fork和vfork
fork创建进程的时候,将父进程的所有资源拷贝给子进程- 写时复制的
- 实际上是将内存地址设置为只读的
- 假如任何一个进程试图写入的话,会触发
page fault导致系统给他分配新的内存,也就是复制
vfork的时候是直接将子进程的资源指向父进程的,二者是同时共有资源的,一个修改会影响另一个线程与进程的关系
- 通过
pthread_create创建线程的时候,实际上是调用系统的clone(类似于vfork)方式创建了一个与父进程共享一切资源的子进程 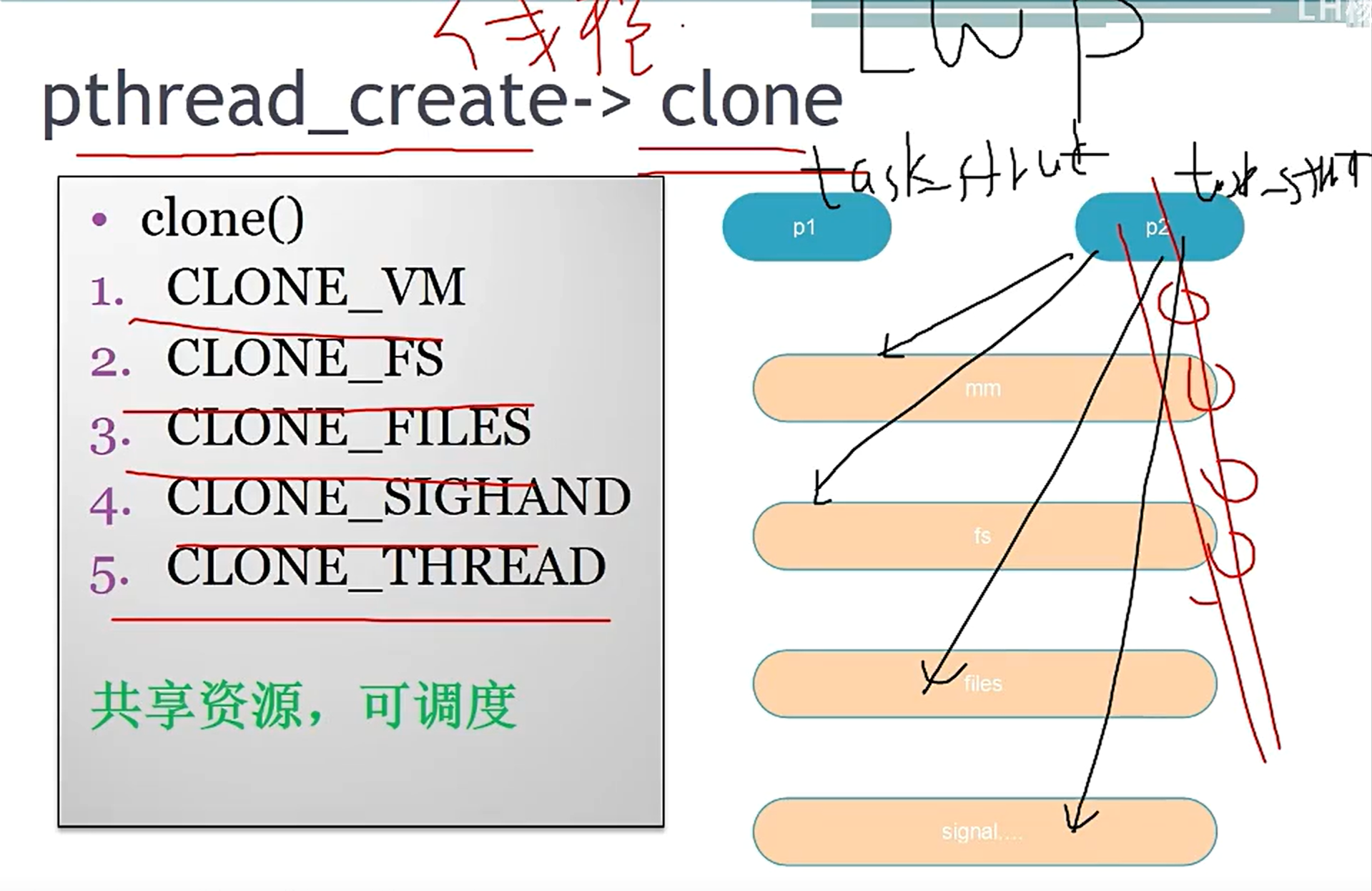
- 本来理论上父子进程之间的资源是写时复制的,但是这里直接共享了
- 每个线程都有一个独立的PID
线程的真假ID
- 用户空间
getpid()获得的PID是进程ID,并不是线程独立的PIDgettid()获得的才是真正线程PID,也就是内核的真正PID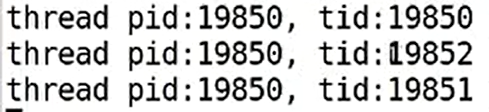
进程的托孤
- 一个拥有子进程的进程终止的时候,会向init进程或者是自己最近一级的父进程中的subreaper进程托孤,将自己的子进程交给这些进程处理
- 深度睡眠只能被资源唤醒
- 甚至无法被信号杀死
- 浅度睡眠可以被资源或者是信号(signal)唤醒
- 比如程序因为内存没加载导致page fault
- 此时如果因为接收到信号开始执行内容,会导致程序继而触发更多的page fault
- 因此只有等到相关内存页面被分配了才可以
睡眠与唤醒
- 程序的睡眠是程序访问资源的时候发现需要等待,自己让出CPU使用权并且将状态设置为sleep
- 睡眠结束的时候需要判断自己是被什么唤醒的(如果是浅度睡眠的话)
- 是被信号唤醒的?是什么信号
- 是被资源唤醒的?继续执行
第一个进程是被谁创建出来的
- 1进程(也就是init)是被Linux的0进程创建出来的
- 但是Linux的0进程使用pstree看不到
- 退化为了IDLE进程
- 进程切换的开销不只是上下文切换,主要还包括进程切换引起的内存cache 的
cache miss - 因为不同进程需要的内存空间不同,导致切换会极大增加miss概率
非实时进程的时间片分配
- 使用
nice值分配 nice越大,优先级越低- 优先级高的相对于优先级低的可以在唤醒的一瞬间抢占,但是之后会一起轮转
- 优先级越高的在轮转中分配到的时间片越长
- 在整个循环过程中是所有优先级的进程一起轮转的,不会高优先级阻塞低优先级运行
- 系统会针对应用是IO类型还是CPU消耗类型来调整nice值
sched_rt_period_us和shced_rt_runtime_us- 控制FIFO和RR最多占用的时间
sudo sh -c 'echo CPU核心数*1000000 > /proc/sys/kernel/sched_rt_period_us'- 上面那个不能超过
CPU核心数*1000000
- 上面那个不能超过
sudo sh -c 'echo 某个小于period的值 > /proc/sys/kernel/sched_rt_runtime_us'- 不能超过
sched_rt_period_us- 但是可能会导致系统崩溃

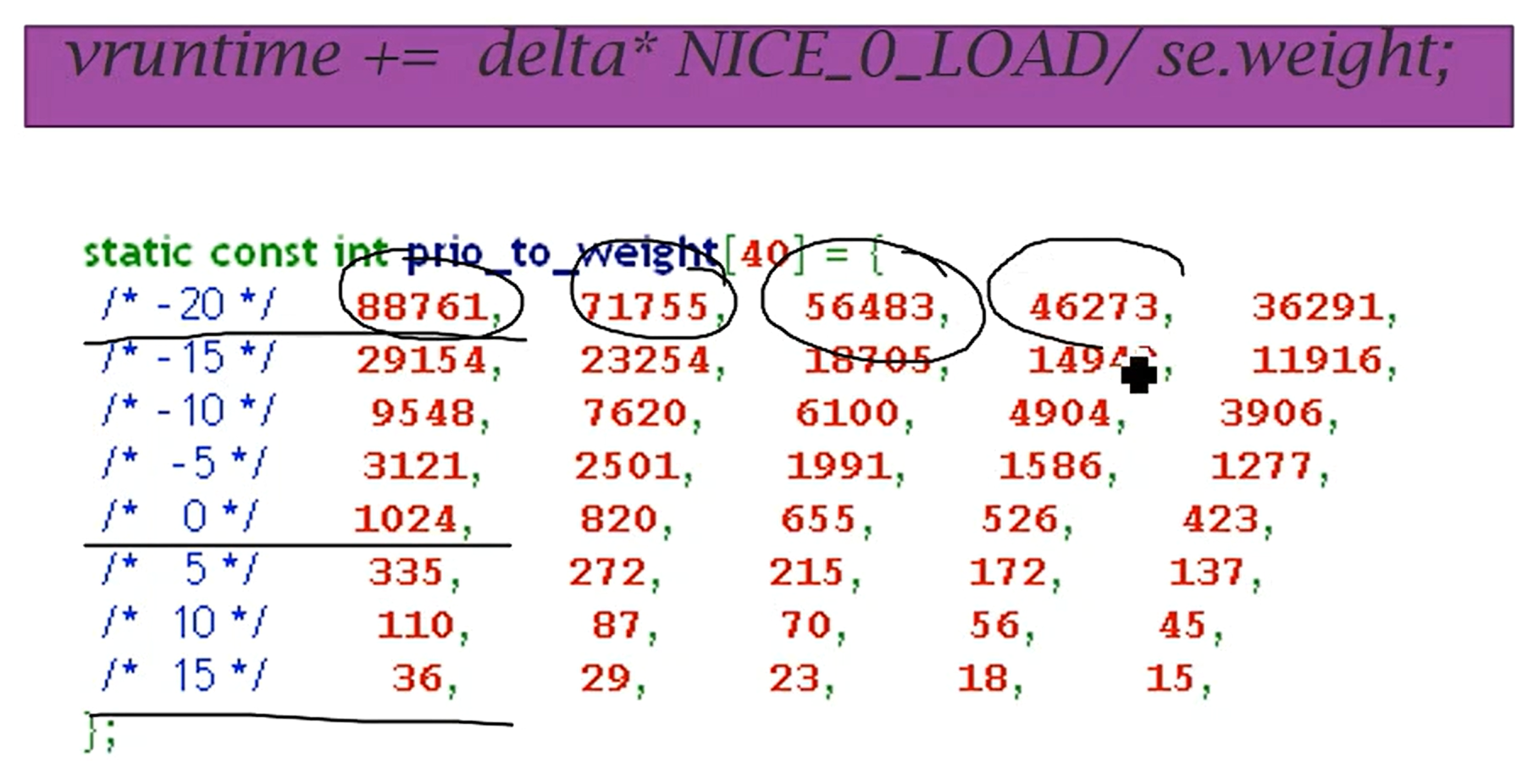
CFS-完全公平调度
- 每次都调度到当前位置vruntime最小的进程
- 也就是考虑到优先级修正之后,运行时间最小的进程
- 完全公平,使得所有进程的vruntime尽可能公平分配
- vruntime是实际运行时间进行一些权重和系数运算得出的
- 物理runtime除以权重
| System Call | Description |
|---|---|
| nice() | Sets a process’s nice value |
| sched_setscheduler() | Sets a process’s scheduling policy |
| sched_getscheduler() | Gets a process’s scheduling pol1icy |
| sched_setparam() | Sets a process’s real-time priority |
| sched_getparam() | Gets a process’s real-time priority |
| sched_get_priority_max() | Gets the maximum real-time priority |
| sched_get_priority_min() | Gets the minimum real-time priority |
| sched_rr_get_interval() | Gets a process’s timeslice value |
| sched_setaffinity() | Sets a process’s processor affinity |
| sched_getaffinity() | Gets a process’s processor affinity |
| sched_yield() | Temporarily yields the processor |
设置进程的CPU亲和
- 使用
taskset命令行工具 - 上文提到的
sched_setaffinity() - 或者单独设置线程的亲和力
pthread_setaffinity_np()
int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset); - 或者创建新线程时,通过属性结构体,控制新线程的亲和性
pthread_attr_setaffinity_np()
int pthread_attr_setaffinity_np(pthread_attr_t *attr, size_t cpusetsize, const cpu_set_t *cpuset);
进程组
- cgroup(Control Groups)是 Linux 内核提供的一个功能,用于限制、控制和监视一个或多个进程的资源使用。cgroup 允许你将进程组织在层次结构中,并为每个组分配特定的资源限制。
- 创建
sudo mkdir /sys/fs/cgroup/cpu/my_cgroup
- 添加进程
echo <PID> > /sys/fs/cgroup/cpu/my_cgroup/tasks
- 设置 cgroup 的资源限制
echo 1000000 > /sys/fs/cgroup/cpu/my_cgroup/cpu.cfs_quota_us
- 查看 cgroup 信息
cat /sys/fs/cgroup/cpu/my_cgroup/cpu.cfs_quota_us
- 删除 cgroup
sudo rmdir /sys/fs/cgroup/cpu/my_cgroup
如何使用sudo权限将echo的输出写入到文件中
sudo sh -c 'echo string > /path/to/file' |
Linux中进程可以抢占的部分
- 即使是在下面不可调度的部分唤醒了一个优先级再高的进程,也不允许抢占执行
- 一个核心上的进程拿到了spinlock,会直接关闭这个核心的调度器停止调度
- 一个程序的优先级改变(降低)的时候,别的优先级高的进程可以立即抢占
| 区间 | 可调度性 |
|---|---|
| (硬)中断(不允许中断嵌套) | 不可调度 |
| 软中断(可以中断嵌套) | 不可调度 |
进程上下文中获取到spinlock |
不可调度 |
| 其他进程上下文 | 可以调度 |
- 自旋锁的自旋一定发生在不同的核心之间
- 如果同一个核心的两个进程争夺自旋锁,一个抢到之后就直接关闭了调度器,另一个进程根本上不来,不可能自旋
- 只有可能是一个核心持有锁,另一个核心自旋
进程回收和僵尸进程
- 一个进程变成僵尸状态之后,进程的资源都消失了
- 但是进程的
task_struct还没有消失 - 等待父进程使用
waitpid回收并且查看进程的退出码,判断子进程的死因 - 只有父进程使用wait等待的时候他的task struct才会消失
- 这个进程无法使用系统的signal杀死
Linux进程状态
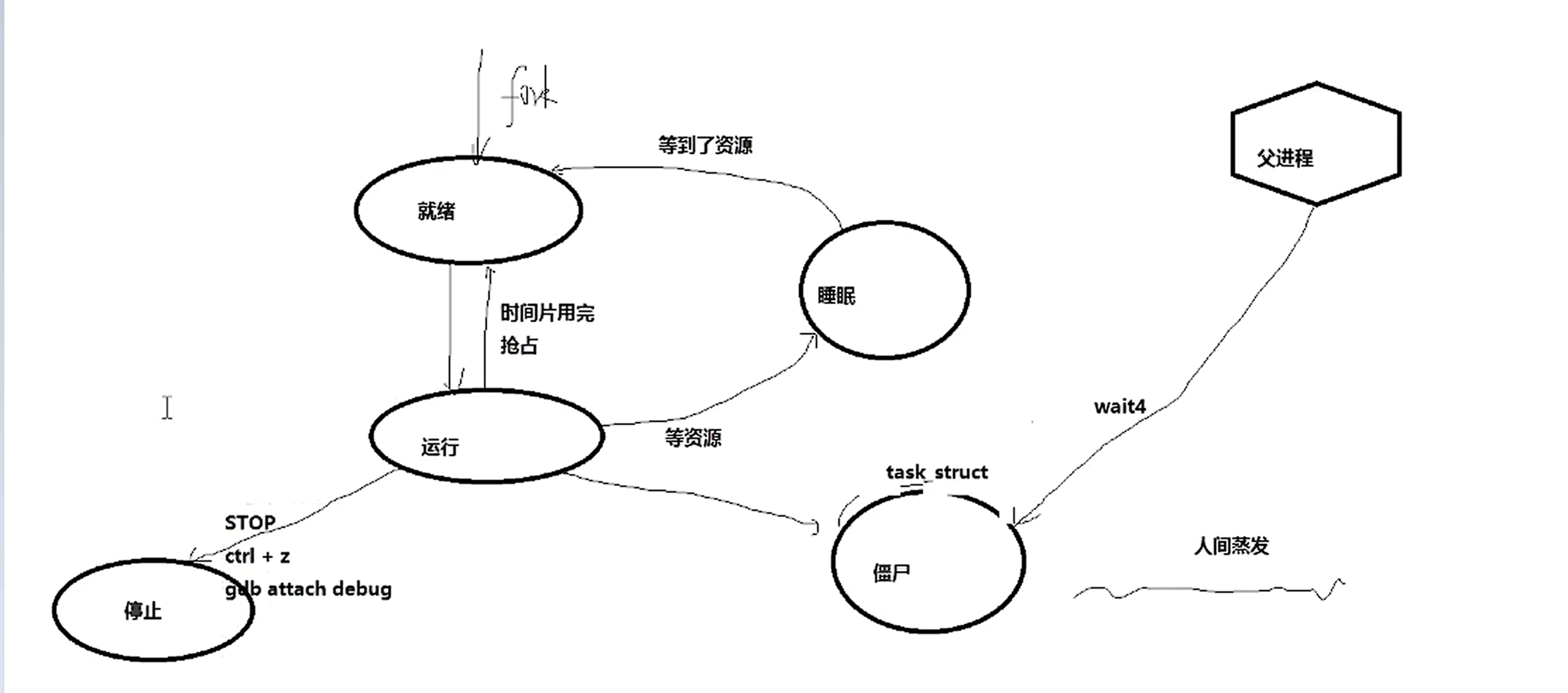
| 状态 | 行为 |
|---|---|
| 就绪 | 等待上CPU(因为时间片结束或者被抢占等) |
| 运行 | 执行 |
| 睡眠 | 等资源(等到了就绪) |
| 僵尸 | 执行完但是还没有回收 |
| 停止 | STOP或者收到了Ctrl+Z等信号,还可以继续恢复(输入fg,bg等) |