0%
Hindsight Experience Replay
- 原文
- Hindsight experience replay
- Advances in neural information processing systems
- 参考链接
方法
- 你得知道从状态S到目标goal的映射关系(以机械臂为例,状态可能是多个关节的角度,目标是三维空间一个点的坐标,如果知道状态,那么也能推算出机械臂末端在空间中的坐标);
- 你得建立一个新的reward计算机制,它取决于目标goal和状态S,一般当状态S映射的goal’与goal相近时给予奖励;
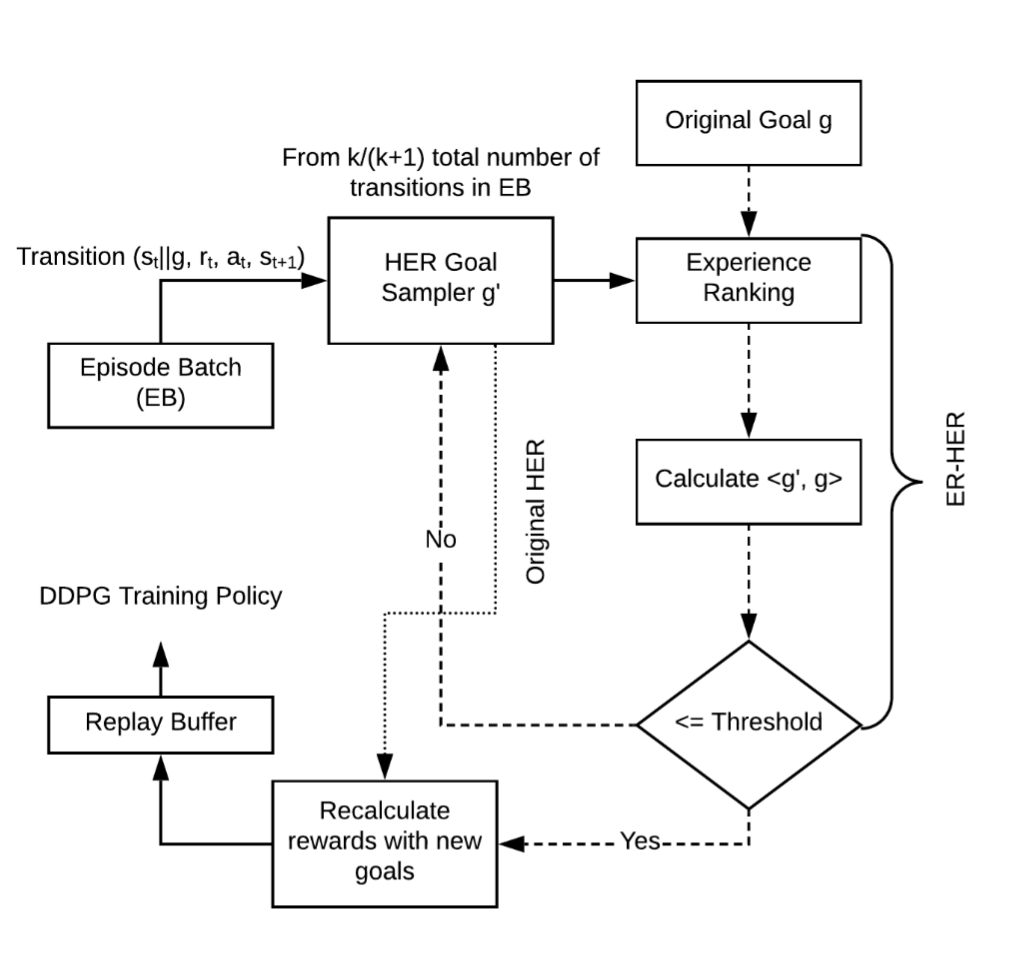
- 你得创建一个记录每个episode transition的列表,它的作用是在每个episode结束后进行事后经验回放,具体回放方法之后讲;
- RL算法接受的状态维度相较于原始的维度增加了目标goal的维度,也就是RL接受:

举例的github
- HER举例
- 这里episode_cache为存储transition的列表((s1,a1,r1,s1’),(s2,a2,r2,s2’)…),枚举这个列表的元素。在第二句根据每个transition产生HER_SAMPLE_NUM个新的目标点new_goals,这些目标点时根据之后的transition的state推算得到的,当然一种简单的情况就是state。之后对这些new_goals做遍历,对每一个new_goal都重新计算reward,并将transition中s和s’的goal部分替换为new_goal,之后将这个新的transition存储入经验池buffer。这里之所以可以这么做是因为在动作a不变的情况下,改变goal是不会改变从原来的s转移到s’的转移概率的。
- 先对每个回合中的所有输入做一个reward的评价
- 然后在整个回合的数据后处理时,循环到i时,从i之后的数据里随机选出一部分作为新的goal,然后利用这些新的goal重新计算i这个数据的reward,然后将其放入到replay buffer中,可能导致replay buffer中包含多条由同一条数据而来但是reward不同的数据条目
- 可以在每训练一个回合之后更换初始的goal(也就是在筛选之前针对所有对象的goal)达到多目标训练的效果
- 示例代码