)return;
int randPos = rand()%(end-beg)+beg;
swap(arr[end], arr[randPos]);
int less = beg-1; // 小于区的右边界,包括自己
int more = end; //大于区的左边界,包括自己
int index = beg; // 当前位置,左边一个是等于区
while(index<more)
{
if(arr[index]<arr[end])
{
swap(arr[index++], arr[++less]); // 小于区加一
}
else if(arr[index] == arr[end])
{
index++; // 等于区加一
}
else
{
swap(arr[index], arr[--more]); // 大于区减一
}
}
swap(arr[end], arr[more]);
fastSort(arr, beg, less);
fastSort(arr, more+1, end);
}
void swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
}; - 时间复杂度O(Nlog(N)),空间复杂度O(log(N)),
- 荷兰国旗问题:将整个数组分为三个部分,左边的部分比给定的flag小,中间的部分等于flag,右边的部分大于flag。(选择最右为分割标志)
- 其中的less是小于区的右边界(包括自己),more是大于区的左边界(包括自己)
- index位置是等于区的右边一个位置(不包括自己),less右边一个到index-1的值(包括边界)与分割值相等
- 假如index位置的数字和分割标志相等,直接index++
- 假如index位置的数字比标志小,那么index位置的数字与小于区的左边界右边第一个数字交换,index和小于区的右边界各自++,相当于小于区推动等于区右移
- 假如index位置的数字比标志大,那么将index位置的数字与大于区左边界的第一个数字交换,index不动,大于区的左边界左移一个位置。
- 遍历结束之后,将数组最右边位置的数字与大于区左边界位置的数字进行交换(因为开始时候取的标志是最右的数字)
- 下一层调用的时候,对小于区(开始位置到less)和大于区(more+1到结束位置)分别调用快排即可,因为前面已经将end位置和more位置交换过了,因此不需要从more位置开始,从more的下一个位置开始即可
堆排序 2023-10-30更新
- leetcode
using namespace std;
class Solution {
public:
vector<int> sortArray(vector<int>& nums) {
// 从后向前逐个元素向下运动,建造大根堆
for(int i = nums.size()-1; i>=0; i--)
{
heapDown(nums, i, nums.size());
}
for(int i = nums.size()-1; i>0; i--)
{
swap(nums, 0, i);
heapDown(nums, 0, i);
}
return nums;
}
// 向下
void heapDown(vector<int>& arr, int index, int size)
{
int big;
while(index*2+1<size)
{
if(index*2+2>=size)
{
big = index*2+1;
}
else
{
big = arr[index*2+1] > arr[index*2+2]?index*2+1:index*2+2;
}
if(arr[index]<arr[big])
{
swap(arr, index, big);
index = big;
}
else
{
break;
}
}
}
// 向上
void heapUp(vector<int>& arr, int index)
{
while(index>=0)
{
if(((index-1)/2)>0)
{
if(arr[(index-1)/2]>arr[index])
{
swap(arr, (index-1)/2, index);
}
else
{
break;
}
}
index = (index-1)/2;
}
}
void swap(vector<int>& arr, int a, int b)
{
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
}; - 时间复杂度O(Nlog(N)),空间复杂度O(1),不稳定
heapInsert是堆插入函数,将插入的数字向上看是否在需要的位置上heapify是将数组中某个位置的数字向下移动,直到需要的位置(向下交换的时候与两个孩子中较大的那个交换)- 建堆的操作是从倒数第二个元素开始直到数组的第一个元素,执行向下调整函数
- 建立堆之后实际上是将堆中的元素挨个取出的过程,就是每次从堆头取出一个元素,然后将堆尾部的元素与这个元素位置交换,将堆尾部的元素向下插入堆
- 因为取出的元素是从后往前排列的,因此最终的结果是递增的,虽然前面元素向下的操作是大根堆
建立堆
public static class MyMaxHeap { |
- 向堆插入数字的方法就是将堆的尺寸+1,然后从被插入数字开始上溯直到不比父亲大
- 用户从堆顶弹出的方法是弹出之后将堆尺寸-1,然后将堆最后一个元素复制到以前堆顶的位置,然后执行heapify,也就是将该元素下沉直到不比儿子小为止