-
Policy Gradient
基本上就是通过动作获得的奖励或者惩罚信息反向传播,给
Actor网络进行指导Critic实际上是一个类似于QNetwork的网络,它的作用是对Actor的动作做出每个时刻的评价,之前只能在回合结束的时候根据给出的回报进行更新,但是拥有Critic之后就可以在每个时刻进行更新了,也就是**在一个回合结束之前,猜测出这个动作可能导致的reward,并以此指导Actor**。例子
import argparse
import gym
import numpy as np
from itertools import count
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.99, metavar='G',
help='discount factor (default: 0.99)')
parser.add_argument('--seed', type=int, default=543, metavar='N',
help='random seed (default: 543)')
parser.add_argument('--render', action='store_true',
help='render the environment')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='interval between training status logs (default: 10)')
args = parser.parse_args()
env = gym.make('CartPole-v1')
env.seed(args.seed)
torch.manual_seed(args.seed)
class Policy(nn.Module):
def __init__(self):
super(Policy, self).__init__()
self.affine1 = nn.Linear(4, 128)
self.dropout = nn.Dropout(p=0.6)
self.affine2 = nn.Linear(128, 2)
self.saved_log_probs = []
self.rewards = []
def forward(self, x):
x = self.affine1(x)
x = self.dropout(x)
x = F.relu(x)
action_scores = self.affine2(x)
return F.softmax(action_scores, dim=1)
policy = Policy()
optimizer = optim.Adam(policy.parameters(), lr=1e-2)
eps = np.finfo(np.float64).eps.item()
def select_action(state):
state = torch.from_numpy(state).float().unsqueeze(0)
probs = policy(state)
m = Categorical(probs)
action = m.sample()
policy.saved_log_probs.append(m.log_prob(action))
return action.item()
def finish_episode():
R = 0
policy_loss = []
returns = []
for r in policy.rewards[::-1]:
R = r + args.gamma * R
returns.insert(0, R)
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + eps)
for log_prob, R in zip(policy.saved_log_probs, returns):
policy_loss.append(-log_prob * R)
optimizer.zero_grad()
policy_loss = torch.cat(policy_loss).sum()
policy_loss.backward()
optimizer.step()
del policy.rewards[:]
del policy.saved_log_probs[:]
def main():
running_reward = 10
for i_episode in count(1):
state, ep_reward = env.reset(), 0
for t in range(1, 10000): # Don't infinite loop while learning
action = select_action(state)
state, reward, done, _ = env.step(action)
if args.render:
env.render()
policy.rewards.append(reward)
ep_reward += reward
if done:
break
running_reward = 0.05 * ep_reward + (1 - 0.05) * running_reward
finish_episode()
if i_episode % args.log_interval == 0:
print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(
i_episode, ep_reward, running_reward))
if running_reward > env.spec.reward_threshold:
print("Solved! Running reward is now {} and "
"the last episode runs to {} time steps!".format(running_reward, t))
torch.save(policy.state_dict(),'hello.pt')
break
if __name__ == '__main__':
main()Categorical:
给出策略的具体操作是先将输入经过一系列网络的运算之后,经过softmax归一化,得到和为1的几个输出。然后在输出过程中对于具有这几种概率的输出进行随机取样,得到最终的输出动作。(离散动作)
针对连续动作,可以将整个网络的输出更改为输出一个高斯分布函数的μ值(均值),结合用户指定的σ(方差),即可形成一个高斯分布,然后通过类似的sample采样即可得出需要的动作。注意训练阶段为了实现有效的exploration,不要使用太小的σ,否则因为输出太集中没法找到实际上的最优解。
- 也可以让网络也输出σ
- 反向传播的思路相似,也是直接利用
torch.Distributions.Normal的log_prob函数输出概率的log值
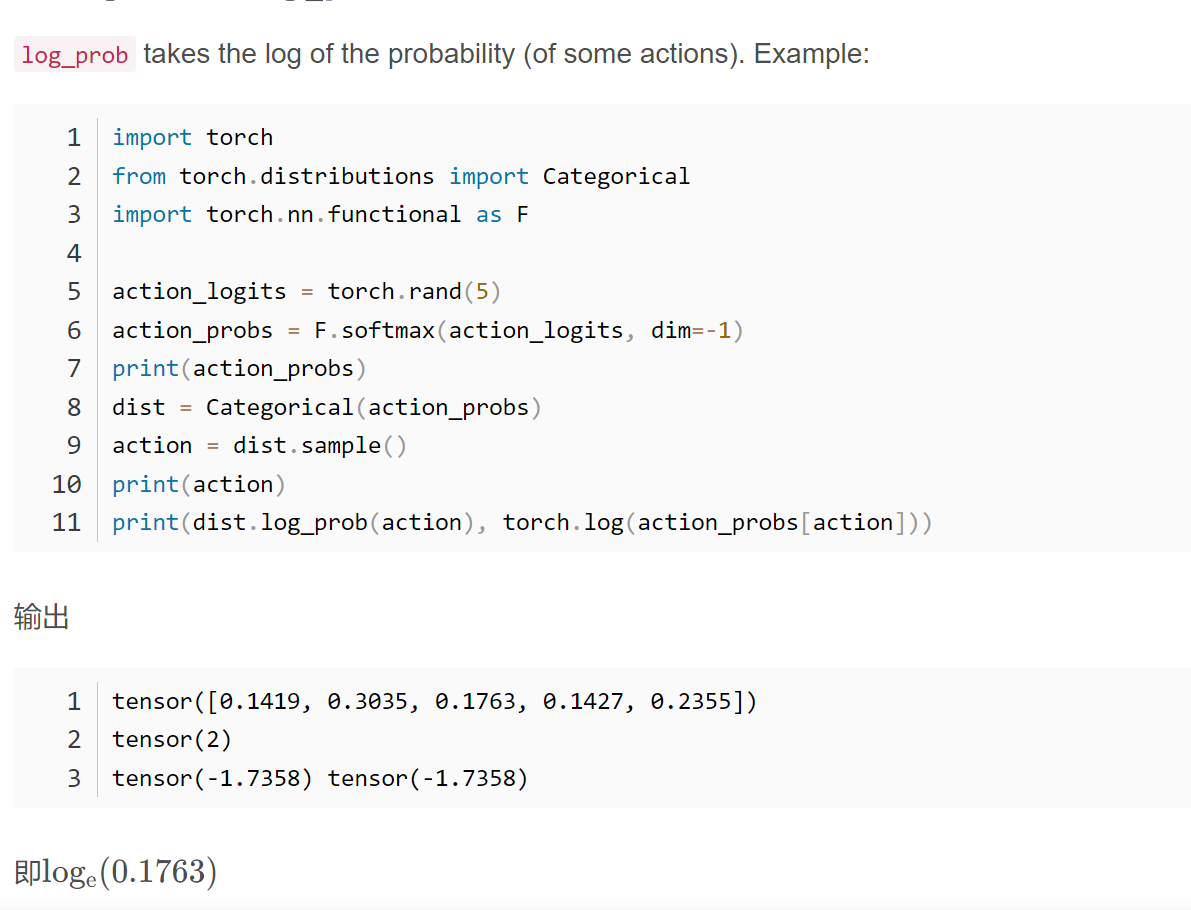 ,实际上就是将对应动作发生的可能性求了log
,实际上就是将对应动作发生的可能性求了log网络更新

DDPG
- 现在我们来说说 DDPG 中所用到的神经网络. 它其实和我们之前提到的 Actor-Critic 形式差不多, 也需要有基于 策略 Policy 的神经网络 和基于 价值 Value 的神经网络, 但是为了体现 DQN 的思想, 每种神经网络我们都需要再细分为两个, Policy Gradient 这边, 我们有估计网络和现实网络, 估计网络用来输出实时的动作, 供 actor 在现实中实行. 而现实网络则是用来更新价值网络系统的. 所以我们再来看看价值系统这边, 我们也有现实网络和估计网络, 他们都在输出这个状态的价值, 而输入端却有不同, 状态现实网络这边会拿着从动作现实网络来的动作加上状态的观测值加以分析, 而状态估计网络则是拿着当时 Actor 施加的动作当做输入.在实际运用中, DDPG 的这种做法的确带来了更有效的学习过程.

学习的过程
Critic网络
y_true是要学习的值,这个值是通过Critci的target网络对于下一时刻的actor的target网络的动作做出的评估加上这一时刻的汇报reward计算出来的,而它自身需要修改的值就是直接对当前的环境观测和动作做出的值的判断y_preddef critic_learn():
a1 = self.actor_target(s1).detach()
y_true = r1 + self.gamma * self.critic_target(s1, a1).detach()
y_pred = self.critic(s0, a0)
loss_fn = nn.MSELoss()
loss = loss_fn(y_pred, y_true)
self.critic_optim.zero_grad()
loss.backward()
self.critic_optim.step()- 然后按照一定的比例
soft_update对应的target网络即可Actor网络
- 直接利用
critic网络对于此刻环境的观测和在此刻环境下actor网络的行为做出评价,然后直接反向传播 - 同样
soft_update另一个target网络即可def actor_learn():
loss = -torch.mean( self.critic(s0, self.actor(s0)) )
self.actor_optim.zero_grad()
loss.backward()
self.actor_optim.step()A3C
- pytorch A3C参考



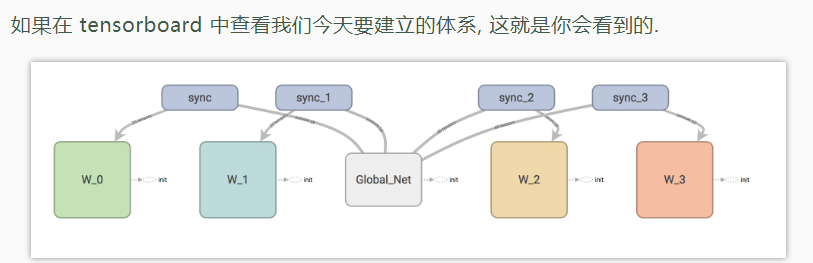
- 实际上每个本地网络都是一个Actor-Critic的网络,损失分为动作网络
Actor的loss和Critic网络的loss- Critic的loss可以先计算
td_error,用Critic在此时的环境中计算出的值与实际上每一步得到的增加随时间衰减的因子之后的实际上的Reward做差,然后平方即可得到Critic的loss - Actor的loss则是使用反向求出刚才动作的log_prob(怎么求上文有),然后再求出
entropy,公式为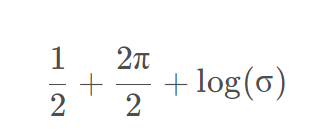 ,然后log_prob×上文的td_error+一个系数×entropy,然后整个计算出来之后取相反数即可得到Actor的loss,然后将整个的两个loss取平均数,反向传播更新参数即可(因为根据计算图倒推可以分别得到组成这个变量的两个变量分别的影响因素,所以不影响反向传播分别更新两个网络)。
,然后log_prob×上文的td_error+一个系数×entropy,然后整个计算出来之后取相反数即可得到Actor的loss,然后将整个的两个loss取平均数,反向传播更新参数即可(因为根据计算图倒推可以分别得到组成这个变量的两个变量分别的影响因素,所以不影响反向传播分别更新两个网络)。torch中backword是怎么用的
- Critic的loss可以先计算
- 针对标量做出的对计算图的反向传播,得到标量的值,算出计算图中每个变量对于得到这个标量的偏导数参考