- 原文链接
Policy gradient网络复习
给出行为act的思路
- 一个特定的情况序列(时间从0时刻到一个回合结束的时刻)发生的概率是可以计算的
- 平均的reward期望是每种情况发生的概率×每个情况对应的reward的和
- 优化的目标是尽可能的提高总的reward的期望
- 按照上面的说法,针对一个回合的训练,必须等到这个回合结束之后才能利用这个回合的reward对其进行参数调整,而且这样会导致一个回合中的每个动作的reward都使用同样的数值,很不精确
- 所以我们此时就使用critic网络计算出当前这个动作
st开始到回合结束时刻的奖励 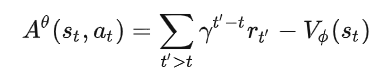

- 可以理解为在
st时刻,采取at行动比采取其他行动的优势有多大PPO算法
- 接着上面的讲,PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个agent;与之对应的就是off-policy的策略,即想要训练的agent和与环境进行交互的agent不是同一个agent,简单来说,就是拿别人的经验来训练自己。举个下棋的例子,如果你是通过自己下棋来不断提升自己的棋艺,那么就是on-policy的,如果是通过看别人下棋来提升自己,那么就是off-policy的
重要性采样
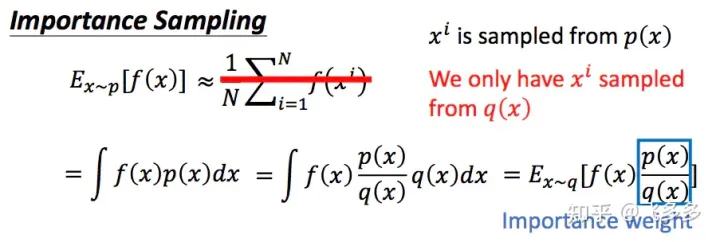
- 对于一个服从概率p分布的变量x, 我们要估计f(x) 的期望。直接想到的是,我们采用一个服从p的随机产生器,直接产生若干个变量x的采样,然后计算他们的函数值f(x),最后求均值就得到结果。但这里有一个问题是,对于每一个给定点x,我们知道其发生的概率,但是我们并不知道p的分布,也就无法构建这个随机数发生器。因此需要转换思路:从一个已知的分布q中进行采样。通过对采样点的概率进行比较,确定这个采样点的重要性。也就是上图所描述的方法。
- 当然通过这种采样方式的分布p和q不能差距过大,否则,会由于采样的偏离带来谬误。


- 引入上文中说的优势函数可知
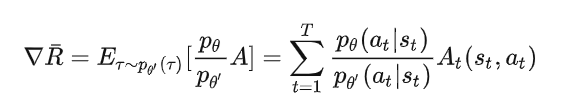

- 一套策略参数θ,他与环境交互收集批量数据,然后批量数据关联到 的副本中。他每次都会被更新。
- 一套策略参数的副本θ’,他是策略参数与环境互动后收集的数据的关联参数,相当于重要性采样中的q分布。
- 一套评价网络的参数Φ,他是基于收集到的数据,用监督学习的方式来更新对状态的评估。他也是每次都更新。
- 更新的思路实际上是
- 0点时:我与环境进行互动,收集了很多数据。然后利用数据更新我的策略,此时我成为1点的我。当我被更新后,理论上,1点的我再次与环境互动,收集数据,然后把我更新到2点,然后这样往复迭代。
- 但是如果我仍然想继续0点的我收集的数据来进行更新。因为这些数据是0点的我(而不是1点的我)所收集的。所以,我要对这些数据做一些重要性重采样,让这些数据看起来像是1点的我所收集的。当然这里仅仅是看起来像而已,所以我们要对这个“不像”的程度加以更新时的惩罚(KL)。
- 其中,更新的方式是:我收集到的每个数据序列,对序列中每个(s, a)的优势程度做评估,评估越好的动作,将来就又在s状态时,让a出现的概率加大。这里评估优势程度的方法,可以用数据后面的总折扣奖励来表示。另外,考虑引入基线的Tip,我们就又引入一个评价者小明,让他跟我们一起学习,他只学习每个状态的期望折扣奖励的平均期望。这样,我们评估(s, a)时,我们就可以吧小明对 s 的评估结果就是 s 状态后续能获得的折扣期望,也就是我们的基线。注意哈:优势函数中,前一半是实际数据中的折扣期望,后一半是估计的折扣期望(小明心中认为s应该得到的分数,即小明对s的期望奖励),如果你选取的动作得到的实际奖励比这个小明心中的奖励高,那小明为你打正分,认为可以提高这个动作的出现概率;如果选取的动作的实际得到的奖励比小明心中的期望还低,那小明为这个动作打负分,你应该减小这个动作的出现概率。这样,小明就成为了一个评判官。
- 当然,作为评判官,小明自身也要提高自己的知识文化水平,也要在数据中不断的学习打分技巧,这就是对Φ的更新了
