针对连续的Q的情况而将Q从表格替换为网络
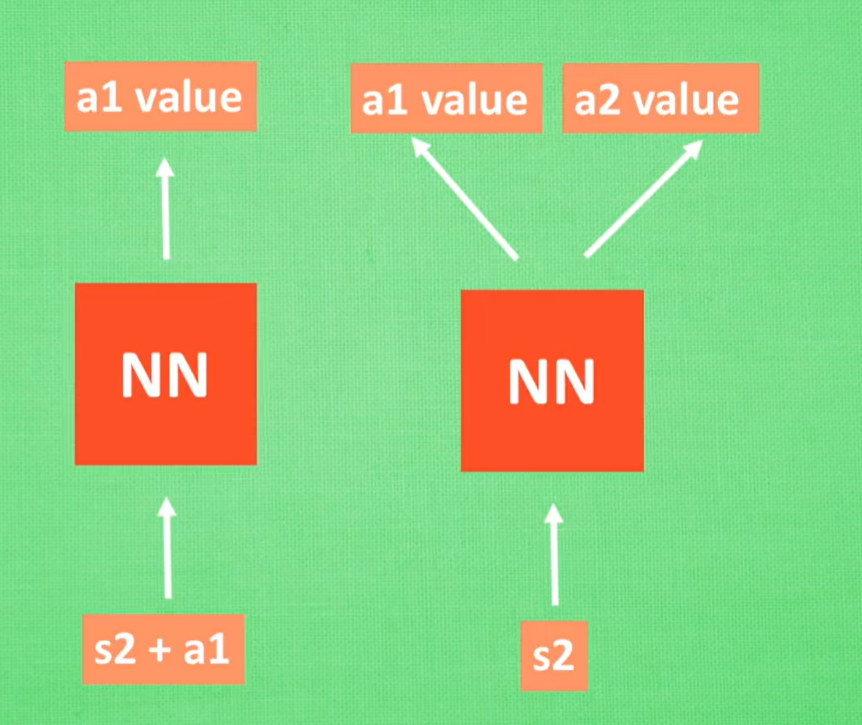
- Q网络具有两种思路,一种是输入环境和动作给出一个Q,另一个是输入一个环境,给出一些动作和动作对应的值

- 因为不断的变化导致整个Q网络训练的过程中很难收敛
- 实际上是用旧的Q网络参数得出Q结论,用这个结论计算与实际的Q的偏差更新新的Q网络,防止利用同一个网络计算参数的同时更新参数导致整个网络反复横跳,难于收敛。




- Double DQN和一般的DQN只有计算
QTarget的时候不同,网络结构是相同的 - 进一步阐述
- 将估计目标价值的问题从直接用
QTarget变成了使用QEval(也就是具有新参数的网络)先估计出下个时刻的动作(也就是选出具有最大回报的动作),再用具有旧参数的QTarget估计出下一时刻这个动作的价值,然后用这个去更新QEval记忆池增加优先级功能


优势函数



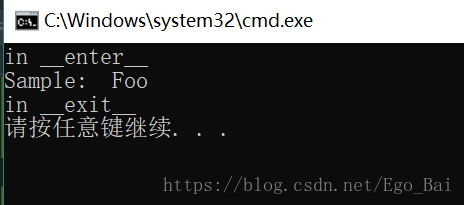
插入:python中with的用法:

- with的主要作用是进入被调用对象的
enter方法,然后在with语句结束之后,自动调用对象的exit方法######################
########with()##########
######################
class Sample:
def __enter__(self):
print("in __enter__")
return "Foo"
def __exit__(self, exc_type, exc_val, exc_tb):
#exc_type: 错误的类型
#exc_val: 错误类型对应的值
#exc_tb: 代码中错误发生的位置
print("in __exit__")
def get_sample():
return Sample()
with get_sample() as sample:
print("Sample: " ,sample) - 输出为