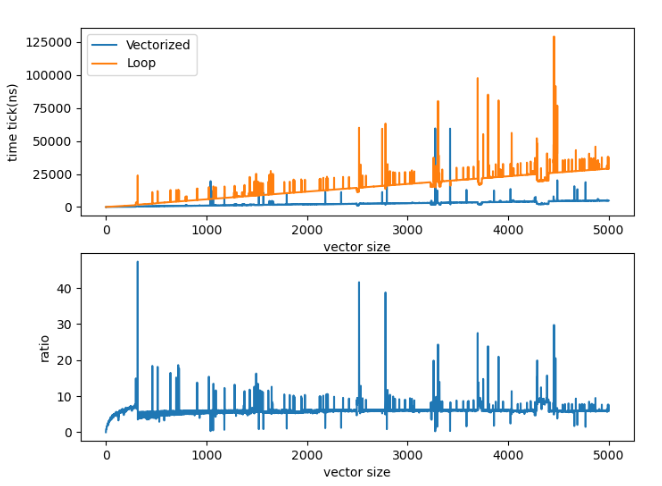
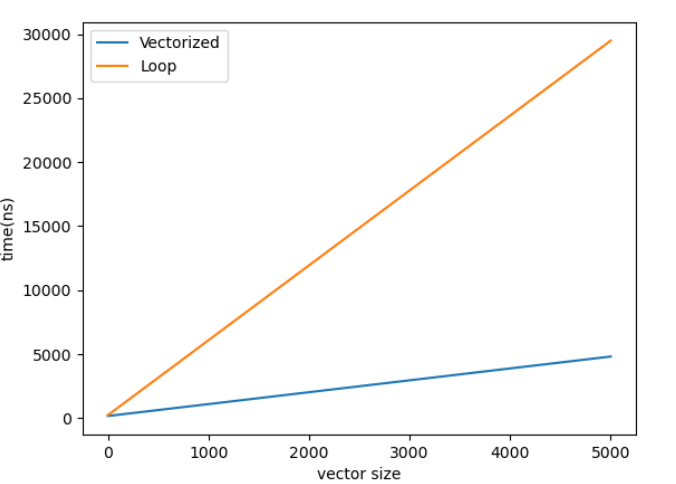
#include <stdio.h>
#include <stdint.h>
#include <time.h>
#include <immintrin.h>
float dot_productVec(float* a, float* b, int length) {
__m256 sum = _mm256_setzero_ps();
int i;
for (i = 0; i < length; i += 8) {
__m256 vecA = _mm256_loadu_ps(&a[i]);
__m256 vecB = _mm256_loadu_ps(&b[i]);
__m256 mul = _mm256_mul_ps(vecA, vecB);
sum = _mm256_add_ps(sum, mul);
}
float result[8];
_mm256_storeu_ps(result, sum);
return result[0] + result[1] + result[2] + result[3] + result[4] + result[5] + result[6] + result[7];
}
float dot_productLoop(float* a, float* b, int length)
{
int i = 0;
for(int j = 0; j<length;j++)
{
i+=a[j]*b[j];
}
return i;
}
int64_t get_time_ns() {
struct timespec ts;
clock_gettime(CLOCK_MONOTONIC, &ts);
return ts.tv_sec * 1000000000LL + ts.tv_nsec;
}
void runTrial(int length, int64_t* tVec, int64_t* tLoop)
{
if(length == 0){*tVec = 0;*tLoop = 0;return;}
float* a = malloc(sizeof(float)*length);
float* b = malloc(sizeof(float)*length);
for (int i = 0; i<length; i++)
{
a[i] = (float)i/10;
b[i] = (float)(length-i)/10;
}
int64_t tVec1, tVec2, tLoop1, tLoop2 = 0;
tVec1 = get_time_ns();
float result = dot_productVec(a, b, length);
tVec2 = get_time_ns();
tLoop1 = get_time_ns();
float result2 = dot_productLoop(a, b, length);
tLoop2 = get_time_ns();
free(a);
free(b);
*tVec = tVec2 - tVec1;
*tLoop = tLoop2 - tLoop1;
}
int main() {
int maxCnt = 5000;
int64_t tVecs[maxCnt];
int64_t tLoops[maxCnt];
for (int i = 0;i<maxCnt;i++)
{
runTrial(i, &tVecs[i], &tLoops[i]);
printf("length %d completed!\nVec: %ld, Loop: %ld\n", i, tVecs[i], tLoops[i]);
}
FILE* file;
file = fopen("data.csv", "w");
fprintf(file, "tVec,tLoop\n");
for(int i = 0;i<maxCnt; i++)
{
fprintf(file, "%ld, %ld\n", tVecs[i], tLoops[i]);
}
fclose(file);
return 0;
}
|