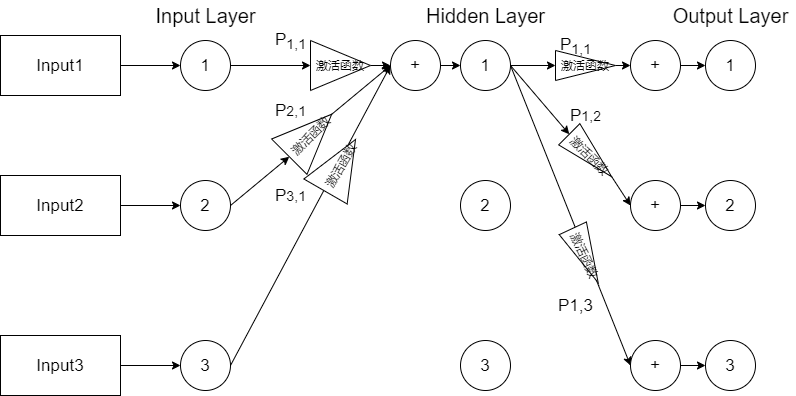
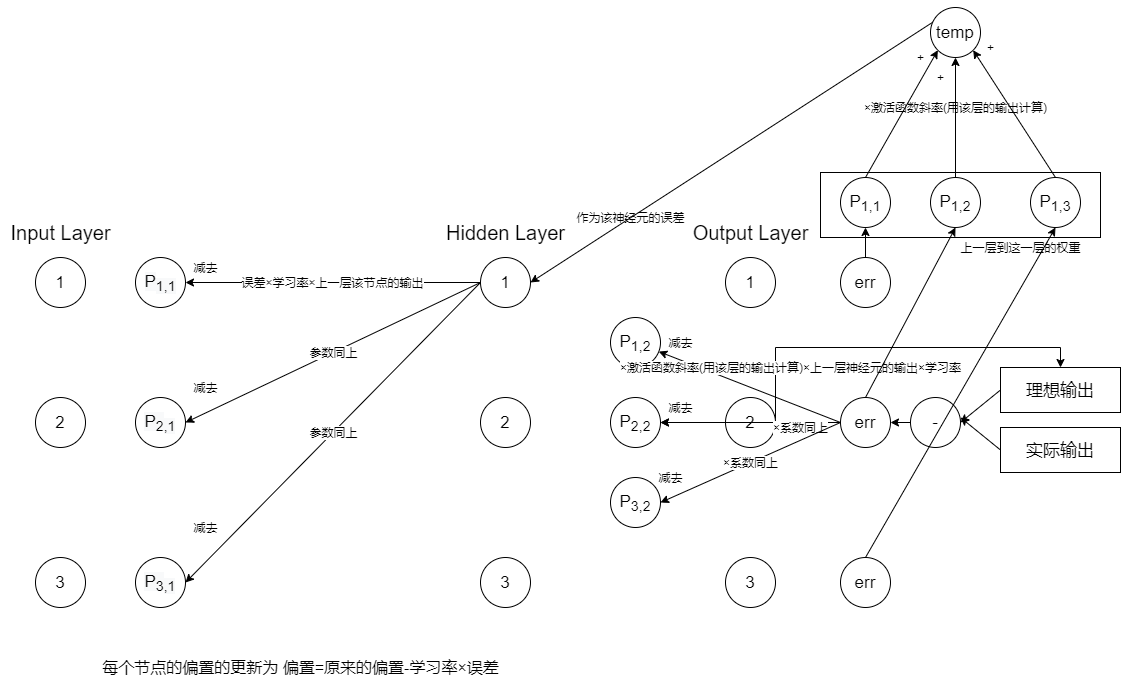
#include"BPNetWork.h"
#define LS network->lns
#define INNS network->ns[0]
#define INS(a) network->is[a-1]
#define TAS(a) network->ts[a-1]
#define OUTNS network->ns[LS-1]
#define NS(n) network->ns[n-1]
#define WF(n,a,p) network->las[n-2].ws[(p-1)+(a-1)*NS(n-1)]
#define BF(n,a) network->las[n-2].bs[a-1]
#define OF(n,a) network->las[n-2].os[a-1]
#define SF(n,a) network->las[n-2].ss[a-1]
#define LN network->ln
BPNetWork* BPCreate(int* nums, int len,double ln)
{
BPNetWork* network = malloc(sizeof(BPNetWork));
network->lns = len;
network->ns = malloc(len * sizeof(int));
network->ln = ln;
memcpy(network->ns, nums, len * sizeof(int));
network->is = malloc(nums[0] * sizeof(double));
network->las = malloc(sizeof(Layer) * (len - 1));
network->ts = malloc(sizeof(double) * nums[len - 1]);
srand(&network);
for (int p = 0; p < len - 1; p++) {
int lastnum = nums[p];
int num = nums[p + 1];
network->las[p].bs = malloc(sizeof(double) * num);
network->las[p].ws = malloc(sizeof(double) * num * lastnum);
network->las[p].os = malloc(sizeof(double) * num);
network->las[p].ss = malloc(sizeof(double) * num);
for (int pp = 0; pp < num; pp++) {
network->las[p].bs[pp] = rand() / 2.0 / RAND_MAX;
for (int ppp = 0; ppp < lastnum; ppp++) {
network->las[p].ws[ppp + pp * lastnum] = rand() / 2.0 / RAND_MAX;
}
}
}
return network;
}
void RunOnce(BPNetWork* network) {
for (int a = 1; a <= NS(2); a++) {
double net = 0;
double* o = &OF(2,a);
for (int aa = 1; aa <= INNS; aa++) {
net += INS(aa) * WF(2, a, aa);
}
*o = f(net + BF(2,a));
}
for (int n = 2; n <= LS-1; n++) {
for (int a = 1; a <= NS(n + 1); a++) {
double net = 0;
double* o = &OF(n+1,a);
for (int aa = 1; aa <= NS(n); aa++) {
double oo = OF(n, aa);
double* ww = &WF(n + 1, a, aa);
net += oo * (*ww);
}
*o = f(net + BF(n + 1, a));
}
}
}
void TrainOnce(BPNetWork* network) {
for (int a = 1; a <= OUTNS; a++) {
double* s = &SF(LS,a);
double* b = &BF(LS, a);
double o = OF(LS, a);
*s = (2.0 / OUTNS) * (o - TAS(a))* f_(o);
*b = *b - LN * (*s);
for (int aa = 1; aa <=NS(LS-1) ; aa++) {
double* w = &WF(LS, a, aa);
*w = *w - LN * (*s) * OF(LS-1, aa);
}
}
for (int a = LS-1; a > 2; a--) {
for (int n = 1; n <= NS(a); n++) {
double* s = &SF(a, n);
*s = 0;
double* b = &BF(a, n);
double o = OF(a, n);
for (int nn = 1; nn <= NS(a+1); nn++) {
double lw = WF(a + 1, nn, n);
double ls = SF(a + 1, nn);
*s += ls * lw * f_(o);
}
*b = *b - LN * (*s);
for (int nn = 1; nn <= NS(a - 1); nn++) {
double* w = &WF(a, n, nn);
*w = *w - LN * (*s) *OF(a - 1, nn);
}
}
}
for (int n = 1; n <= NS(2); n++) {
double* s = &SF(2, n);
*s = 0;
double* b = &BF(2, n);
double o = OF(2, n);
for (int nn = 1; nn <= NS(3); nn++) {
double lw = WF(3, nn, n);
double ls = SF(3, nn);
*s += ls * lw * f_(o);
}
*b = *b - LN * (*s);
for (int nn = 1; nn <= INNS; nn++) {
double* w = &WF(2, n, nn);
*w = *w - LN * (*s) * INS(nn);
}
}
}
void LoadIn(BPNetWork* network,double* input,double* putout) {
memcpy(network->is, input, INNS*sizeof(double));
memcpy(network->ts, putout, OUTNS*sizeof(double));
}
int main() {
int a[] = { 1,20,20,1 };
double in[1] = { 0.9 };
double in1[1] = { 0.1 };
double in2[1] = { 0.5 };
double out[1] = { 0.1 };
BPNetWork* network = BPCreate(a, 4, 0.5);
int c = 1000;
while (c--) {
LoadIn(network, in, out);
RunOnce(network);
TrainOnce(network);
LoadIn(network, in1, out);
RunOnce(network);
TrainOnce(network);
LoadIn(network, in2, out);
RunOnce(network);
TrainOnce(network);
}
double t[1] = { 0.7 };
double o[1] = { 0.2 };
LoadIn(network, t, o);
RunOnce(network);
printf("OK\n");
printf("%g\n", ETotal(network));
printf("%g", OF(4, 1));
return 0;
}
|