编译随记
优化barrier

asm volatile ("mfence" :::"memory)- 这句话的意思是该汇编语句可能访问内存的任何位置,因此任何内存相关的优化不能穿过这句话

__sync_synchronize()- 这是编译器直接提供的一个barrier
- 假如不写volatile的话,编译器可能直接不考虑变量的读写访存问题直接进行优化,比如优化等级选择
-O1,-O2的话,可能会直接略过循环,给变量赋值一个终值 - 仅靠编译器是无法实现原子操作的,必须有处理器本身的支持
- PeterSon算法必须是使用原子操作的读写才可以,否则还是会出问题(虽然可能概率不大)
- 注意, 代码编译优化的时候不能够将其挪动到临界区外面(需要barrier),否则整个就会出错
- 前一条原子指令之前发生的事件,后一条原子指令都可见(也就是在他开始之前都完成了)

- 互斥锁的操作实际上是能进入的时候就进入,不能进入的时候就进入等待队列,切换到别的线程,防止全部阻塞
- 但是互斥锁在处理公用的锁的时候需要用到自旋锁来保护自己的状态不被打断
- 互斥锁不自旋,不会因为自选浪费CPU
- 实际上上互斥锁的操作比较复杂,对于短的临界区,使用互斥锁反而慢
- Unix系统中的管道是一个天然的既带有同步又带有数据传输的机制
手动原子指令

- 在某一条汇编指令前面加
lock,CPU对外有总线发送LOCK信号,会给予一个CPU内存的独占访问权限,直到这个信号结束,防止在指令执行完成期间内存被修改 - 原子指令做的事实际上就是将系统所有的执行流分成atmoic指令之前,和atomic指令之后,这两个是不可逾越不可互相交错的,相当于原子指令执行的过程中世界停止了,对于所有CPU核心或者所有其他进程线程而言
如何解决并发的问题
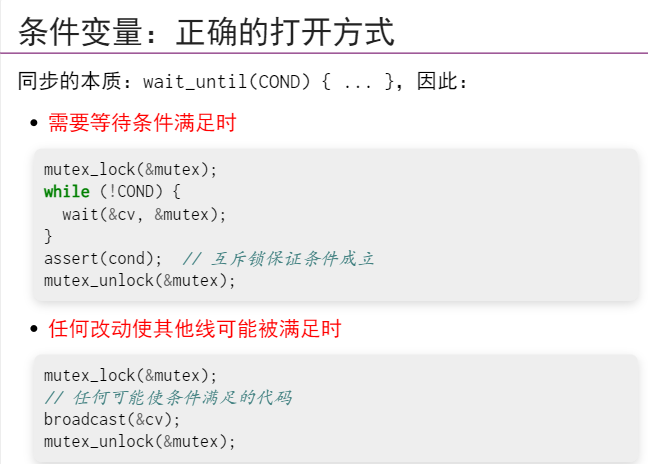
int n, count = 0;
mutex_t lk = MUTEX_INIT();
cond_t cv = COND_INIT();
void Tproduce() {
while (1) {
mutex_lock(&lk);
while (!CAN_PRODUCE) {
cond_wait(&cv, &lk);
}
printf("("); count++;
cond_broadcast(&cv);
mutex_unlock(&lk);
}
}
void Tconsume() {
while (1) {
mutex_lock(&lk);
while (!CAN_CONSUME) {
cond_wait(&cv, &lk);
}
printf(")"); count--;
cond_broadcast(&cv);
mutex_unlock(&lk);
}
}
int main(int argc, char *argv[]) {
assert(argc == 3);
n = atoi(argv[1]);
int T = atoi(argv[2]);
setbuf(stdout, NULL);
for (int i = 0; i < T; i++) {
create(Tproduce);
create(Tconsume);
}
}携程

- go语言对于线程的新处理方式(结合线程与携程)

package main
import (
"fmt"
"time"
)
func main() {
go spinner(100 * time.Millisecond)
const n = 45
fibN := fib(n) // slow
fmt.Printf("\rFibonacci(%d) = %d\n", n, fibN)
}
func spinner(delay time.Duration) {
for {
for _, r := range `-\|/` {
fmt.Printf("\r%c", r)
time.Sleep(delay)
}
}
}
func fib(x int) int {
if x < 2 { return x }
return fib(x - 1) + fib(x - 2)
}
- 注意,打印
\r实际上是使得光标回到行首,也就是可以实现在行首的同一个位置不停的重复打印字符的目的 - 比如go语言中进程间通信就是管道的方式
channelpackage main
import "fmt"
var stream = make(chan int, 10)
const n = 4
func produce() {
for i := 0; ; i++ {
fmt.Println("produce", i)
stream <- i
}
}
func consume() {
for {
x := <-stream
fmt.Println("consume", x)
}
}
func main() {
for i := 0; i < n; i++ {
go produce()
}
consume()
}为cuda编写程序
- 编写的是类似与C或者cpp的程序,但是使用
nvcc编译器进行编译,得到相应的结果 - cuda程序最好不要有分支
static uint32_t colors[MAX_ITER + 1];
static uint32_t data[DIM * DIM];
__device__ uint32_t mandelbrot(double x, double y) {
double zr = 0, zi = 0, zrsqr = 0, zisqr = 0;
int i;
for (i = 0; i < MAX_ITER; i++) {
zi = zr * zi * 2 + y;
zr = zrsqr - zisqr + x;
zrsqr = zr * zr;
zisqr = zi * zi;
if (zrsqr + zisqr > 4.0) {
break; // SIMT threads diverges here!
}
}
return i;
}
__global__ void mandelbrot_kernel(uint32_t *data, double xmin, double ymin, double step, uint32_t *colors) {
int pix_per_thread = DIM * DIM / (gridDim.x * blockDim.x);
int tId = blockDim.x * blockIdx.x + threadIdx.x;
int offset = pix_per_thread * tId;
for (int i = offset; i < offset + pix_per_thread; i++) {
int x = i % DIM;
int y = i / DIM;
double cr = xmin + x * step;
double ci = ymin + y * step;
data[y * DIM + x] = colors[mandelbrot(cr, ci)];
}
if (gridDim.x * blockDim.x * pix_per_thread < DIM * DIM
&& tId < (DIM * DIM) - (blockDim.x * gridDim.x)) {
int i = blockDim.x * gridDim.x * pix_per_thread + tId;
int x = i % DIM;
int y = i / DIM;
double cr = xmin + x * step;
double ci = ymin + y * step;
data[y * DIM + x] = colors[mandelbrot(cr, ci)];
}
}
int main() {
float freq = 6.3 / MAX_ITER;
for (int i = 0; i < MAX_ITER; i++) {
char r = sin(freq * i + 3) * 127 + 128;
char g = sin(freq * i + 5) * 127 + 128;
char b = sin(freq * i + 1) * 127 + 128;
colors[i] = b + 256 * g + 256 * 256 * r;
}
colors[MAX_ITER] = 0;
uint32_t *dev_colors, *dev_data;
cudaMalloc((void**)&dev_colors, sizeof(colors));
cudaMalloc(&dev_data, sizeof(data));
cudaMemcpy(dev_colors, colors, sizeof(colors), cudaMemcpyHostToDevice);
double xcen = -0.5, ycen = 0, scale = 3;
mandelbrot_kernel<<<512, 512>>>(
dev_data,
xcen - (scale / 2),
ycen - (scale / 2),
scale / DIM,
dev_colors
);
cudaMemcpy(data, dev_data, sizeof(data), cudaMemcpyDeviceToHost);
cudaFree(dev_data);
cudaFree(dev_colors);
FILE *fp = fopen("mandelbrot.ppm", "w");
fprintf(fp, "P6\n%d %d 255\n", DIM, DIM);
for (int i = 0; i < DIM * DIM; i++) {
fputc((data[i] >> 16) & 0xff, fp);
fputc((data[i] >> 8) & 0xff, fp);
fputc((data[i] >> 0) & 0xff, fp);
}
return 0;
}javaScript中的并发
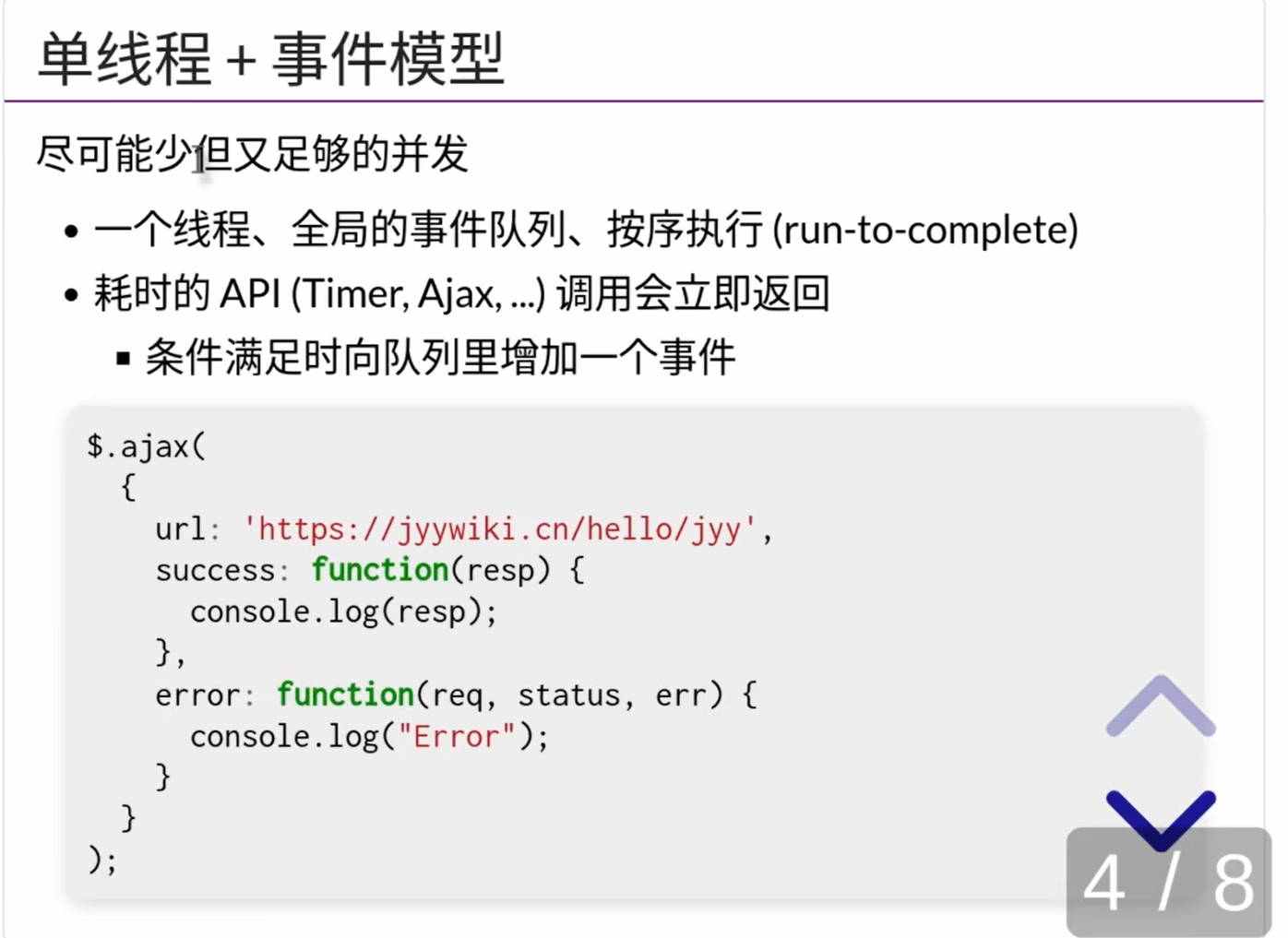
- JS的时间轴是不会被打断的,一个函数一定要运行到结束位置
- 假如函数中的有耗时的操作,这个耗时的操作会被移动到浏览器的后台执行,执行完成之后会有一个callback函数,此时浏览器切换到继续需要执行的回调函数
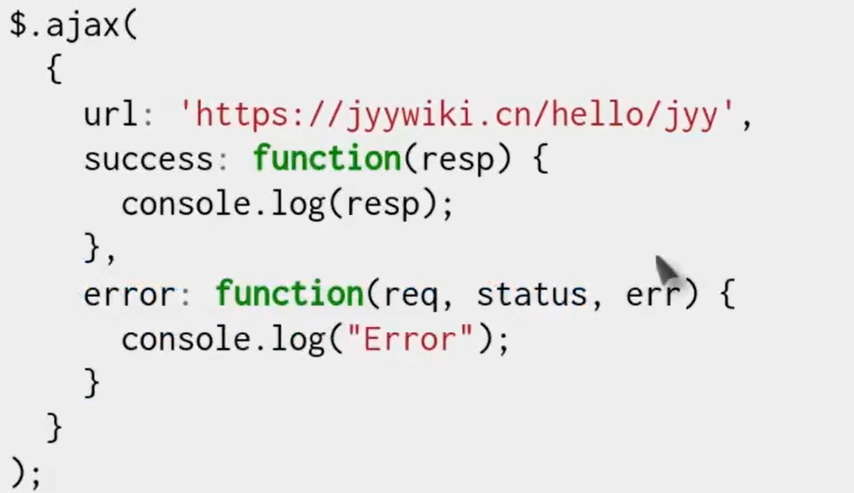
- 两个函数本质上都是回调函数
- 并且,假如耗时的步骤完成之后,系统中正在有其他函数执行,那么会等到其他函数执行结束之后在进行回调
- 所以不存在事件内与其他执行流并发的问题
解决$.ajax不便于维护的问题,引入Promise
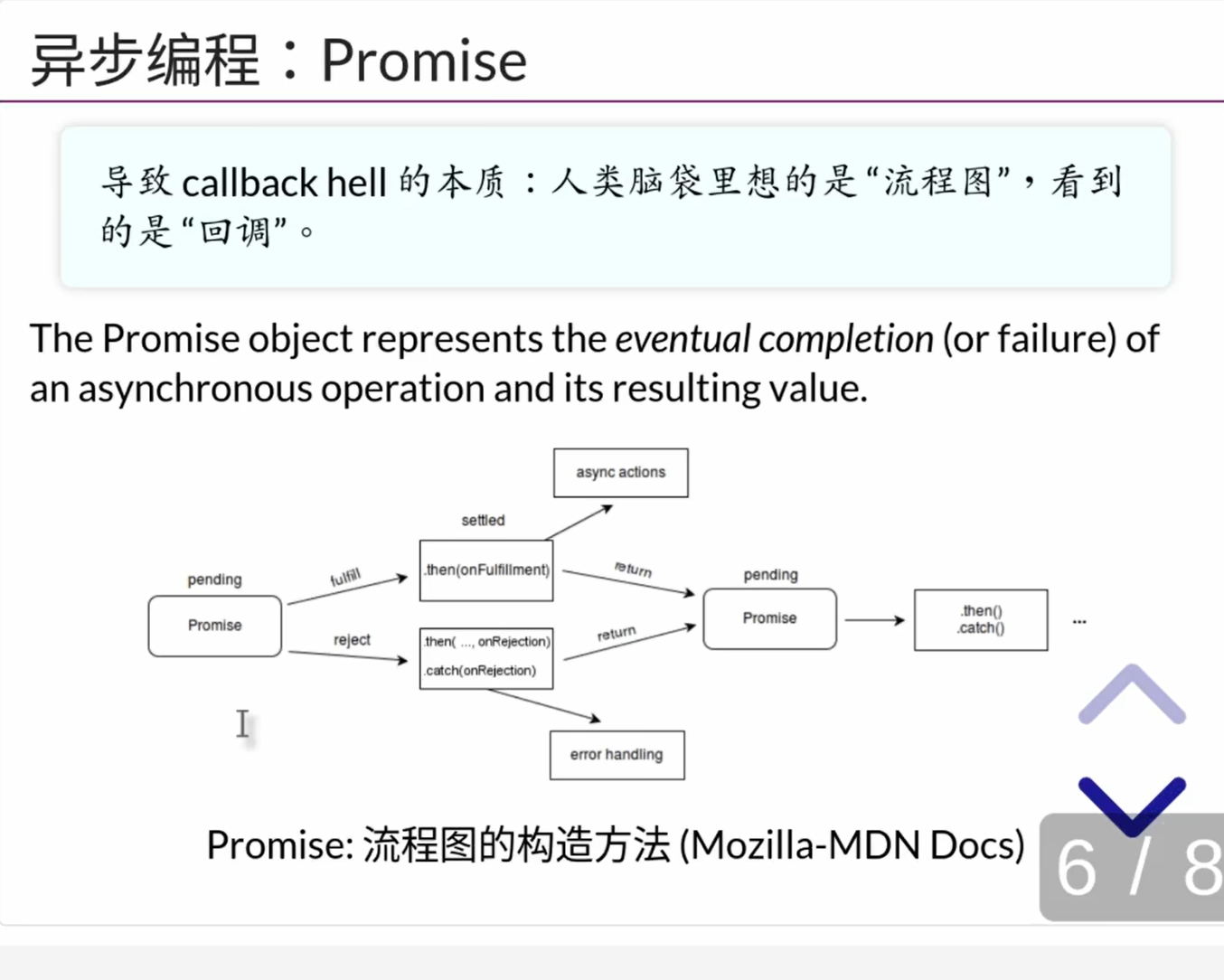

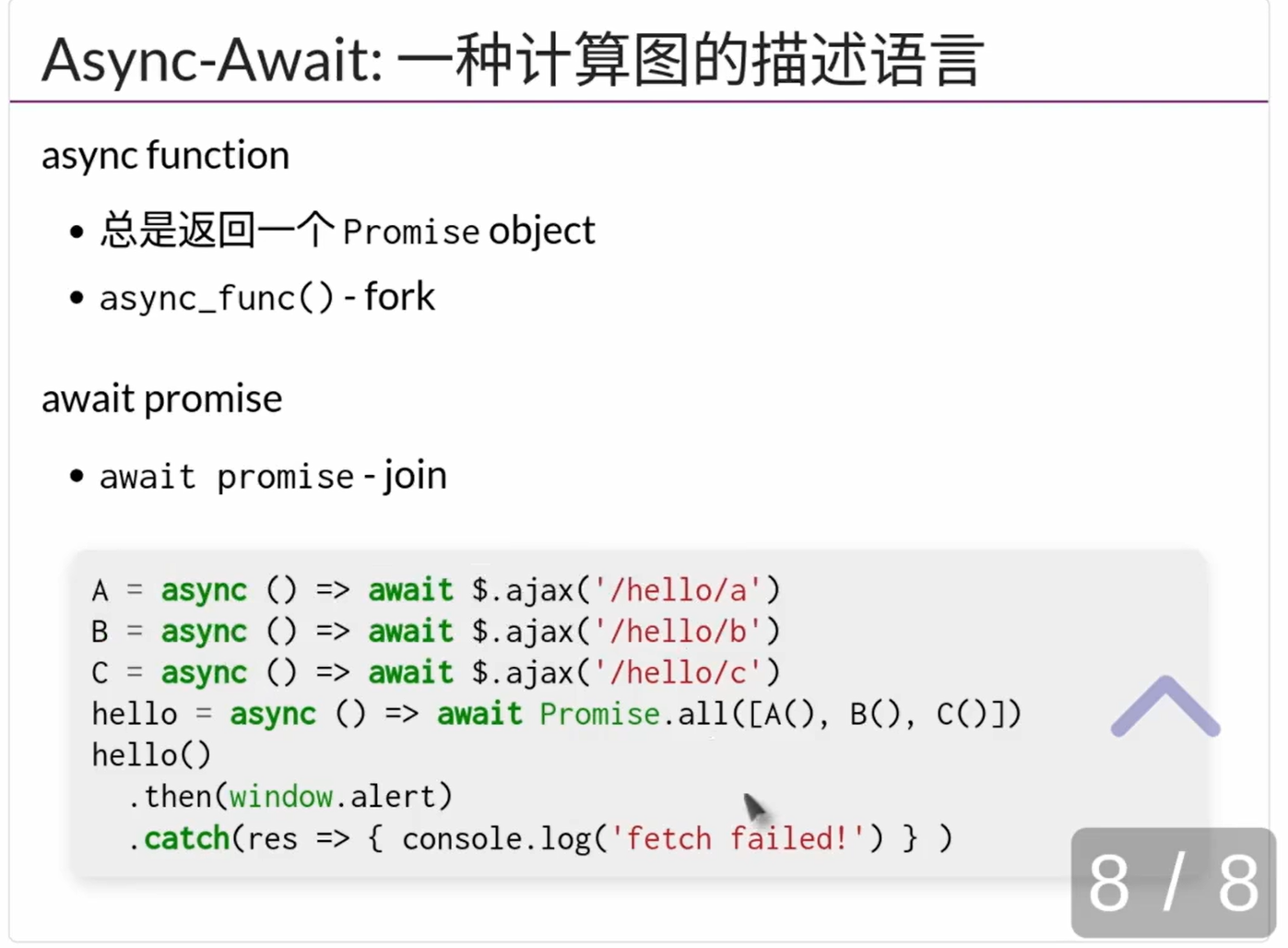
- 教程
避免死锁

- 比如解决哲学家吃饭问题,将所有的叉子从小到大编号,要求每个哲学家都先拿自己手边编号较小的叉子,再拿编号大的,所有人都按照同样的顺序拿叉子
编译器的线程消毒器选项
-fsanitize-thread 
- 辅助检查并发bug
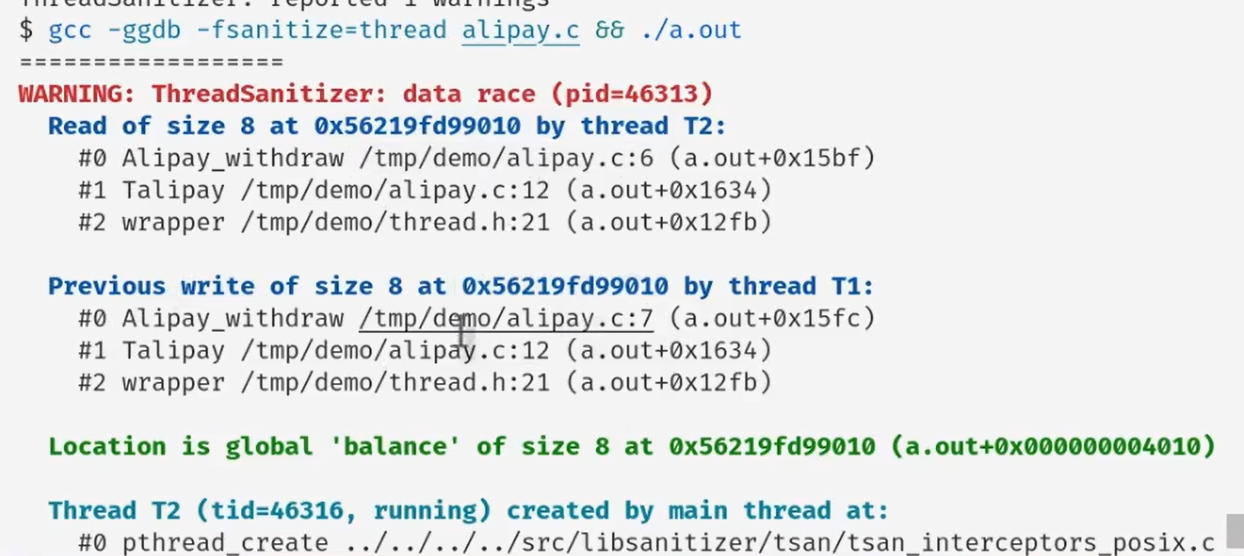
- 运行时检查内存访问
- 基本假设是每个线程里面的事件是顺序发生的
- 假如不同的线程之间访问同一片内存,但是这两个操作之间不存在一个线程先解锁,另一个线程再上锁的操作的话,就会导致data race问题
- 其他的
sanitizer - 比如可以检查是否操作了已经释放过的内存
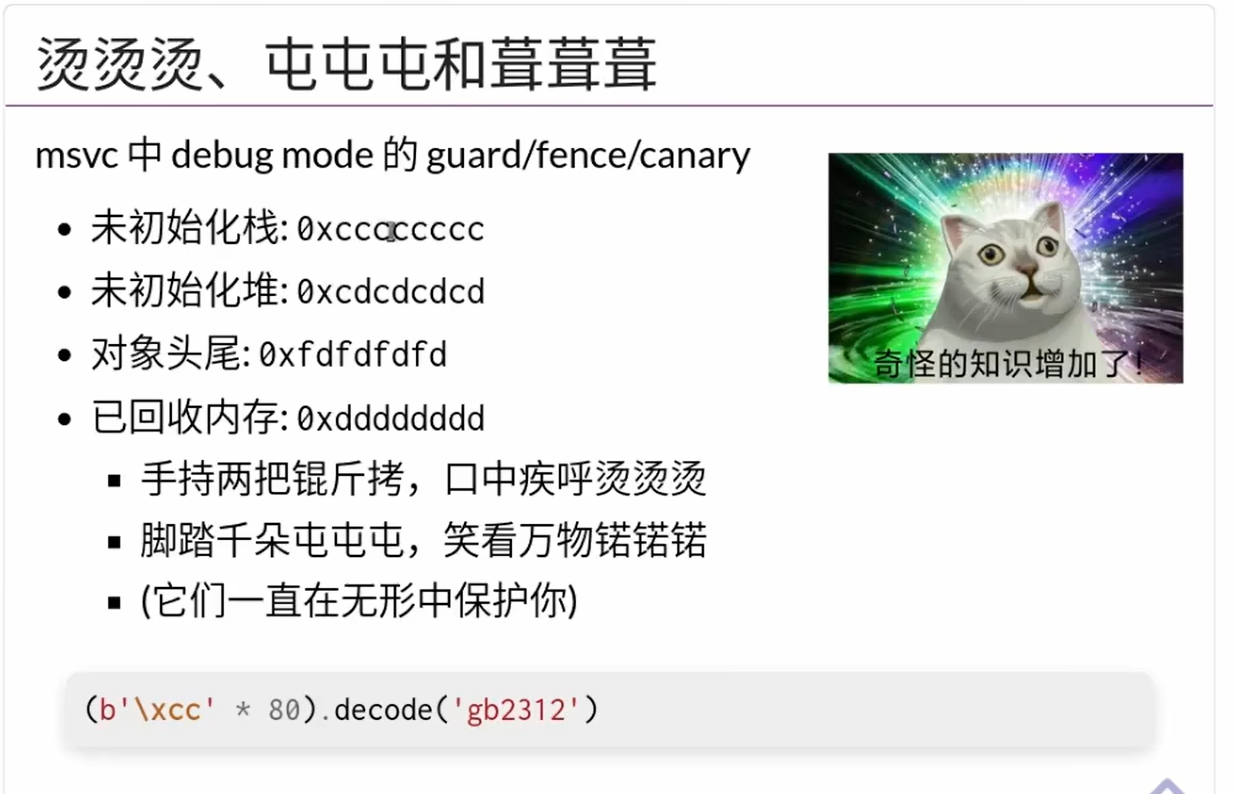
0xccccc...字符串在gb解码下是“烫烫烫烫…”oxcdcdcdcd...在gb解码下是“屯屯屯屯屯”
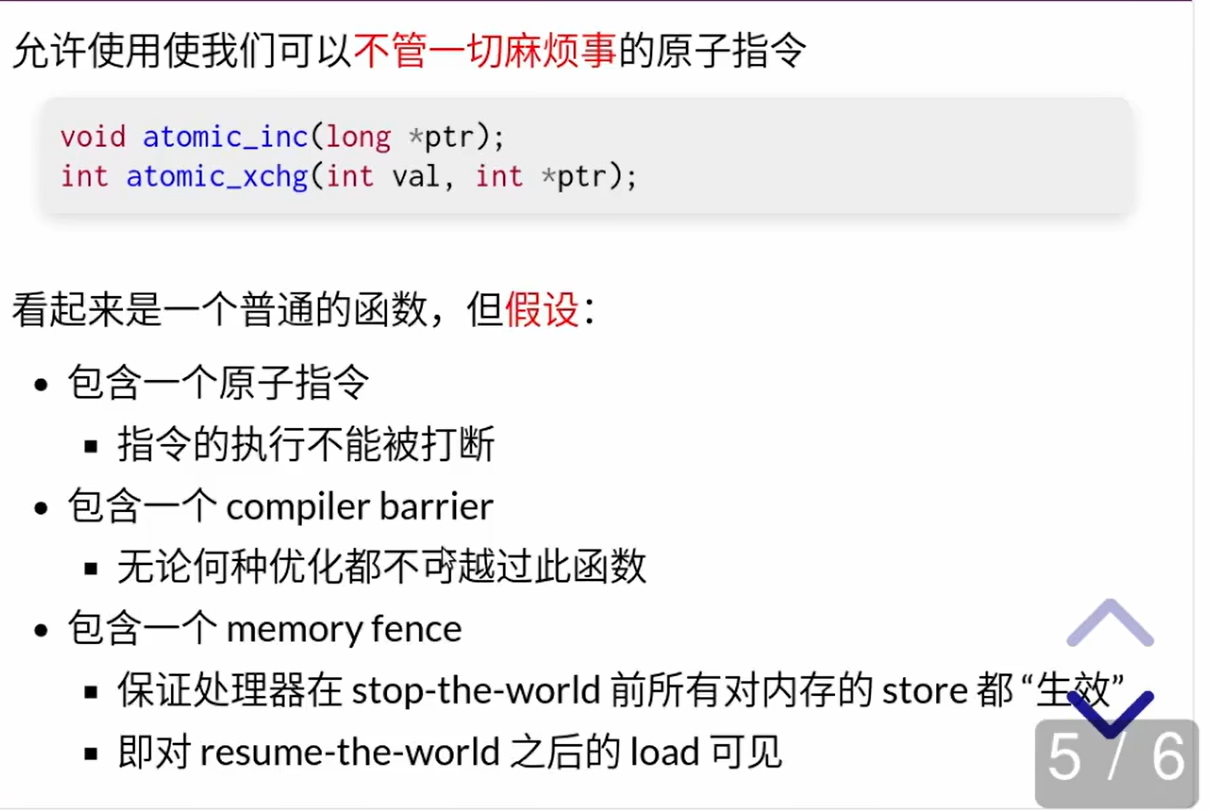



中断相关

- 关中断
- 在正常模式下,假如应用程序试图执行这个操作,CPU会直接产生中断,认为应用程序执行了非法操作

- 对于单处理器系统,关闭中断就可以实行互斥,再重新开中断之前都不会被打断
- 多处理器系统不适用
- 中断发生的时候中断处理程序会把所有的寄存器搬到内存里保存,再中断返回的时候又会把所有的寄存器数值搬回原来的位置
50行代码实现一个操作系统
- 头文件
// User-defined tasks
void func(void *arg) {
while (1) {
lock();
printf("Thread-%s on CPU #%d\n", arg, cpu_current());
unlock();
for (int volatile i = 0; i < 100000; i++) ;
}
}
Task tasks[] = {
{ .name = "A", .entry = func },
{ .name = "B", .entry = func },
{ .name = "C", .entry = func },
{ .name = "D", .entry = func },
{ .name = "E", .entry = func },
}; - .c文件
typedef union task {
struct {
const char *name;
union task *next;
void (*entry)(void *);
Context *context;
};
uint8_t stack[8192];
} Task; // A "state machine"
Task *currents[MAX_CPU];
int locked = 0; // A spin lock
void lock() { while (atomic_xchg(&locked, 1)); }
void unlock() { atomic_xchg(&locked, 0); }
Context *on_interrupt(Event ev, Context *ctx) {
if (!current) current = &tasks[0]; // First interrupt
else current->context = ctx; // Save pointer to stack-saved context
do {
current = current->next;
} while ((current - tasks) % cpu_count() != cpu_current());
return current->context; // Restore a new context
}
void mp_entry() {
yield(); // Self-trap; never returns
}
int main() {
cte_init(on_interrupt);
for (int i = 0; i < LENGTH(tasks); i++) {
Task *task = &tasks[i];
Area stack = (Area) { &task->context + 1, task + 1 };
task->context = kcontext(stack, task->entry, (void *)task->name);
task->next = &tasks[(i + 1) % LENGTH(tasks)];
}
mpe_init(mp_entry);
}防止循环被直接优化的方法
- 在for中使用
volatile的计数变量for (int volatile i = 0; i < 100000: i++);
- 上述代码中的
yield实际上是原地产生一个处理器中断 - 注意在Union中使用struct的方式
typedef union task {
struct {
const char *name;
union task *next;
void (*entry)(void *);
Context *context;
};
uint8_t stack[8192];
} Task; // A "state machine" - CPU是一种状态机的容器,操作系统的任务就是让CPU在不同的状态机之间轮换
创建新的进程

- 命令行允许
:作为标识符 - 一变二、二变四创建新的进程
进程树
- 所有进程都是从上一个进程fork(复制)出来的,多有状态都被复制了,包括PC指针等等,因此存在父子关系
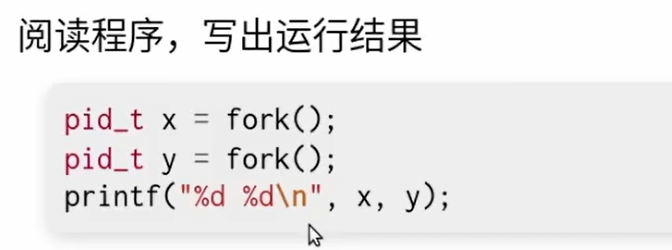
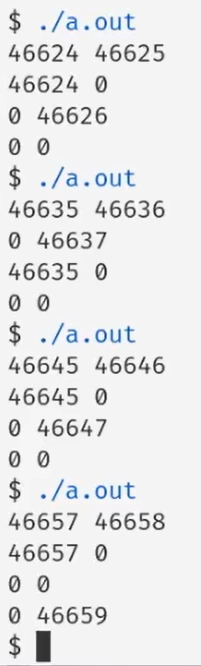
- 会产生四个进程
- 顺序不是确定的

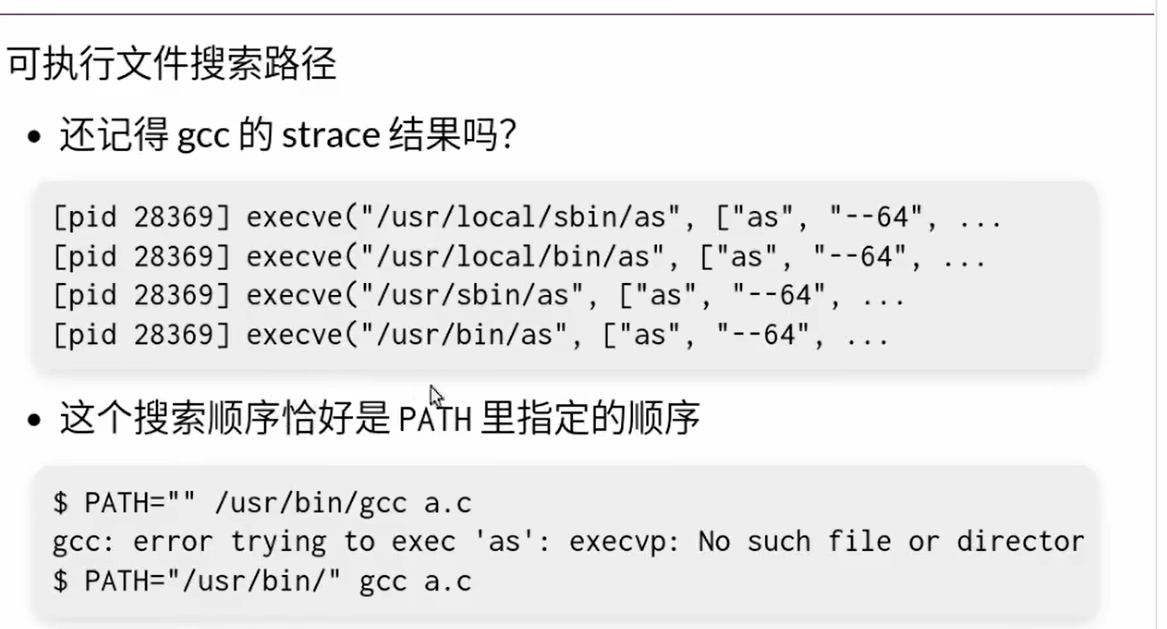
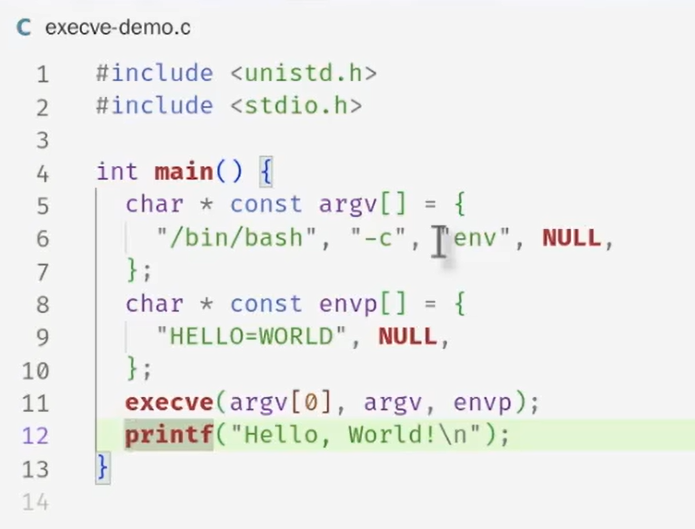
execve()- 的行为是把一个静态的状态机重置为传递给
execve的文件路径指向的可执行文件描述的初始状态,并且给main()函数传递argc,argv两个参数 
- 环境变量也是通过
execve传进去的,会继承父进程的环境变量 - 修改命令行的提示符

PS1变量
exit()
- 与C语言的库函数
exit区分开
- 与C语言的库函数

- 这个的作用是exit hook,就是在退出的执行一些处理后事的程序
- 这个程序只对C语言标准库中的
exit函数起作用,假如直接用系统调用的_exit,那么不会打印任何东西直接退出

- 多线程和单线程也是有区别的
