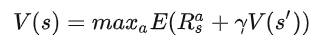马尔可夫过程

注意,并不是说与之前的状态绝对意义上的无关,而是在t时刻之前的信息全部已知的情况下,只通过t时刻就可做出判断。也就是意味着,t时刻之前的状态对于待得到的t+1时刻的状态的影响全部体现在t时刻的信息中了。
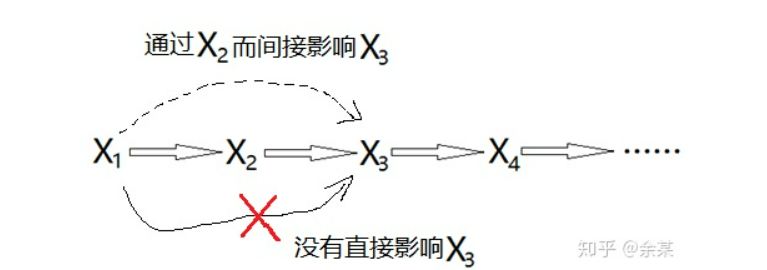

注意,非常关键的是在定义一个
状态的时候,如何让这个状态包含计算出下个状态所需要的所有信息马尔可夫决策过程
时齐性
时间连续的问题

基于策略还是基于价值
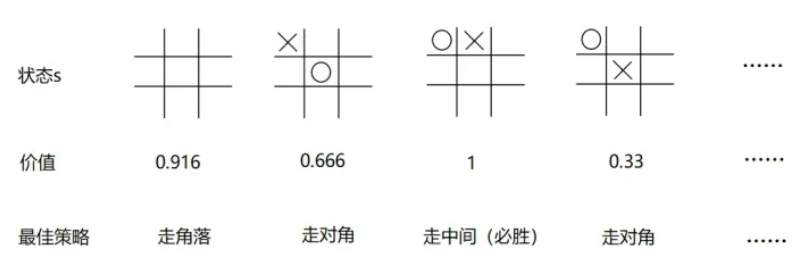

总结

基于价值的方法和基于策略的方法

基于价值方法的核心思想在于对时间的差分,是一种动态规划的思想;而基于策略的方法则没有这种思想,而是要通盘考虑策略在整个时间轨道内造成的影响

Q值的思想

基于价值的基本解决方法


对于表格学习的QLearning实际上是一种用动态规划的方法每一步都修改一下对应位置的Q值的算法
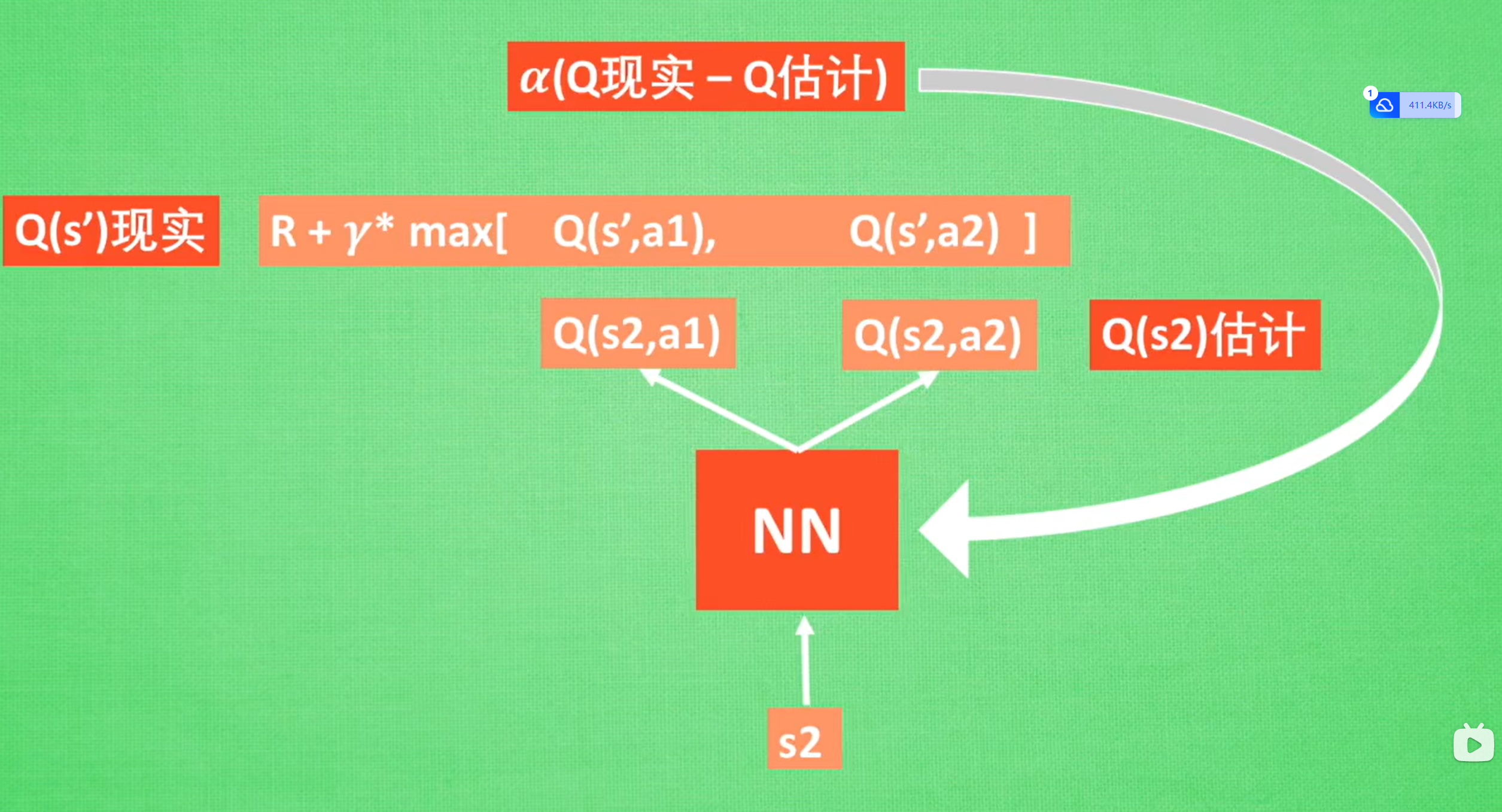
Q更新的思路:在每次尝试结束之后,将这次尝试得到的价值更新到Q网络预测的价值上
on policy 和 off policy的区别

一个通俗的比喻