C标准IO函数使用笔记
文件读写
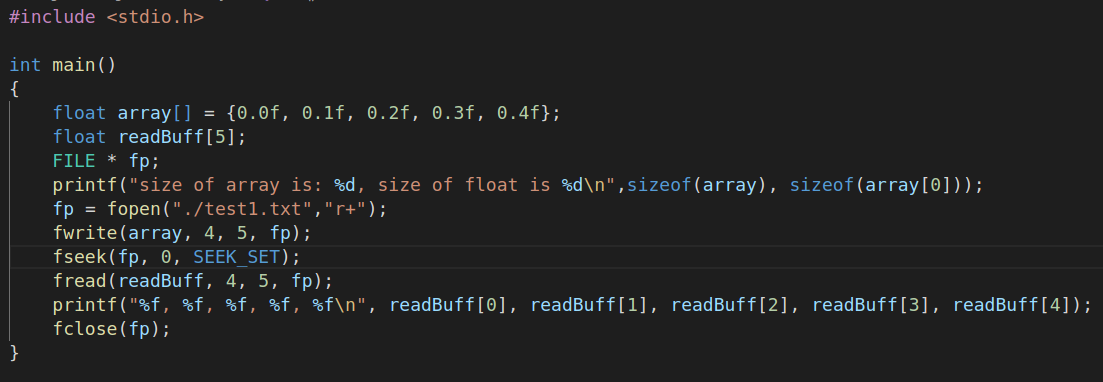
上面的函数实现了将一个每个单元大小为4个byte的浮点数存储在文件中,并且再原样读取回来的功能。
写文件和读文件的参数分别是单个单元的大小为4字节,总长度为5.下面看结果

测试可知,文件读写函数用的是同一个文件偏移量,也就是随着文件的写入而顺次增加的偏移量,假如文件读取之前不将偏移量移动回初始位置的话,会什么也读不出来
可见sizeof()函数读取数组的时候,读取的是数组的总空间大小而不是数组的元素个数。图上数组的读取结果是20,也就是5*4
同时还可以推测文件写入模式
r+的默认起始位置是0在上述函数中的
fwrite后面添加一个ftell()显示偏移量,可见 fwrite函数执行完毕的时候文件的偏移量自动增加到了20字节处
fwrite函数执行完毕的时候文件的偏移量自动增加到了20字节处
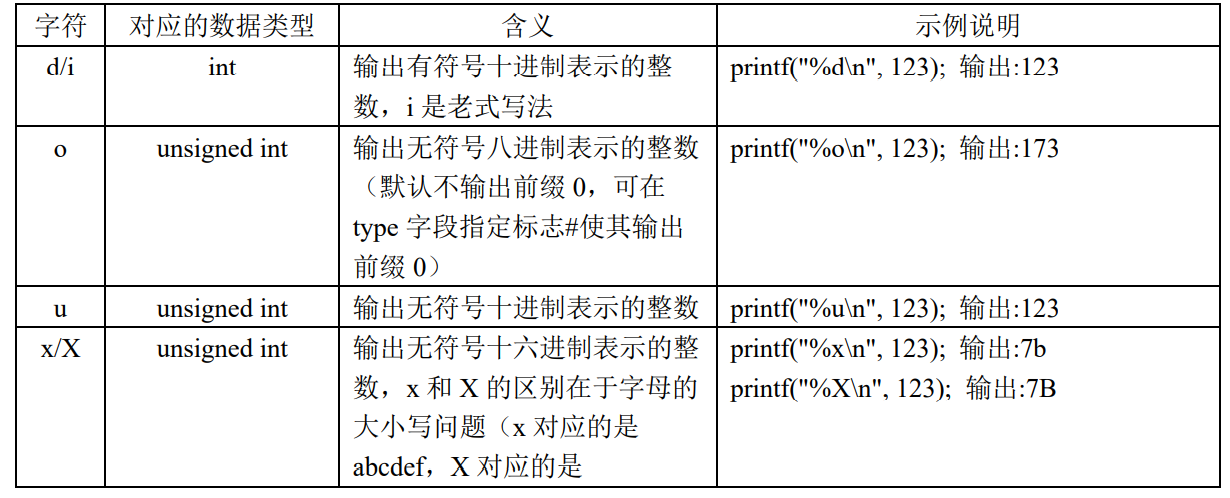
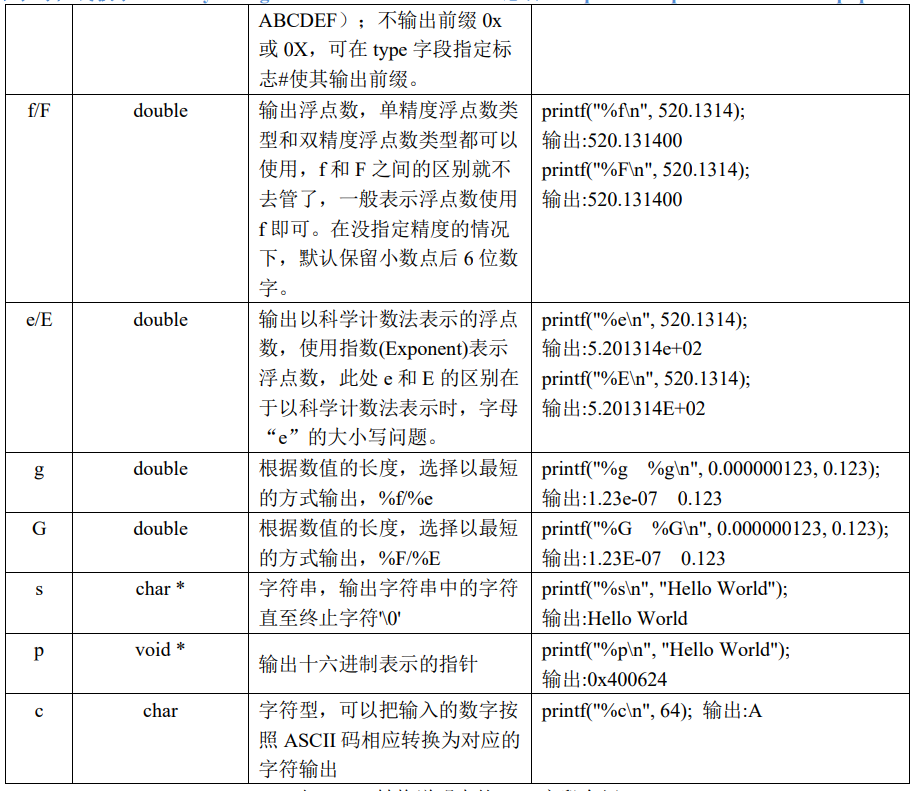
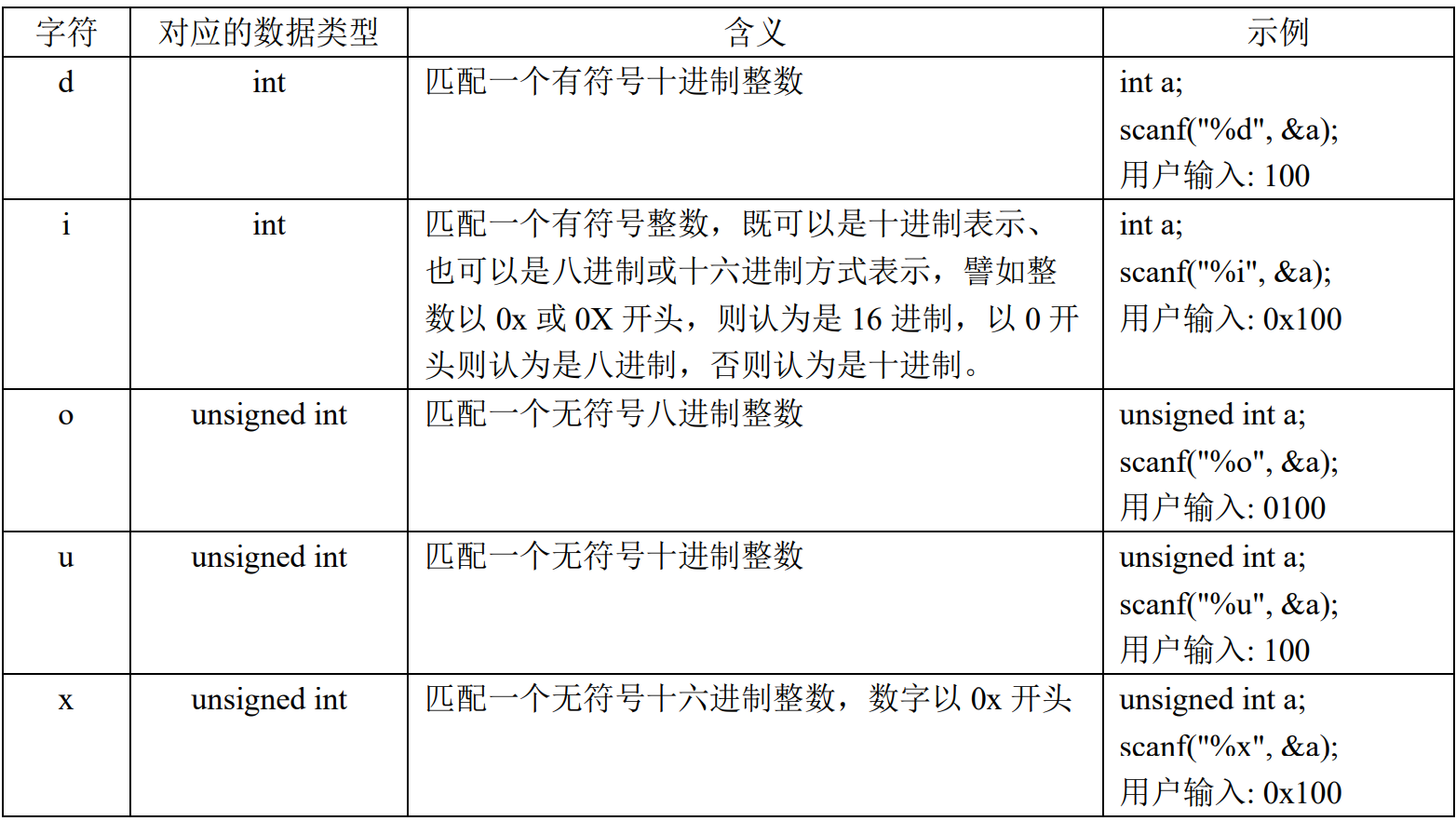
格式化文本函数的格式控制字符串
%[flags][width][.precision][length]type |
flags:标志,可包含 0 个或多个标志;
width:输出最小宽度,表示转换后输出字符串的最小宽度;
precision:精度,前面有一个点号” . “;
length:长度修饰符;
type:转换类型,指定待转换数据的类型。
type:
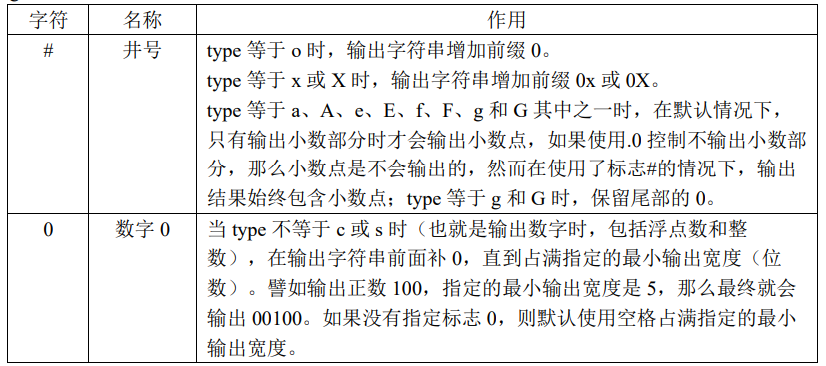
flags
width
- 最小的输出宽度,用十进制数来表示输出的最小位数,若实际的输出位数大于指定的输出的最小位数, 则以实际的位数进行输出,若实际的位数小于指定输出的最小位数,则可按照指定的 flags 标志补 0 或补空 格。

precision 精度
- 精度字段以点号” . “开头,后跟一个十进制正数


length
- 长度修饰符指明待转换数据的长度,因为 type 字段指定的的类型只有 int、unsigned int 以及 double 等 几种数据类型,但是 C 语言内置的数据类型不止这几种,譬如有 16bit 的 short、unsigned short,8bit 的 char、 unsigned char,也有 64bit 的 long long 等,为了能够区别不同长度的数据类型,于是乎,长度修饰符(length) 应运而生,成为转换说明的一部分。


示例
printf("%hd\n", 12345); //将数据以 short int 类型进行转换 |
格式化输入
|
可以看到,这 3 个格式化输入函数也是可变参函数,它们都有一个共同的参数 format,同样也称为格式 控制字符串,用于指定输入数据如何进行格式转换,与格式化输出函数中的 format 参数格式相似,但也有 所不同。
每个函数除了固定参数之外,还可携带 0 个或多个可变参数。
scanf()函数可将用户输入(标准输入)的数据进行格式化转换;fscanf()函数从 FILE 指针指定文件中读 取数据,并将数据进行格式化转换;sscanf()函数从参数 str 所指向的字符串中读取数据,并将数据进行格式 化转换。
scanf
int a, b, c; |
- 函数调用成功后,将返回成功匹配和分配的输入项的数量;如果较早匹配失败,则该数目可能小于所提 供的数目,甚至为零。发生错误则返回负值。
fscanf
- 注意,该函数的第一个参数可以是标准输入流,此时它的作用与scanf相同
int a, b, c; |
- 函数调用成功后,将返回成功匹配和分配的输入项的数量;如果较早匹配失败,则该数目可能小于所提供的数目,甚至为零。发生错误则返回负值。
sscanf
char *str = "5454 hello"; |
- 函数调用成功后,将返回成功匹配和分配的输入项的数量;如果较早匹配失败,则该数目可能小于所提 供的数目,甚至为零。发生错误则返回负值。
格式控制字符串
- 本小节的重点依然是这个 format 参数的格式,与格式化输出函数中的 format 参数格式、写法上比较相 似,但也有一些区别。format 字符串包含一个或多个转换说明,每一个转换说明都是以百分号”%”或者”%n$” 开头(n 是一个十进制数字),关于”%n$”这种开头的转换说明就不介绍了,实际上用的不多。
- 以%百分号开头的转换说明一般格式如下(
[]部分是可选的参数)
%[*][width][length]type |
- %后面可选择性添加星号
*或**字母m**,如果添加了星号*,格式化输入函数会按照转换说明的指示读取输 入,但是丢弃输入,意味着不需要对转换后的结果进行存储,所以也就不需要提供相应的指针参数。 - 如果添加了 m,它只能与%s、%c 以及%[一起使用,调用者无需分配相应的缓冲区来保存格式转换后的 数据,原因在于添加了 m,这些格式化输入函数内部会自动分配足够大小的缓冲区,并将缓冲区的地址值通 过与该格式转换相对应的指针参数返回出来,该指针参数应该是指向 char *变量的指针。随后,当不再需要 此缓冲区时,调用者应调用 free()函数来释放此缓冲区。
char *buf; |
width:最大字符宽度;
length:长度修饰符,与格式化输出函数的 format 参数中的 length 字段意义相同。
type:指定输入数据的类型。
type
width最大字符长度限制。
- 是一个十进制表示的整数,用于指定最大字符宽度,当达到此最大值或发现不匹配的字符时(以先发生 者为准),字符的读取将停止。大多数 type 类型会丢弃初始的空白字符,并且这些丢弃的字符不会计入最 大字符宽度。对于字符串转换来说,scanf()会在字符串末尾自动添加终止符”\0”,最大字符宽度中不包括此 终止符。
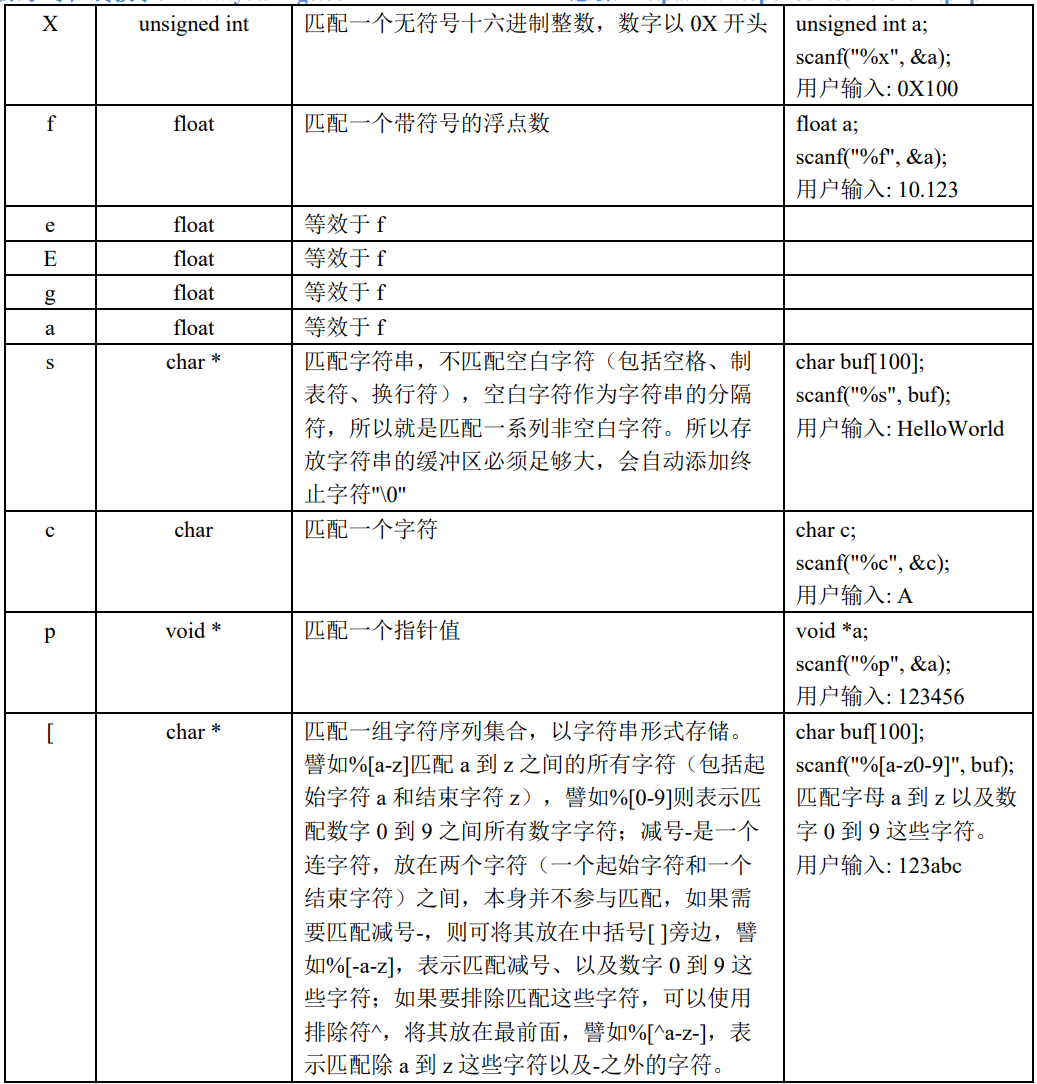
scanf("%4s", buf); //匹配字符串,字符串长度不超过 4 个字符 |
- 此时输入“abcdef”,存储的是“abcd”
- length数据长度修饰符
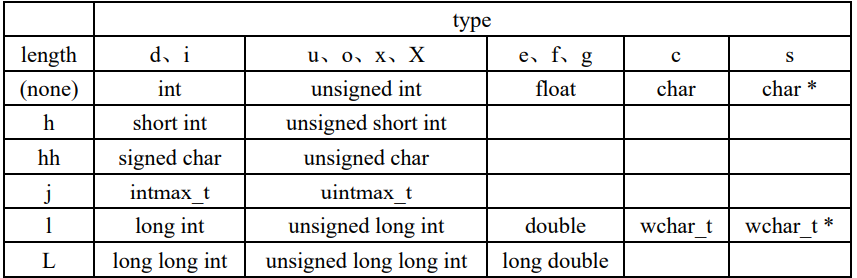
scanf("%hd", var); //匹配 short int 类型数据 |
使用例:
|
- 注意
[]里面的内容的写法,比如想一次性收取所有字母,使用[A-Za-z],连续写即可,数字写0-9,同 - 控制台测试输入

- 都能够正确接收到0.01,说明成功识别到了hello并且将其丢弃(因为指定了
*符号)
I/O缓冲
略,详见原子教程《I.MX6U嵌入式Linux C应用编程指南》
- 标准 I/O 所维护的 stdio 缓冲是用户空间 的缓冲区,当应用程序中通过标准 I/O 操作磁盘文件时,为了减少调用系统调用的次数,标准 I/O 函数会将 用户写入或读取文件的数据缓存在 stdio 缓冲区,然后再一次性将 stdio 缓冲区中缓存的数据通过调用系统 调用 I/O(文件 I/O)写入到文件 I/O 内核缓冲区或者拷贝到应用程序的 buf 中。
- 通过这样的优化操作,当操作磁盘文件时,在用户空间缓存大块数据以减少调用系统调用的次数,使得 效率、性能得到优化。使用标准 I/O 可以使编程者免于自行处理对数据的缓冲,无论是调用 write()写入数 据、还是调用 read()读取数据。
- 直接 I/O 方式效率、性能比较低,绝大部分应用程序不会使用直接 I/O 方式对文件进行 I/O 操作,通常 只在一些特殊的应用场合下才可能会使用,那我们可以使用直接 I/O 方式来测试磁盘设备的读写速率,这种 测试方式相比普通 I/O 方式就会更加准确。
文件描述符和FILE指针的转化
- 在应用程序中,在同一个文件上执行 I/O 操作时,还可以将文件 I/O(系统调用 I/O)与标准 I/O 混合使 用,这个时候我们就需要将文件描述符和 FILE 指针对象之间进行转换,此时可以借助于库函数
fdopen()、fileno()来完成。
|
对于 fileno()函数来说,根据传入的 FILE 指针得到整数文件描述符,通过返回值得到文件描述符,如果 转换错误将返回-1,并且会设置 errno 来指示错误原因。得到文件描述符之后,便可以使用诸如 read()、write()、 lseek()、fcntl()等文件 I/O 方式操作文件。
fdopen()函数与 fileno()功能相反,给定一个文件描述符,得到该文件对应的 FILE 指针,之后便可以使 用诸如 fread()、fwrite()等标准 I/O 方式操作文件了。参数 mode 与 fopen()函数中的 mode 参数含义相同如下表,若该参数与文件描述符 fd 的访问模式不一致,则会导致调用 fdopen()失败。

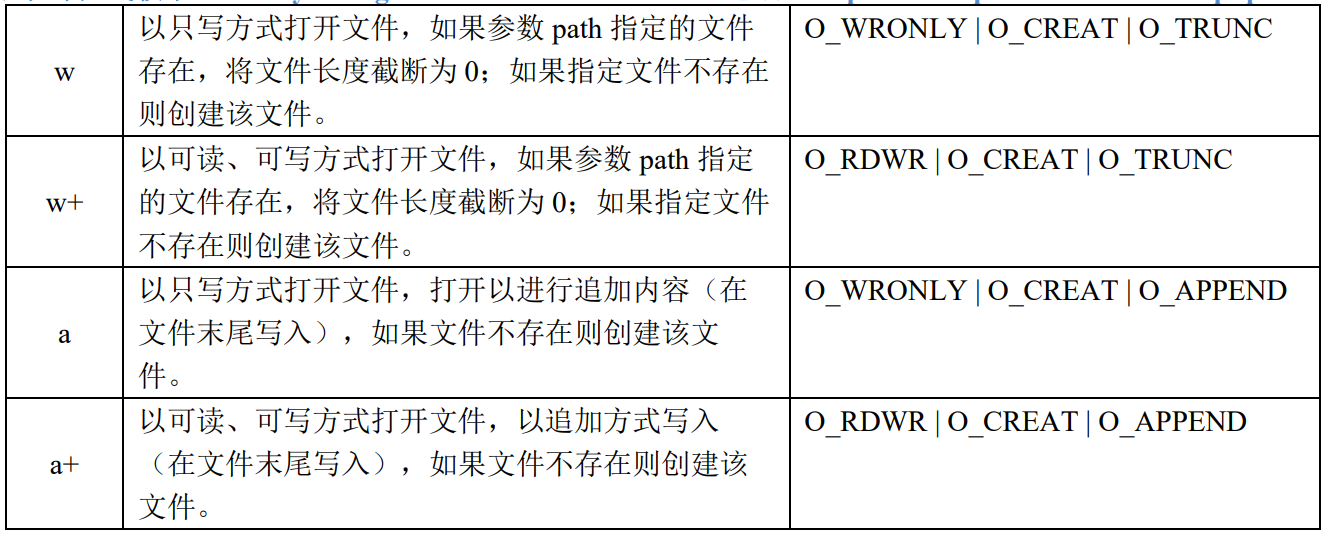
混用两种IO函数的时候的缓冲区问题
|
当混合使用文件 I/O 和标准 I/O 时,需要特别注意缓冲的问题,文件 I/O 会直接将数据写入到内核缓冲 区进行高速缓存,而标准 I/O 则会将数据写入到 stdio 缓冲区,之后再调用 write()将 stdio 缓冲区中的数据写 入到内核缓冲区。
执行结果你会发现,先输出了”write”字符串信息,接着再输出了”print”字符串信息