import argparse
import math
import pickle
import random
from collections import namedtuple
import matplotlib.pyplot as plt
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Normal
from torch.utils.data.sampler import BatchSampler, SubsetRandomSampler
import numpy as np
import time
torch.set_num_threads(12)
parser = argparse.ArgumentParser(description='Solve the Pendulum-v0 with PPO')
parser.add_argument(
'--gamma', type=float, default=0.9, metavar='G', help='discount factor (default: 0.9)')
parser.add_argument('--seed', type=int, default=0, metavar='N', help='random seed (default: 0)')
parser.add_argument('--render', action='store_true', help='render the environment')
parser.add_argument(
'--log-interval',
type=int,
default=10,
metavar='N',
help='interval between training status logs (default: 10)')
args = parser.parse_args()
torch.manual_seed(args.seed)
TrainingRecord = namedtuple('TrainingRecord', ['ep', 'reward'])
Transition = namedtuple('Transition', ['s', 'a', 'a_log_p', 'r', 's_'])
class ActorNet(nn.Module):
def __init__(self):
super(ActorNet, self).__init__()
self.fc = nn.Linear(3, 200)
self.mu_head = nn.Linear(200, 1)
self.sigma_head = nn.Linear(200, 1)
def forward(self, x):
x = F.relu(self.fc(x))
mu = 2.0 * torch.tanh(self.mu_head(x))
sigma = F.softplus(self.sigma_head(x))
return (mu, sigma)
class CriticNet(nn.Module):
def __init__(self):
super(CriticNet, self).__init__()
self.fc = nn.Linear(3, 200)
self.hidden = nn.Linear(200, 200)
self.v_head = nn.Linear(200, 1)
def forward(self, x):
x = F.relu(self.fc(x))
x = F.relu(self.hidden(x))
state_value = self.v_head(x)
return state_value
class Agent():
clip_param = 0.1
max_grad_norm = 0.5
ppo_epoch = 5
buffer_capacity, batch_size = 1000, 32
def __init__(self):
self.training_step = 0
self.anet = ActorNet().float()
self.cnet = CriticNet().float()
self.buffer = []
self.counter = 0
self.optimizer_a = optim.Adam(self.anet.parameters(), lr=4e-5)
self.optimizer_c = optim.Adam(self.cnet.parameters(), lr=6e-5)
def select_action(self, state):
state = torch.from_numpy(state).float().unsqueeze(0)
with torch.no_grad():
(mu, sigma) = self.anet(state)
dist = Normal(mu, sigma)
action = dist.sample()
action_log_prob = dist.log_prob(action)
action = action.clamp(-2.0, 2.0)
return action.item(), action_log_prob.item()
def get_value(self, state):
state = torch.from_numpy(state).float().unsqueeze(0)
with torch.no_grad():
state_value = self.cnet(state)
return state_value.item()
def save_param(self):
torch.save(self.anet.state_dict(), 'param/ppo_anet_params.pkl')
torch.save(self.cnet.state_dict(), 'param/ppo_cnet_params.pkl')
def store(self, transition):
if len(self.buffer)>=self.buffer_capacity:
tmp = np.random.randint(low=0, high=len(self.buffer))
if self.buffer[tmp].r > transition.r:
if np.random.randint(low=0, high=3) == 1:
self.buffer[tmp] = transition
self.buffer[tmp] = transition
else:
self.buffer.append(transition)
self.counter += 1
return self.counter % self.buffer_capacity == 0
def update(self):
self.training_step += 1
self.counter = 1
s = torch.tensor([t.s for t in self.buffer], dtype=torch.float)
a = torch.tensor([t.a for t in self.buffer], dtype=torch.float).view(-1, 1)
r = torch.tensor([t.r for t in self.buffer], dtype=torch.float).view(-1, 1)
s_ = torch.tensor([t.s_ for t in self.buffer], dtype=torch.float)
old_action_log_probs = torch.tensor(
[t.a_log_p for t in self.buffer], dtype=torch.float).view(-1, 1)
r = (r - r.mean()) / (r.std() + 1e-5)
with torch.no_grad():
target_v = r + args.gamma * self.cnet(s_)
adv = (target_v - self.cnet(s)).detach()
for _ in range(self.ppo_epoch):
for index in BatchSampler(
SubsetRandomSampler(range(self.buffer_capacity)), self.batch_size, False):
(mu, sigma) = self.anet(s[index])
dist = Normal(mu, sigma)
action_log_probs = dist.log_prob(a[index])
ratio = torch.exp(action_log_probs - old_action_log_probs[index])
surr1 = ratio * adv[index]
surr2 = torch.clamp(ratio, 1.0 - self.clip_param,
1.0 + self.clip_param) * adv[index]
action_loss = -torch.min(surr1, surr2).mean()
self.optimizer_a.zero_grad()
action_loss.backward()
nn.utils.clip_grad_norm_(self.anet.parameters(), self.max_grad_norm)
self.optimizer_a.step()
value_loss = F.smooth_l1_loss(self.cnet(s[index]), target_v[index])
self.optimizer_c.zero_grad()
value_loss.backward()
nn.utils.clip_grad_norm_(self.cnet.parameters(), self.max_grad_norm)
self.optimizer_c.step()
flagVar = False
pendulumGoal = [1.0, 0.0, 0.0]
def rewardFunc(goal, state, absMax):
tmp = -(np.power(state[0] - goal[0], 2) + 1*np.power(state[1] - goal[1], 2) + 0.1 * np.power(state[2] - goal[2], 2))
return (tmp + absMax)/absMax
def main():
global flagVar
env = gym.make('Pendulum-v1')
agent = Agent()
training_records = []
running_reward = -1000
TRAIN_EPISODE = 1000
EPISODE_LENGTH = 200
for i_ep in range(TRAIN_EPISODE):
score = 0
state = np.array(env.reset()[0])
start = time.time()
if i_ep == 0:
firstY = []
if i_ep == TRAIN_EPISODE-1:
lastX = [i for i in range(EPISODE_LENGTH)]
lastY = []
for t in range(EPISODE_LENGTH):
action, action_log_prob = agent.select_action(state)
envRet = env.step([action])
state_, reward, done, _, _ = envRet
if i_ep == TRAIN_EPISODE-1:
lastY.append(math.acos(state_[0]))
elif i_ep == 0:
firstY.append(math.acos(state_[0]))
if agent.store(Transition(state, action, action_log_prob, (reward + 8) / 8, state_)):
agent.update()
score += reward
state = state_
running_reward = running_reward * 0.85 + score * 0.1
training_records.append(TrainingRecord(i_ep, running_reward))
if i_ep % args.log_interval == 0:
print('Ep {}\tMoving average score: {:.2f}\t'.format(i_ep, running_reward))
time_ = time.time()
print("time used is {:.5f}".format(time_ - start))
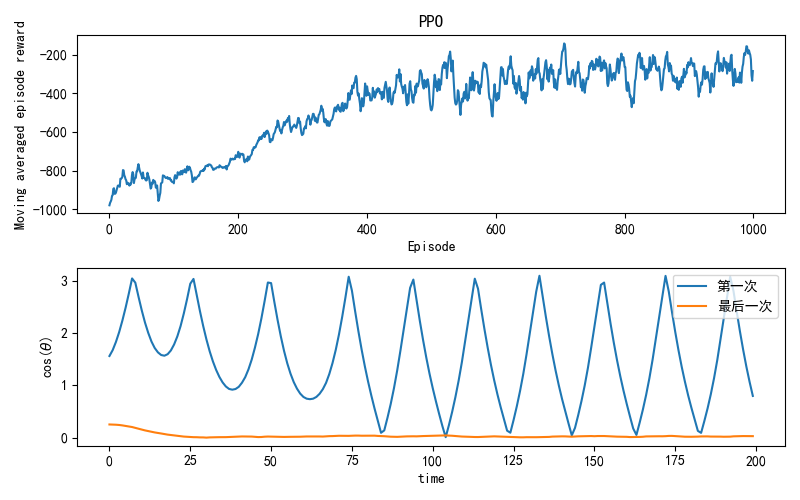
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.subplot(2,1,1)
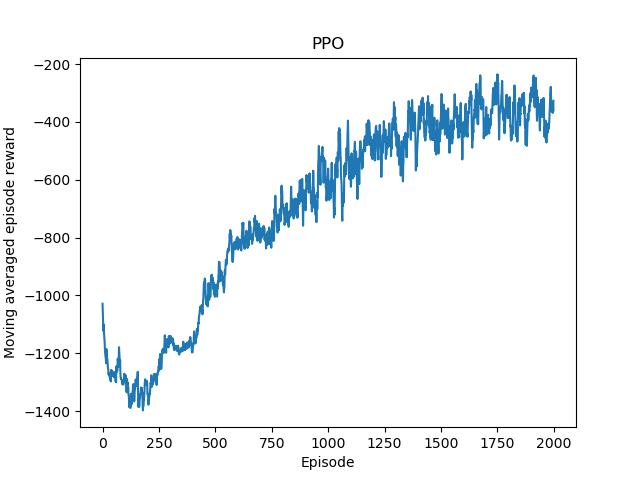
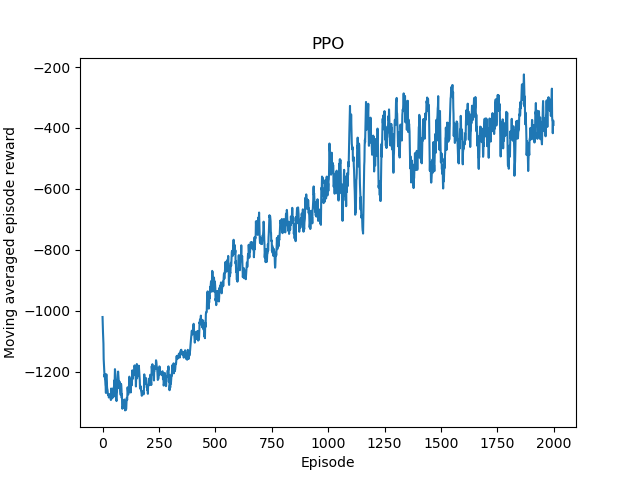
plt.plot([r.ep for r in training_records], [r.reward for r in training_records])
plt.title('PPO')
plt.xlabel('Episode')
plt.ylabel('Moving averaged episode reward')
plt.subplot(2,1,2)
plt.plot(lastX, firstY, label="第一次")
plt.plot(lastX, lastY, label="最后一次")
plt.ylabel("cos("+r'$\theta$'+")")
plt.xlabel("time")
plt.legend()
plt.tight_layout()
plt.show()
if __name__ == '__main__':
main()
|